| İstatistik konuları ve daha fazlası yeni sitemize taşınmıştır. |
| Veri Bilimi ve Veri Analizi | İstatistik için tıklayınız. |
Yayılım ya da Değişkenlik Ölçüleri olarak da adlandırılan Dağılım Ölçüleri (measure of dispersion)1 veri birimlerinin genelinin ortalamadan ne kadar uzak ya da ortalamaya ne kadar yakın olduğunu gösteren temel ölçülerden biridir. Merkezî eğilim ölçülerinden olan aritmetik ortalama, mod ve medyan her zaman serinin heterojen ya da homojen dağıldığını göstermemektedir. Bu sebeple serinin dağılımı hakkında merkezî eğilim ölçülerine göre daha anlamlı sonuçlar veren standart sapma ve değişim katsayısı gibi dağılım ölçüleri kullanılır.

Yukarıdaki grafikte kişi başına günlük harcama tutarlarını gösteren iki gruba ait veriler dağılım grafiğinde gösterilmiştir. İki grubun da kişi başına günlük ortalama harcaması 100 TL olmasına rağmen kırmızı grubun standart sapması2 10 TL iken mavi grubun standart sapması 50 TL’dir. Bu sebeple iki grubun da aynı karakteristik özelliklere sahip olduğunu söyleyemeyiz. İki grubu birbiri ile karşılaştırmak için dağılım ölçülerinden yararlanırız.
| İstatistik konuları ve daha fazlası yeni sitemize taşınmıştır. |
| Veri Bilimi ve Veri Analizi | İstatistik için tıklayınız. |
Değişim Aralığı ya da Ranj (Range), en kolay anlaşılan dağılım ölçüsü olmakla birlikte uygulaması da en kolay yayılım ölçüsüdür. Aykırı değerlerden hemen etkilenir ve açık uçlu dağılımlar için hesaplanamaz.
R: Range, Değişim Aralığı, Xmax: Serinin en büyük değeri, Xmin: Serinin en küçük değeri
Excel’de değişim aralığını bulmak için =MAK()-MİN() formülünü kullanabiliriz.
Uygulama: Bir sınıftan seçilen 10 öğrencinin sınav notları aşağıda verilmiştir.
Notların değişim aralığını bulunuz.
Serinin en büyük değeri 90, en küçük değeri 40’tır. İki değer arasındaki mesafe (range), değişim aralığını vermektedir.
| İstatistik konuları ve daha fazlası yeni sitemize taşınmıştır. |
| Veri Bilimi ve Veri Analizi | İstatistik için tıklayınız. |
Kartiller Arası Fark (Interquartile Range, IQR)3 ya da Çeyrekler Arası Açıklığı serinin %75. dilimine denk gelen Q3 kartili ve %25. dilime denk gelen Q1 kartili arasındaki farkı belirtmektedir.

Kartiller Arası Fark (IQR) çoğunlukla kutu grafiklerinde4 yoğun olarak kullanılmakla birlikte olasılık yoğunluk fonkisyonu ve standart normal dağılım grafiklerinde dağılımın %50’sini oluşturmaktadır.
Excel’de Kartiller Arası Fark almak için =DÖRTTEBİRLİK(seri;3)-DÖRTTEBİRLİK(seri;1) hesaplamasını yapabiliriz.
Uygulama: X1 = 12, 14, 14, 16, 18, 18, 18, 18, 18, 20, 24 serisinin kartiller arası farkını (IQR'ını) bulunuz.
n: 11’dir. Gözlem sayısı tek sayı olduğu için
Ortalama Mutlak Sapma (Mean Absolute Deviation, MAD), verilerin ortalamadan sapmalarının mutlak değerlerinin ortalamasıdır. Bu dağılım ölçüsünde her gözlemin sapmasına eşit ağırlık tanınır ve standart sapma kadar aykırı değerlerden etkilenmez. Kimi durumlarda ortalama yerine medyan da kullanılabilmektedir.
m: Sınıf Orta Sayısı, f: Frekans
Excel’de ortalama mutlak sapmanın formülü bulunmamaktadır. Buna rağmen mutlak değerleri hesaplarken =MUTLAK() formülünü kullanabiliriz.
Uygulama: Bir sınıftan seçilen 10 öğrencinin sınav notları aşağıda verilmiştir.
Notların ortalama mutlak sapmasını (MAD’ini) bulunuz.
Öncelikle aritmetik ortalamayı buluruz.
Ardından ortalama mutlak sapmayı (MAD’i) hesaplarız.
