kave on azure getting started
This page is a user quick-start guide to using an already-deployed KAVE on Azure. If you are looking to deploy KAVE in a different general environment, start with our Kave github wiki or contact us directly via kave@kpmg.com.
Thanks for trying this KAVE deployment. This document will help you get started with your Kave. There are two main steps involved in getting started.
- Accessing your Kave
- Working with your Kave
This document contains both these descriptions. If more guidance is required we can recommend you look at our full documentation (links below where appropriate) or start from our Kave github wiki or contact us directly via kave@kpmg.com.
- A deployed KAVE on Azure using one of our resource templates
- A machine where you can install/run software, have some control over outgoing whitelists, or with certain software pre-installed (see below)
Important to note is that during the provisioning you will have provide three crucial parameters:
- KAVEAdminUserName
- KAVEAdminPassword
- dnsLabelPrefix
Besides that you will also need to know the azure region to which your Kave has been deployed. From these four pieces of data your access credentials can be derived.
username = KAVEAdminUserName
password = KAVEAdminPassword
url = dnsLabelPrefix.REGION_OF_RESOURCE_GROUP.cloudapp.azure.com
So if:
- KAVEAdminUserName = admin
- KAVEAdminPassword = some_password
- dnsLabelPrefix = mykavetest
- region = westeurope
The derived credentials would be:
username = admin
password = some_password
url = mykavetest.westeurope.cloudapp.azure.com
You default installation will initially only be accessible with these values. In all further documentation we'll assume you have this information available.
We've created a generic video describing how you can connect to a general KAVE. You can either follow this and/or follow the written manual below.
The following video gives a full walkthrough for accessing your Kave environment. This is a generic video applicable to any KAVE, for KAVEs deployed through the Microsoft Azure Marketplace it is then possible to give more concrete examples.
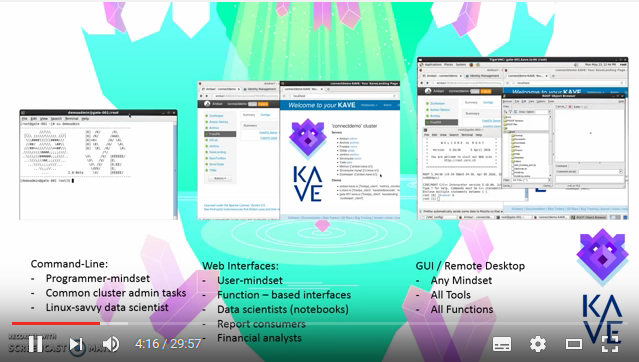
Your KAVE is a cluster of linux-based system on Azure. This implies at some point your data scientists will need to access a linux system. Most often this is achieved using a combination of firewall rules, VPNs, secure shell connections (ssh) and remote desktop sessions (either using the microsoft RDP, open-source VNC, or other related remote desktop systems such as NoMachine or aws workspaces).
Exactly how you accomplish this is up to you, the regulations of your department or company, your network configuration, where the KAVE is located, and your level of expertise.
In most cases, to grant analysts access to the data is the same as granting analysts access to your KAVE. To access your KAVE the most basic requirement is:
- A ssh client locally installed (for example PuTTY for Windows, or the standard client for Mac/Linux (available by default))
- A port open through your firewall to connect to the gateway of your KAVE (some corporate networks don't allow for this)
- Knowledge of your local proxy setting (if any)
Given that you have these three very simple and standard things, you can access your KAVE.
Note that:
- SSH is always encrypted
- SSH allows for multiple hops, in case you need to access different resources in your KAVE, you can double-hop through SSH, and this is then doubly encypted
- SSH is a globally used standard on a wide range of web servers and solutions
- SSH does not give anyone else access to your local computer
- SSH cannot be 'sniffed' for passwords and does not grant anonymous access
- There is no sufficiently mature alternative to ssh-based connection
- Permitting only ssh-key access is a choice which can make brute force password hacking impossible
It is likely that you will also want to install a file-copying tool, such as WinSCP.
If you are unable to install a ssh client, usually because you are on a centrally managed windows machine or behind a very restrictive firewall, then it is likely you will need to setup an external server where an ssh client can be installed.
You can use the connection url, username & password directly to connect to you Kave.
Given that you have a working ssh connection, your analysts (or yourself) will most definitely need access to the software services running in your KAVE, and one easy way to do this is through the web-UIs that all our standard software usually permits. This requires setting up an ssh proxy.
The first step for this is opening an ssh connection to your Kave with a dynamic tunnel. On the commandline this is done by adding the -D3000 option to your ssh command.
ssh -D3000 KaveAdmin@mykavetest.westeurope.cloudapp.azure.comIn Putty it is done via this screen:
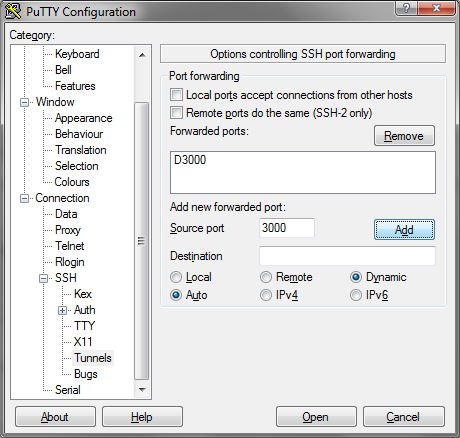
Once this is done you can route your traffic like a proxy through your ssh connection. You'll need to setup you browser to use localhost port 3000 as a sock5 proxy and you be ready to go.
