本项目运用python复现Widar2、Widar3的开源代码(MATLAB),并有所区别。
This project aims to use python to repeat and verify the open-source MATLAB codes of Widar2 and Widar3. There are some differences to the MATLAB codes.
[1] Qian, Kun, et al. "Widar2. 0: Passive human tracking with a single wi-fi link." Proceedings of the 16th Annual International Conference on Mobile Systems, Applications, and Services. 2018.
[2] Zheng, Yue, et al. "Zero-effort cross-domain gesture recognition with Wi-Fi." Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services. 2019.
Zheng Yang 主页: http://tns.thss.tsinghua.edu.cn/~yangzheng/
WIDAR2: http://tns.thss.tsinghua.edu.cn/wifiradar/index_chi.html#feature
WIDAR3: http://tns.thss.tsinghua.edu.cn/widar3.0/
https://blog.csdn.net/u014645508/article/details/81359409
http://dhalperi.github.io/linux-80211n-csitool/
https://wands.sg/research/wifi/AtherosCSI/#Overview
数据采集工具csi_tool采集数据并保存为后缀.dat的数据文件,在csi_tool中提供一个c语言函数解析此文件。阅读了c语言的解析代码后发现,数据文件的组织方法与计网中数据十分相似,但略有不同。
总体上,整个文件仅由n个bfee组成,巧了,数据文件中应当包含有n个采样信息,这个bfee的意义不言而喻,就是和采样一一对应。
bfee:

bfee的数据结构如上图所示。
前两字节是field_len,之后一字节是code,再之后便是可变长度的field。field_len等于code+field的字长。
当code为187时,表示field中是信道信息;不是187时,表示field中是其他信息。
我们关心的是信道信息,其他信息不解析,跳过该bfee即可。
field:
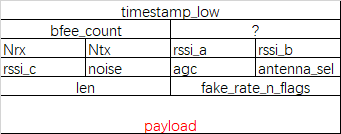
若code等于187,field有如上图数据格式。
到这里你一定感觉很熟悉了。
field分为头部和有效载荷(payload)两部分。头部有20字节的固定长度,有效载荷是个可变长度,字长为len。
头部各字段的数据类型和意义如下表:

可以见得,头部中包含了主要的信道信息。
而其中最重要的csi矩阵,分为30个subc,保存在有效载荷中。
分别对应30个子载波。
subc的结构如下表所示:

复数的结构:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
每个subc的开始会有3位的非数据部分,因此subc的长度不是字节(8位)的整数倍,这将导致subc这部分的解析需要按比特操作,增加我解析工作的复杂度。
到这里,整个文件的数据结构都清楚了,开始试着用python来解析run-lxx.dat这个文件。
示例:
import numpy as np
from Bfee import Bfee
from get_scale_csi import get_scale_csi
if __name__ == '__main__':
bfee = Bfee.from_file("csi.dat", model_name_encode="gb2312")
for i in range(len(bfee.all_csi)):
csi = get_scale_csi(bfee.dicts[i])
print(csi[:,:,i])方法的返回两种结果:
bfee.dicts字段等同于read_bfee_file() 函数的返回的结果,适用于原来的处理步骤。
bfee.all_csi字段是所有csi矩阵的列表,可以直接转化成numpy数组,用来弥补字典性能低下的问题。
两个长度一样。
正确的matlab解析步骤应该是:
1.从文件将头部信息和csi矩阵读取到字典,即read_bfee_file()
2.依次从字典中取出标准化CSI,即get_scale_csi()
3.将所有csi整合到一起,保存为csv