Uygulama: Bir sınıftaki tüm öğrencilerin boy uzunlukları tabloda listelenmiştir.
| Boy Uzunluğu | Öğrenci Sayısı |
|---|---|
| 155 cm | 1 |
| 160 cm | 2 |
| 165 cm | 7 |
| 170 cm | 16 |
| 175 cm | 18 |
| 180 cm | 6 |
| 185 cm | 4 |
| 190 cm | 1 |
| Toplam (Σ) | 55 |
Boy uzunluklarının ortalama mutlak sapmasını (MAD’ini) bulunuz.
Öncelikle aritmetik ortalamayı buluruz.
| Boy Uzunluğu (Xi) | Öğrenci Sayısı (fi) | Xifi |
|---|---|---|
| 155 cm | 1 | 155 |
| 160 cm | 2 | 320 |
| 165 cm | 7 | 1155 |
| 170 cm | 16 | 2720 |
| 175 cm | 18 | 3150 |
| 180 cm | 6 | 1080 |
| 185 cm | 4 | 740 |
| 190 cm | 1 | 190 |
| Toplam (Σ) | 55 | 9510 |
Ardından ortalama mutlak sapmayı (MAD’i) hesaplarız.
| Boy Uzunluğu (Xi) | Öğrenci Sayısı (fi) | fi|Xi-µ| |
|---|---|---|
| 155 cm | 1 | 1|155-173| |
| 160 cm | 2 | 2|160-173| |
| 165 cm | 7 | 7|165-173| |
| 170 cm | 16 | 16|170-173| |
| 175 cm | 18 | 18|175-173| |
| 180 cm | 6 | 6|180-173| |
| 185 cm | 4 | 4|185-173| |
| 190 cm | 1 | 1|190-173| |
| Toplam (Σ) | 55 | 351 |
Uygulama: Bir sınıftaki tüm öğrencilerin boy uzunlukları tabloda listelenmiştir.
| Boy Uzunluğu | Öğrenci Sayısı |
|---|---|
| 150 – 159 cm | 4 |
| 160 – 169 cm | 12 |
| 170 – 179 cm | 36 |
| 180 – 189 cm | 8 |
| 190 – 200 cm | 2 |
| Toplam (Σ) | 62 |
Boy uzunluklarının ortalama mutlak sapmasını (MAD’ini) bulunuz.
Öncelikle ortalamayı buluruz.
| Boy Uzunluğu | mi | Öğrenci Sayısı (fi) | mifi |
|---|---|---|---|
| 150 – 159 cm | 155 cm | 4 | 620 |
| 160 – 169 cm | 165 cm | 12 | 1980 |
| 170 – 179 cm | 175 cm | 36 | 6300 |
| 180 – 189 cm | 185 cm | 8 | 1480 |
| 190 – 200 cm | 195 cm | 2 | 390 |
| Toplam (Σ) | 62 | 10770 |
Ardından ortalama mutlak sapmayı (MAD’i) hesaplarız.
| Boy Uzunluğu | mi | Öğrenci Sayısı (fi) | fi|mi-µ| |
|---|---|---|---|
| 150 – 159 cm | 155 cm | 4 | 4|155 – 174| |
| 160 – 169 cm | 165 cm | 12 | 12|165 – 174| |
| 170 – 179 cm | 175 | 36 | 36|175 – 174| |
| 180 – 189 cm | 185 cm | 8 | 8|185 – 174| |
| 190 – 200 cm | 195 cm | 2 | 2|195 – 174| |
| Toplam (Σ) | 62 | 350 |
Standart Sapma (Standart Deviation, SD, STDEV) gözlem değerlerinin aritmetik ortalamadan sapmalarının kareli ortalamasıdır. Standart sapmanın karesi ise Varyans (Variance, VAR) olarak adlandırılır.
En çok kullanılan ve en önemli dağılım ölçüsüdür. Açık uçlu dağılımlar için hesaplanamaz.
Anakütle için σ (küçük sigma), örneklem için s notasyonu ile gösterilir.
m: Sınıf Orta Sayısı, f: Frekans, σ: Anakütle Standart Sapması, s: Örneklem Standart Sapması
Formüller biraz daha detaylı yazılırsa…

Normal dağılım grafikleri5 standart sapma ile hesaplanmaktadır. Ortalamanın 0 (sıfır) alınması durumunda “standart normal dağılım” olarak adlandırılmaktadır. Normal dağılımda 68-95-99.7 Kuralı adlı verilen özel bir kural geçerlidir. Bu kurala göre ortalamadan ±1σ (artı eksi 1 standart sapma) uzaklığa kadar olan alan, tüm olasılıkların %68.2’sini, ±2σ uzaklığa kadar olan alan %95.4’ünü, ±3σ uzaklığa kadar olan alan ise %99.6’sını kapsamaktadır. İlerleyen konularda normal dağılım detaylıca anlatılacak olup standart sapmanın tüm dağılım ölçüleri içerisinde neden en önemli ölçü olduğu dağılımı grafiklerinden de anlaşılabilir.
