实验目的
编程实现一个文本生成模型来进行古诗生成。要求输入七言绝句的第一句,模型能生成剩余的三句古诗。
数据描述
• 数据集共分为训练集、验证集及测试集三部分。
• 训练集和验证集每行均代表一首完整的古诗,体裁为七言绝句(每句7 字,一共4 句)。
• 测试集中的每行为一个样本,只有古诗的第一句话,要求模型能以古诗的所给的第一句为输入来生成剩余的三句。
方法探究
传统的方法是使用seq2seq模型(encoder-decoder)加上attention机制,原理不再赘述。输入序列是古诗的第一句话,目标序列是古诗的后三句,或者只是后一句(然后接着递归生成到三句)。两种方式我都简单地尝试了,不仅收敛慢,而且效果也不是很好,体现在几乎为零的押韵、对仗以及通顺程度上。
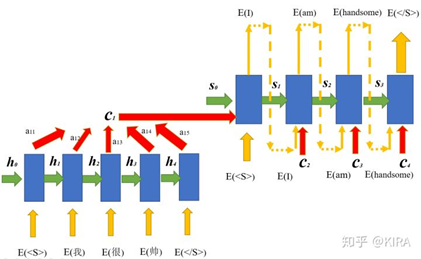
seq2seq模型

四个例子(左边是现有的,右边是生成的)
虽然说“万物皆可seq2seq”,但如何取得更好的效果?我自然想到了Bert模型在生成方面的应用——UNILM。
UNILM中seq2seq LM的思想很简单,直接通过mask矩阵将seq2seq当成句子补全来做,比如说输入 “两个黄鹂鸣翠柳”,目标句子是“一行白鹭上青天”,那UNILM将这两个句子拼成一个:[CLS] 两个黄鹂鸣翠柳[SEP]一行白鹭上青天[SEP]。经过这样转化之后,可以训练一个语言模型,然后输入“[CLS]两个黄鹂鸣翠柳[SEP]”来逐字预测“一行白鹭上青天”,直到出现“[SEP]”为止。

过程演示

输入部分做双向Attention,输出部分做单向Attention
好处是,我们只需要在单个bert模型上添加这样的mask,其他直接沿用bert的架构和权重就行了,非常容易实现。
步骤
• 由于时间紧迫,我直接调用了现有的bert4keras包,里面集成了mask的方案,这使我们在搭建模型方面几乎没有困难。
• 将古诗按第一句和后三句切分,然后使用tokenizer.encode将这两部分拼起来,并得到对应的token_id和segment_id:

• 调用本地的Albert模型(albert_small_zh_google)

• 损失函数采用输入和输出的交叉熵,并且要mask掉第一句的部分
• 预测时使用Beam Search,在每步计算时只保留当前最优的topk个候选结果。
实验结果
本次实验采用Google的colab环境,训练了百余个epoch,时间大约有一天多,训练集上的loss一直下降,但是验证集上的loss有很大波动,导致很难选择最好的模型(可能是《Sequence-to-Sequence Learning as Beam-Search Optimization》中提到的局部训练导致局部最优问题)。我最后选择了train loss稳定后val loss较小的作为最终模型。
同时,在本次实验中,我苦恼于评测标准的选取,因为传统的BLEU是用来评测翻译的,本质是计算两个句子的共现词频率,但我们的古诗并不是机械的翻译,而且想做到和原句共现词很多是特别困难的(考虑到相似的意象和意境)。我查询到前人的一些指标:诗性(音韵要求)、流畅性、条理性、内涵性,但是这些需要专家的评价,我只好自己斗胆稍微分析一下。

• 诗性:可以发现,模型能够学到基本的押韵,二四句能押上,也有一定的对仗,比如“莺声涩”、“蝶梦残”。
• 流畅性:整体可读,略有不足之处是会出现难以理解的短语,比如第一首的“两诸斑”。
• 条理性:我们的模型的输出是21个连起来的字,但是每七个字会自动成意,而且前后诗句表达的内容基本是一致的,不会南辕北辙。
• 内涵性:生成的后三句紧紧围绕了第一句的主题,情感极性能做到一致
总之,本次采用的方法取得了一定的效果,虽然离原诗还有一定的距离,但是已经初具雏形,某些诗甚至和原诗不相上下。如果再训练一段时间,或者使用更大的语料,应该可以达到更佳的效果。
总结反思
在本次作业中,我们把UNILM中seq2seq的思想应用到诗歌生成上,把万能的seq2seq和bert的强大结合在一起,得到了比传统RNN以及seq2seq更好的效果。而且我们使用的只是最基本的模型,如果有时间加上格律的控制、主题的规划,应该可以更进一步。
当然,以目前诗歌生成技术,学习到的仍然只是知识的概率分布,因此尽管生成的诗歌看起来有模有样,但是感觉只是徒有其表,缺乏一丝灵性。另外一方面,诗歌缺乏可靠的自动评估方法,优化的目标函数和主观的评价指标之间存在较大的gap,也影响了诗歌生成质量的提高。这都是我们需要思考和解决的。