This repository is the implementation of project Converting to Realistic Professional Singing Voices with Singer-Adaptive Representations and some baselines of Singing Voice Conversion (SVC) task.
We adopt two public datasets, Opencpop [1] and M4Singer [2], to conduct many-to-one singing voice conversion. Specifically, we consider Opencpop (which is a single singer dataset) as target singer and use M4Singer (which is a 20-singer dataset) as source singers. In addition, a ProSingers Dataset has been collected, which contains singing corpus by professional singers, covering different singing styles, languages, and genres.
[1] Yu Wang, et al. Opencpop: A High-Quality Open Source Chinese Popular Song Corpus for Singing Voice Synthesis. InterSpeech 2022.
[2] Lichao Zhang, et al. M4Singer: a Multi-Style, Multi-Singer and Musical Score Provided Mandarin Singing Corpus. NeurIPS 2022.
Our model incorporates a PPG-based end-to-end framework with two separate encoders for extracting content and timbre representations from the source audio, and an adversarial waveform generator framework like WaveGAN and ParallelWaveGan (PWG) is used to synthesize waveform from the mel spectrograms together with the reference embeddings of target singer from the singer-adaptive encoder.

The singer-adaptive encoder for target singer representation follows the design in [12], tentatively. The encoder consists of 1) a pre-net to preprocess the linear-spectrograms of the target singing voice, 2) several Transformer blocks to generate a hidden sequence, and 3) an average pooling module to compress the hidden sequence into the singer embedding which contains the timbre information of the targetsinger.

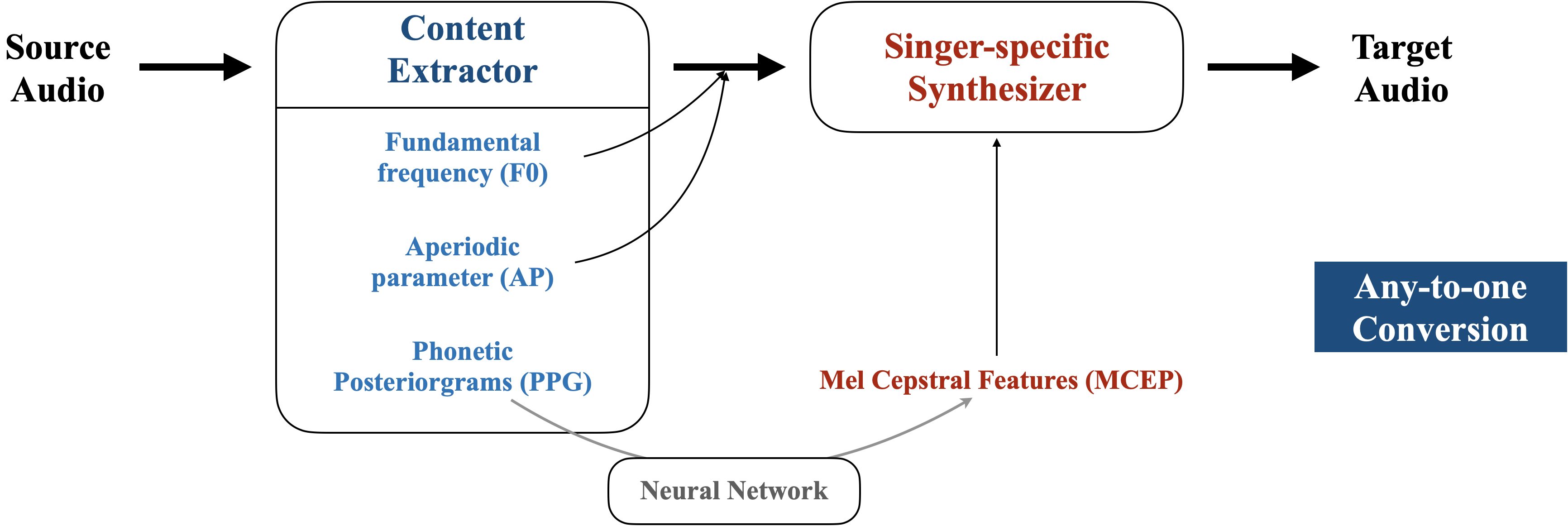
This model is proposed by Xin Chen, et al:
Xin Chen, et al. Singing Voice Conversion with Non-parallel Data. IEEE MIPR 2019.