Varyans, standart sapmanın karesi olmakla birlikte anakütle için σ2, örneklem içinse s2 notasyonu ile gösterilir. Basit serilerde varyansı formülize etmek istersek
şeklinde gösterebiliriz. Örneklem hacminin 40’tan küçük olduğu serilerde n yerine (n-1) kullanılmalıdır.6
n ≤ 40 ise standart sapmanın formülü şu şekilde olmaktadır:
Excel’de anakütle standart sapmasını hesaplamak için =STDSAPMA.P(), örneklem standart sapmasını hesaplamak içinse =STDSAPMA.S() formüllerini kullanabiliriz.
Uygulama: Bir sınıftan seçilen 10 öğrencinin sınav notları aşağıda verilmiştir.
Notların standart sapmasını bulunuz.
Standart sapmayı bulmak için öncelikle ortalamayı bulmalıyız.
Standart sapmayı hesapladığımızda
sonucunu elde ederiz. Dikkat ederseniz gözlem değerlerimiz 40’tan küçüktür. n ≤ 40 olduğu için payda kısmını n yerine n – 1 aldık.
Uygulama: Bir sınıftaki tüm öğrencilerin boy uzunlukları tabloda listelenmiştir.
| Boy Uzunluğu | Öğrenci Sayısı |
|---|---|
| 155 cm | 1 |
| 160 cm | 2 |
| 165 cm | 7 |
| 170 cm | 16 |
| 175 cm | 18 |
| 180 cm | 6 |
| 185 cm | 4 |
| 190 cm | 1 |
| Toplam (Σ) | 55 |
Boy uzunluklarının standart sapmasını bulunuz.
Öncelikle aritmetik ortalamayı buluruz.
| Boy Uzunluğu (Xi) | Öğrenci Sayısı (fi) | Xifi |
|---|---|---|
| 155 cm | 1 | 155 |
| 160 cm | 2 | 320 |
| 165 cm | 7 | 1155 |
| 170 cm | 16 | 2720 |
| 175 cm | 18 | 3150 |
| 180 cm | 6 | 1080 |
| 185 cm | 4 | 740 |
| 190 cm | 1 | 190 |
| Toplam (Σ) | 55 | 9510 |
Ardından standart sapmayı hesaplarız.
| Boy Uzunluğu (Xi) | Öğrenci Sayısı (fi) | fi(Xi-µ)2 |
|---|---|---|
| 155 cm | 1 | 1(155-173)2 |
| 160 cm | 2 | 2(160-173)2 |
| 165 cm | 7 | 7(165-173)2 |
| 170 cm | 16 | 16(170-173)2 |
| 175 cm | 18 | 18(175-173)2 |
| 180 cm | 6 | 6(180-173)2 |
| 185 cm | 4 | 4(185-173)2 |
| 190 cm | 1 | 1(190-173)2 |
| Toplam (Σ) | 55 | 2485 |
Uygulama: Bir sınıftaki tüm öğrencilerin boy uzunlukları tabloda listelenmiştir.
| Boy Uzunluğu | Öğrenci Sayısı |
|---|---|
| 150 – 159 cm | 4 |
| 160 – 169 cm | 12 |
| 170 – 179 cm | 36 |
| 180 – 189 cm | 8 |
| 190 – 200 cm | 2 |
| Toplam (Σ) | 62 |
Boy uzunluklarının standart sapmasını bulunuz.
Öncelikle ortalamayı buluruz.
| Boy Uzunluğu | mi | Öğrenci Sayısı (fi) | mifi |
|---|---|---|---|
| 150 – 159 cm | 155 cm | 4 | 620 |
| 160 – 169 cm | 165 cm | 12 | 1980 |
| 170 – 179 cm | 175 cm | 36 | 6300 |
| 180 – 189 cm | 185 cm | 8 | 1480 |
| 190 – 200 cm | 195 cm | 2 | 390 |
| Toplam (Σ) | 62 | 10770 |
mi sınıf orta sayısını belirtmektedir. (150 + 160) / 2 = 155 cm
Ardından standart sapmayı hesaplarız.