You may wish the entire development of solutions and visualization of results to take place on your own dedicated KAVE without the option of copying data back to a developer/analyst laptop. In this case you will need a desktop experience within the KAVE network. There are several options for this also, one way to do this is to use VNC or RDP.
For VNC, get a client first (e.g. TightVNC, VNCViewer). For RDP, assuming you are on Windows, an RDP client is already available.
We recommend using VNC over SSH or RDP, so that it is secure and encrypted between endpoints, this is explained in the video above. Feel free to contact us if you need help on how to setup RDP over SSH for KAVE on Azure.
If you've used the KAVE marketplace deployment, connecting via VNC is very easy. Because the gateway server was automatically provisioned with this in mind, we already started a server for the KaveAdmin user on port 5961. :
-
Using VNC directly (from windows):
- Download/install a VNC client, we recommend Tight VNC
- Download/install/configure an ssh client for tunneling as discussed above
- Copy the public IP address of the gateway machine - you find this on your Azure portal page, the resource name is
gate - Connect to
localhost:1for example; the password is the same as the KAVE admin password
-
Using VNC directly (from linux):
- Copy the public IP address of the gateway machine - you find this on your Azure portal page, the resource name is
gate - Start an ssh tunnel on the command line, to destination port 5901 on the gateway IP (see video)
- open vncviewer to connect to
localhost:5901; the password is the same as the KAVE admin password
- Copy the public IP address of the gateway machine - you find this on your Azure portal page, the resource name is
-
Over remote desktop protocol
- open up remote desktop
- type in the IP address of the gateway machine
- use the KAVE admin username and password
Finally again, make sure to be on a broadband connection for the best remote-desktop experience.
Since you have a full desktop environemnt, with controlled/administered sudoer privilages and access within the KAVE, encrypted natively, from your windows/mac/linux desktop you gain:
- Security of code and solutions as well as data. Often the code you use to do your analysis should be considered proprietary and may give insights about the data you have, if it falls into the wrong hands. By implementing one of the two above solutions you secure the code just as well as you secure the data itself.
- Developing close to the data. The shorter the round-trip between developer and data the better, the analysts will love to get their hands stuck straight into the data from where they are and use the tools they find the most appropriate.
- Transferrable skillset and very-highly-sought-after expertise. Data Scientists comfortable on a linux platform and able to design their own solutions from first principles are incredibly valuable to your organization.
Kave is an eclectic platform covering various concerns by combining different tools. On top of that every environment can differ greatly depending on their infrastructure and installed components. The solution we offer on Azure contains the following tools:
- HDP Hadoop
- Hue
- FreeIPA
- Gitlabs
- Twiki
- Archiva
- KaveToolbox
- KaveLandingpage
Each of these tools can come with their own web pages, commandline tooling and online manual. We like to refer you to their respective manuals for the full and correct instructions.
Note Login into Hue with your Kave admin user (eg. kaveadmin) credentials.
Once you have access to your kave you should be able te view the KaveLanding page. This is a website located on the gateway machine (or the first machnine you connect to) and can be accessed via a browser. If you followed: Accessing your Kave - Advanced option 1 or 2 you should be able to use a browser to open the following page:
This gives you a quick overview of the tools available in your environment.
There are a lot of different potential users for a Kave with all different roles and expertises. A crucial tool which needs to be understood is FreeIPA. This tool is reachable via the browser and allows you to make sophisticated access policies.
The following roles can be managed separately if required, ordered from least restricted to most restricted:
- Access to services: an individual with access to the KAVE is granted access to at least to some list of services holding at least some of the data. Access to all services can be managed separately using groups within FreeIPA. It is possible to configure data access based on roles also but we don't really recommend KAVE for a multi-tenant environment.
- Administration rights on certain nodes: it is usual for certain data science tasks to require installation of software, and this often needs so-called superuser or sudoer rights.
- Ambari configuration management: access to the Ambari web interface to control and configure the cluster, add and monitor services.
- User management role: access to the FreeIPA management interface only. Presumably from a dedicated network.
- Network and infrastructure administration: configuring the firewall rules, spawning machines within the cluster, maintaining and monitoring the cluster's health.
- Terminal access to the Ambari administration node: should be heavily restricted, be default forbidden to all users.
- Admin access to the Ambari administration node: Granting admin rights on the admin node gives a person total control over the cluster. It is not needed for most purposes, usually access to the Ambari interface and FreeIPA is sufficient, but for certain new installation procedures, security updates, etc, this might be necessary.
This naturally leads to at least two roles within a small data science team:
- Data Scientist: Access to all services and data on the cluster, ingress over SSH on the gateway machine only. Usually members of the team.
- Data Architect: Access to all services and data on the cluster, ingress over SSH on the gateway machine only, access to the Ambari web interface, sudo rights on certain nodes. Usually at least one member of the data science team.
- Supporting Administrators: Access to all services and data on the cluster, ingress over SSH on the gateway machine only, sudoer on all nodes, access to the Ambari interface and FreeIPA interface. Perhaps also granted to a member of the data science team.
- Global Administrator: Complete control, using different usernames/passwords where required, from a very restricted location. Usually a member of the hosting provider's team, or a dedicated infrastructure team.
Note Due to classpath problems related to Snappy on older CentOS Hadoop installations snappy compression cannot be used when working with Spark in YARN mode, and in general should not be used at all. If you run across this problem, select another compression, eg:
spark-shell --master yarn-client --conf spark.io.compression.codec=lzf