As the figure above shows, there are two main modules of it, Content Extractor and Singer-specific Synthesizer. Given a source audio, firstly the Content Extractor is aim to extract content features (i.e., singer independent features) from the audio. Then, the Singer-specific Synthesizer is designed to inject the singer dependent features for the synthesis, so that the target audio can be able to capture the singer's characteristics.
We can utilize the following two stages to conduct any-to-one conversion:
- Acoustics Mapping Training (Training Stage): This stage is to train the mapping from the textual content features (eg: PPG) to the target singer's acoustic features (eg: SP or MCEP).
- Inference and Conversion (Conversion Stage): Given any source singer's audio, firstly, extract its content features including F0, AP, and textual content features. Then, use the model of training stage to infer the converted acoustic features (SP or MCEP). Finally, given F0, AP, and the converted SP, we utilize WORLD as vocoder to synthesis the converted audio.
Strongly recommend to use Google Colab. You could ignore this if you have NVIDIA A100/V100 or RTX 4090/80.
## If you need CUDA support, add "--extra-index-url https://download.pytorch.org/whl/cu117" in this following
pip install torch==1.13.1 torchaudio==0.13.1
pip install pyworld==0.3.2
pip install diffsptk==0.5.0
pip install tqdm
pip install openai-whisper
pip install tensorboardAfter you download the datasets, you need to modify the path configuration in config.py:
# To avoid ambiguity, you are supposed to use absolute path.
# Please configure the path of your downloaded datasets
dataset2path = {"Opencpop": "[Your Opencpop path]",
"M4Singer": "[Your M4Singer path]"}
# Please configure the root path to save your data and model
root_path = "[Root path for saving data and model]"Transform the original Opencpop transcriptions to JSON format:
cd preprocess
python process_opencpop.pySelect some utterance samples that will be converted. We randomly sample 5 utterances for every singer:
cd preprocess
python process_m4singer.pyDuring training stage, we aim to train a mapping from textual content features to the target singer's acoustic features. In the implementation: (1) For output, we use 40d MCEP features as ground truth. (2) For input, we utilize the last layer encoder's output of Whisper as the content features (which is 1024d). (3) For acoustic model, we adopt a 6-layer Transformer.
To obtain MCEP features, first we adopt PyWORLD to extract spectrum envelope (SP) features, and then transform SP to MCEP by using diffsptk:
cd preprocess
python extract_mcep.pyFor hyparameters, we use 44100 Hz sampling rate and 10 ms frame shift.
To extract whisper features, we utilze the pretrained multilingual models of Whisper (specifically, medium model):
cd preprocess
python extract_whisper.pyNote: If you face out of memory errors, open preprocess/extract_whisper.py and go to line 55. You could try to reduce the default batch_size of extract_whisper_features(dataset, dataset_type, batch_size=80). You could also go to line 99 to use a more suitable model.
This step may cost some time. Relax and take a sleep :)
If you are using Colab, you may need to reduce the total size of training data or divide 500 epoches into multiple runnings, due to the free time limit of Google Colab. See this link for more info.
cd model
sh run_training.shDuring training, you can listen to the predicted audio samples in the folder <root_path>/model/ckpts/Opencpop/<experiment_name> at different loss levels. You could expect to listen samples of good intelligibility after 100 epochs.
To obtain the infered MCEP features of M4Singer singers:
cd model
sh run_inference.shAt last, synthesis the converted audios using WORLD:
cd model
sh run_converse.sh[Work in progress ⏳]
- Python 3.7+
- PyTorch 1.7+
- Librosa
- NumPy
- tqdm
- Clone the repository and install dependencies
git clone https://github.com/SLPcourse/CSC3160-119010221-HaoyanLuo.git
cd CSC3160-119010221-HaoyanLuo
pip install -r requirements.txtconda environment is recommended.
- Process Data
Here we only provide the processing steps for ProSinger. You can refer steps for other dataset in the original repo. Note the the vocal.wav files are renamed to song_id.wav (e.g. 1.wav).
First, slice the vocal data into audio segments for training.
cd proprocess
python slice_prosinger.py --singer "singer_name"Then, process the specified singer data to training format
python process_prosinger.py[Work in progress ⏳]
[Work in progress ⏳]
| Method | MOS ↓ | GPE ↓ | NCC ↓ |
|---|---|---|---|
| WORLD-based SVC | - | - | - |
| USVC | - | - | - |
| Our method | - | - | - |