| Boy Uzunluğu | mi | Öğrenci Sayısı (fi) | fi(mi-µ)2 |
|---|---|---|---|
| 150 – 159 cm | 155 cm | 4 | 4(155 – 174)2 |
| 160 – 169 cm | 165 cm | 12 | 12(165 – 174)2 |
| 170 – 179 cm | 175 | 36 | 36(175 – 174)2 |
| 180 – 189 cm | 185 cm | 8 | 8(185 – 174)2 |
| 190 – 200 cm | 195 cm | 2 | 2(195 – 174)2 |
| Toplam (Σ) | 62 | 4302 |
| İstatistik konuları ve daha fazlası yeni sitemize taşınmıştır. |
| Veri Bilimi ve Veri Analizi | İstatistik için tıklayınız. |
Düzeltilmiş Standart Sapma ya da Sheppard Düzeltmesi (Sheppard’s Correction) sınıflandırılmış (gruplandırılmış) serilerde standart sapmanın hatalı hesaplanması sonucu William Fleetwood Sheppard7 tarafından geliştirilen standart sapmadır.
σ*: Sheppard Düzeltmesi (Düzeltilmiş Standart Sapma), c: Sınıf Aralığı
Uygulama: Bir önceki örneğimizde standart sapmayı 8.3299 (8.33) bulmuştuk. Sınıf aralığı (c) 10’dur.
Düzeltilmiş standart sapmayı aşağıdaki gibi hesaplarız.
Sheppard düzeltmesi yapılabilmesi için serinin normal ya da normale yakın dağılması, frekansların büyük ve serinin iki ucunun da asimptotik sıfıra yaklaşması gerekmektedir.
Standart sapmadan farklı olarak Standart Hata (Standart Error, SE)8 aynı anakütleden seçilen örneklemlerin standart sapmalarını karşılaştıran ölçü birimidir. Standart hata ne kadar küçükse anakütleye ait tahmin değerlerinin o kadar isabetli olduğu söylenebilir.
Uygulama: 4000 birimlik anakütlenin standart sapması 8.42, bu anakütleden seçilen 40 birimlik örneklemin standart sapması ise 6.43’tür. Anakütle ve örneklem standart hatalarını karşılaştırınız.
Örneklem standart hatası (1.02), anakütle standart hatasından (0.13) çok büyük olduğu için seçilen örneklem uygun bir örneklem değildir.
Değişim Katsayısı ya da Varyasyon Katsayısı (Coefficient of Variation, CV) bir serinin standart sapmasının aritmetik ortalamasına bölünüp 100 ile çarpılmasıyla elde edilir.
Uygulama: Aşağıda iki farklı semtin kira fiyatları listelenmiştir. Hangi semtin kira fiyatları daha ucuzdur?
| A Semti | B Semti |
|---|---|
| 4000 | 2600 |
| 4000 | 2800 |
| 4200 | 3000 |
| 4400 | 3200 |
| 4400 | 3200 |
| 4500 | 3400 |
| 4500 | 3500 |
| 4500 | 3500 |
| 4800 | 3600 |
| 5000 | 24000 |
İki semtin kira fiyatı ortalamaları ve standart sapmaları aşağıdaki gibidir:
A Semti Ort=4430 | s=316.40
B Semti Ort=5280 | s=6585.47
Verilere baktığımızda A semtinde kiraların B semtine göre daha yüksek olduğu görülmesine rağmen ortalamalar yanıltıcıdır. Bunun sebebi B semtinde 24000 TL gibi aykırı değere sahip bir kiranın olmasıdır. Bu sebeple değişim katsayılarını kullanmalıyız.
A semtinin değişim katsayısı (7.14), B semtine göre (124.72) daha düşük olduğu için A semtinde kira fiyatları daha homojen dağılmıştır sonucuna varılabilir. B semtindeki aykırı değer, seriden çıkarıldığında B semtinin varyasyon katsayısı
hesaplanacaktır. Bu şekilde B semtinde ortalama kiraların (3200) A semtine göre (4430) daha ucuz olduğu sonucuna varılabilir.
| İstatistik konuları ve daha fazlası yeni sitemize taşınmıştır. |
| Veri Bilimi ve Veri Analizi | İstatistik için tıklayınız. |
SPSS'te çok hızlı bir şekilde değişim aralığı, standart sapma, varyans ve standart hata değerleri hesaplanabilir.
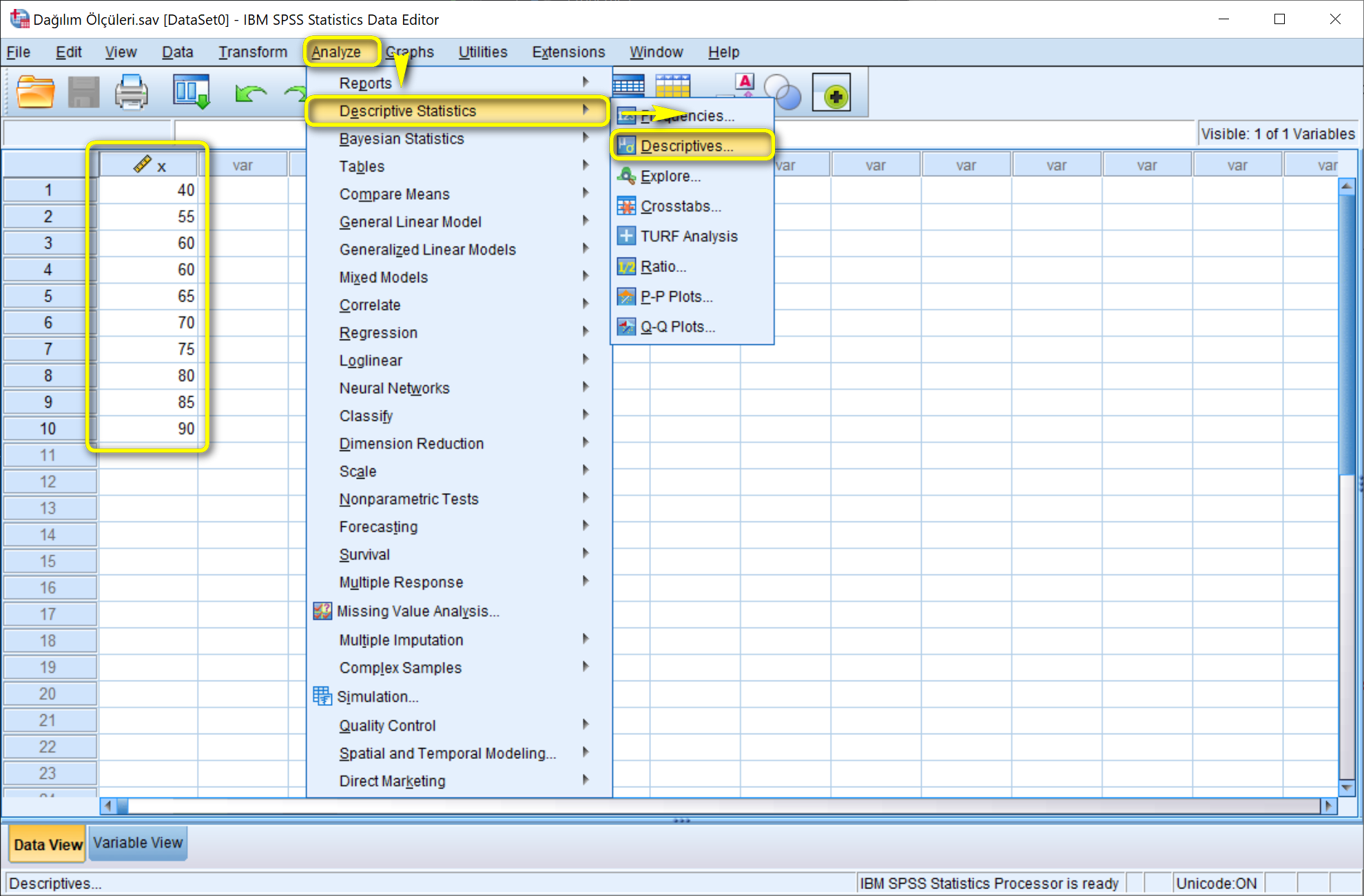
Analyze > Descrpitive Statistics > Descriptives... yolu izlenir.

Descriptives penceresinde ilgili değişken Variable(s) alanına aktarılır ve ardından Options...'a tıklanır.
Açılan Descrpitives: Options penceresinde ilgili dağılım ölçüleri seçilir ve Continue'ya tıklanıldıktan sonra Descriptives penceresinde OK'a tıklanır.
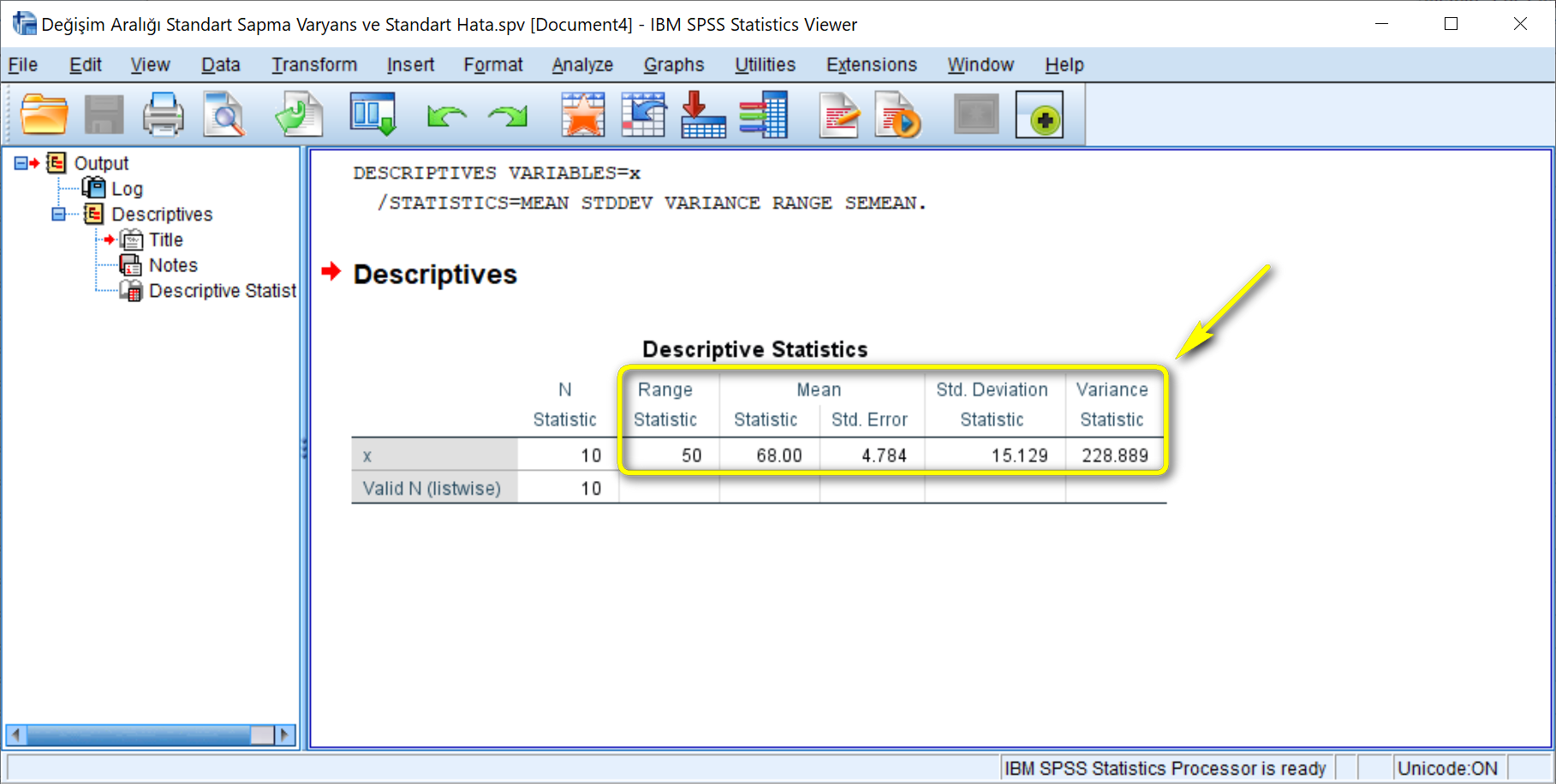
Sonuçlar Output (Çıktı) penceresinde görseldeki gibi listelenecektir.
SPSS'te değişim aralığı, standart sapma, varyans ve kartilleri arası farkı hesaplamak için aşağıdaki adımlar uygulanır.

Analyze > Descrpitive Statistics > Explore... yolu izlenir.
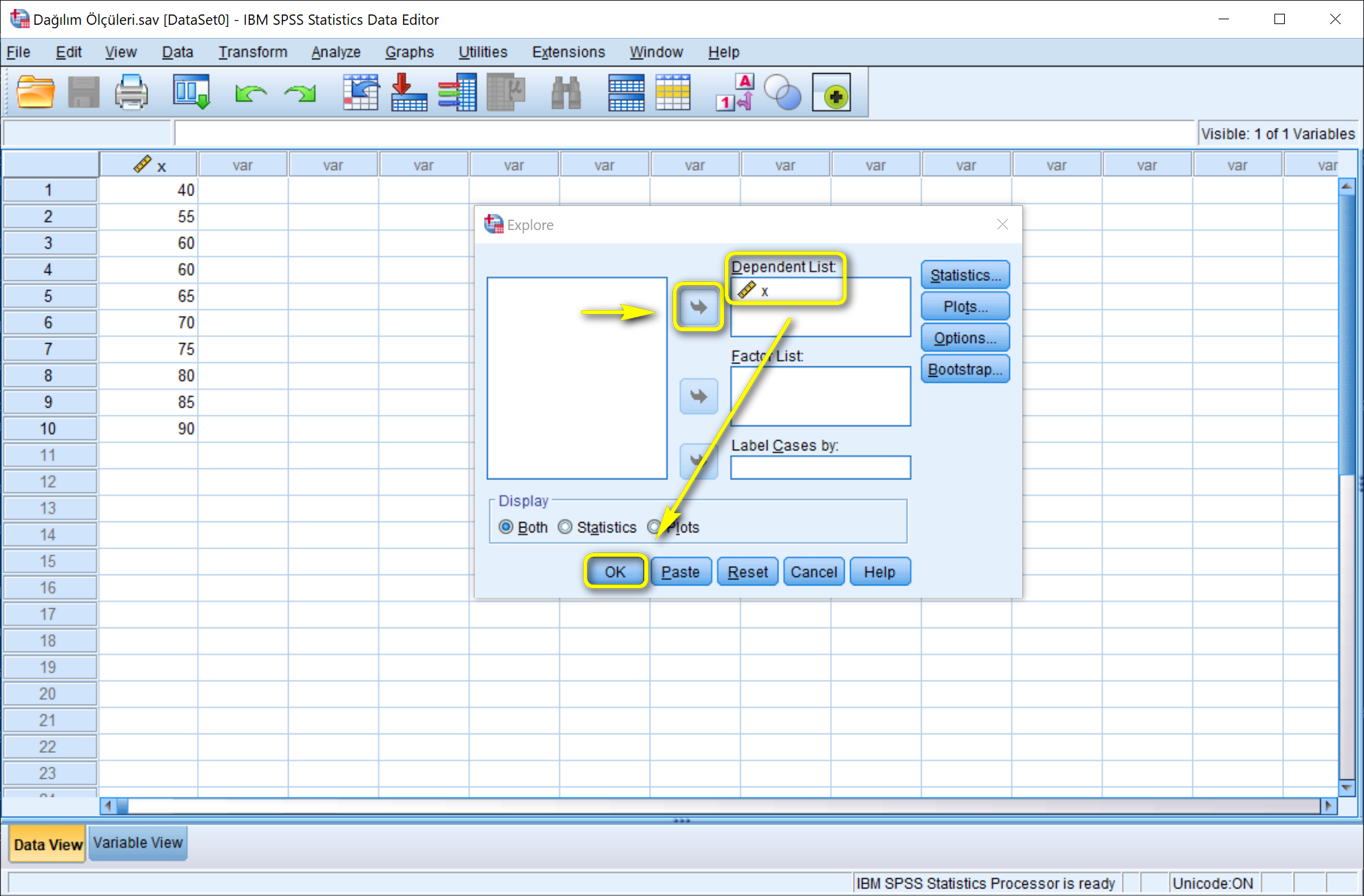
Açılan Explore penceresinde x değişkeni Dependent List alanına aktarılır ve herhangi bir değişiklik yapılmadan OK'a tıklanır.

Output penceresinde ilgili dağılım ölçüleri görülebilir. Interquartile Range (IQR) kartiller arası farkı belirtmektedir.
Kutu Diyagramı (Box Plot yada Boxplot) seri karşılaştırmalarında en sık kullanılan istatistik göstergelerinden biridir.

Öncelikle Q1, Q2 (medyan) ve Q3 kartilleri bulunur. IQR (Kartiller Arası Fark) Q3 ve Q1 kartillerinin farkı ile hesaplanır. Serinin minimum değeri Q1 kartilinden 1.5 IQR'ın çıkarılmasıyla, maksimum değeri ise Q3 kartiline 1.5 IQR eklenmesiyle bulunur. Minimum ve maksimum dışında kalan tüm değerler aykırı değer (outlier) olarak adlandırılır.
Uygulama: x = 2, 22, 24, 24, 26, 28, 28, 28, 30, 98, 122 serisinin kutu diyagramını çiziniz.
Kutu diyagramını çizebilmek için Q1, Q2 ve Q3 değerlerini bulmamız yeterlidir.
n: 11’dir. Gözlem sayısı tek sayı olduğu için
Q1 ve Q3 kartilleri bulunduktan sonra IQR (Kartiller Arası Fark) hesaplanır.
Son olarak Min ve Max değerlerinin hesaplanması yeterlidir.

Bulunan değerler diyagramın üzerine yerleştirilirse kutu diyagramı (boxplot) oluşacaktır. Diyagramdan da görüleceği üzere 2, 98 ve 122 değerleri aykırı değerlerdir. Bu değerler aynı zamanda seride yaklaşık %99 oranda normal dağılan değerlerin dışında yer almaktadır. Bu yüzden aykırı değer olarak adlandırılır.

Kutu diyagramları çoğunlukla seri karşılaştırmalarında kullanılır. Serilerin birbirlerinden farkını ayırt etmek için kullanılabilecek en iyi veri görselleştirme uygulamalarından biridir. Diyagramlar yatay çizilebileceği gibi yukarıdaki örnekte olduğu gibi dikey de çizilebilmektedir.
SPSS'te kutu diyagramı (boxplot) çizmek oldukça basittir.

Seri değerleri girildikten sonra menüden Graphs > Legacy Dialogs > Boxplot... yolu izlenir.

Simple seçilir. Tek bir serinin kutu diyagramı çizilmek isteniyorsa "Summaries of seperate variables" seçimi yapılır ve Define'a tıklanır.

Değişken Boxes Represent alanına aktarılır ve OK'a tıklanır.

Kutu diyagramı görseldeki gibi oluşturulacaktır.
Uygulama: Bir sınıftan seçilen 8 öğrencinin sınav notları aşağıda verilmiştir.
Serinin Değişim Aralığı'nı (Range'ini) bulunuz.
Yanıt: Değişim aralığını bulmak için seriden maksimum ve minimum değerleri çıkarmak yeterlidir.
Değişim Aralığı (Range) 35 bulunur.
Uygulama: Aşağıda 9 birimden oluşan seri verilmiştir.
Serinin Kartiller Arası Fark'ını (IQR'ını) bulunuz.
Yanıt: Kartiller Arası Farkı bulabilmek için Q1 ve Q3 kartillerini bulmamız yeterlidir.
Q3 ve Q1 arasındaki fark Kartiller Arası Fark'ı verecektir.
Kartiller Arası Fark 12 bulunur.
Uygulama: Aşağıda 5 değerden oluşan bir seri verilmiştir.
Serinin standart sapmasını bulunuz.
Yanıt: Standart sapmayı bulmak için öncelikle ortalamayı bulmalıyız.
Standart sapmayı hesapladığımızda
6 olarak buluruz. Dikkat ederseniz gözlem değerlerimiz 40’tan küçüktür. n ≤ 40 olduğu için payda kısmını n yerine n – 1 aldık.
Uygulama: Aşağıda 5 değerden oluşan bir seri verilmiştir.
Serinin standart sapmasını bulunuz.
Yanıt: Aslında bu soruda hesap yapmamıza bile gerek yok. Serideki tüm değerler birbirine eşitse serinin standart sapması daima 0 (sıfırdır).
Yine de bunu kanıtlamak istersek öncelikle ortalamayı bulmakla işe başlamalıyız.
Standart sapmayı hesapladığımızda
Görüleceği üzere standart sapma sıfırdır. Standart sapma değerlerin ortalamadan uzaklıklarının ölçüsüdür. Serideki hiçbir değer ortalamadan uzaklaşmamıştır. Bu sebeple standart sapma 0 bulunmuştur.
Uygulama: Aynı sayıda öğrenciden oluşan iki farklı sınıfın sınav puanlarına ait ortalama ve standart sapma değerleri aşağıda listelenmiştir.
Hangi sınıftaki notlar daha homojen dağılmıştır?
Yanıt: İki seri arasında homojenlik karşılaştırması yapılmak isteniyorsa daima Değişim Katsayısından (Varyasyon Katsayısından) faydalanırız.
A sınıfının Değişim Katsayısı (CV'si) sıfıra daha yakın olduğu için A sınıfındaki notlar B sınıfına göre daha homojen dağılmıştır diyebiliriz.
| İstatistik konuları ve daha fazlası yeni sitemize taşınmıştır. |
| Veri Bilimi ve Veri Analizi | İstatistik için tıklayınız. |
| Navigasyon | ||
| <<< Önceki Konu | İçindekiler | Sonraki Konu >>> |
Footnotes
-
Statistical Dispersion olarak da bilinir. ↩
-
Standart sapma kavramına birazdan değinilecektir. ↩
-
IQR için yabancı kaynaklarda midspread, middle 50%, H‑spread terimleri de kullanılmaktadır. ↩
-
Boxplot ↩
-
Normal distribution diagram ↩
-
Kimi kaynaklarda 30’dan küçük olması şartı aranmaktadır. ↩
-
20 Kasım 1863 – 12 Ekim 1936 tarihleri arasında yaşayan Avustralyalı – İngiliz istatistikçi ↩
-
IBM SPSS Statistics’te standart sapma ile karışmaması için “Standart Error of The Mean” (SEM) terimi kullanılmaktadır. ↩