This repository includes the dataset and code for our ACL'22 Finding paper Towards Transparent Interactive Semantic Parsing via Step-by-Step Correction.
Existing studies on semantic parsing focus primarily on mapping a natural-language utterance to a corresponding logical form in one turn. However, because natural language can contain a great deal of ambiguity and variability, this is a difficult challenge. In this work, we investigate an interactive semantic parsing framework that explains the predicted logical form step by step in natural language and enables the user to make corrections through natural-language feedback for individual steps. We focus on question answering over knowledge bases (KBQA) as an instantiation of our framework, aiming to increase the transparency of the parsing process and help the user appropriately trust the final answer. To do so, we construct INSPIRED, a crowdsourced dialogue dataset derived from the ComplexWebQuestions dataset.
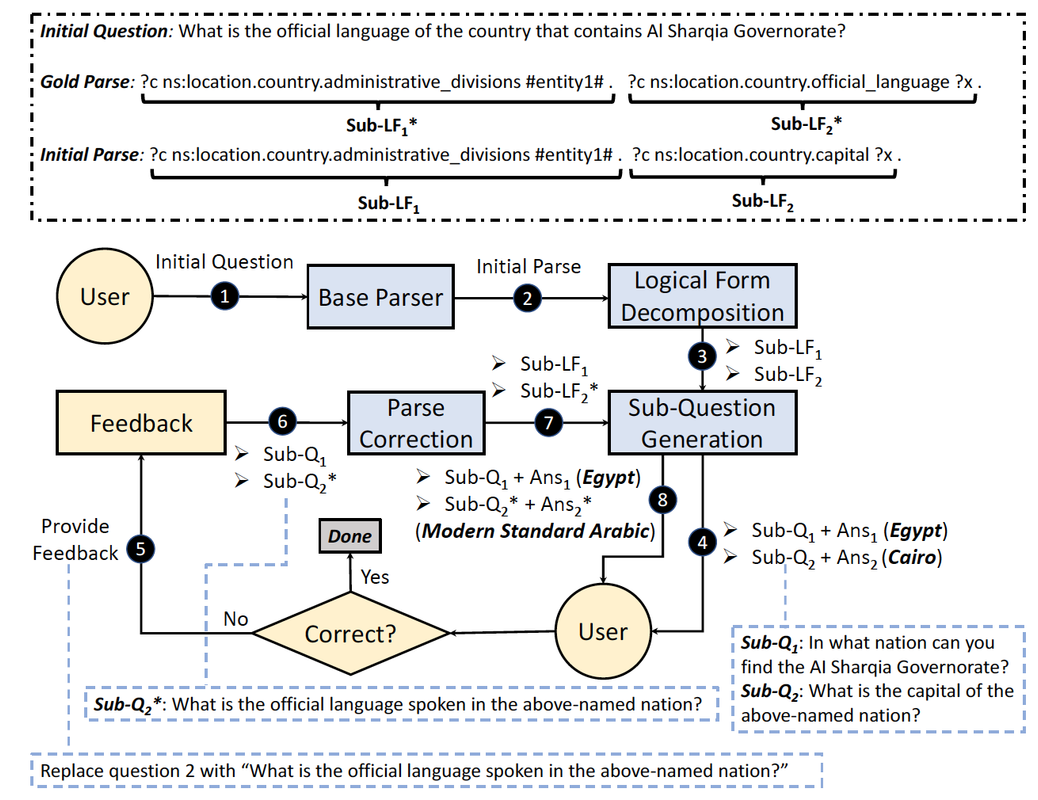
Here is an example dialogue that can be seen from the user perspective in our INSPIRED dataset. The agent turns illustrate our emphasis on transparency by explaining the predicted logical form step by step in natural language, along with intermediate answers, to the user for feedback.

The full process of our framework is illustrated below for KBQA via interactive semantic parsing. In this framework, once the logical form for a given question is predicted by a base semantic parser, we decompose it into sub-logical forms (Logical Form Decomposition) and translate each sub-logical form to a natural language question (Sub-Question Generation), which can illustrate the steps of answering the question, allowing the user to see exactly how a final answer is found and be confident that it is correct or make corrections to individual steps through natural language feedback. With the feedback, parse correction module serves to correct the corresponding sub-logical form in a certain step. The user is allowed to provide feedback iteratively.
The dataset can be downloaded in this link.
In the dataset file, each line is a dictionary with several keys:
{
"id": "ID number",
"cwq_question": "Original complex question in CWQ dataset",
"rephrased_question": "Rephrased complex question by workers",
"rephrased_question_label": " 'Replacement' or 'Alternative' ",
"question": "If rephrased_question_label is marked as 'Replacement', set the value the same as rephrased_question; Otherwise, set it the same as cwq_question",
"final_answer": "Final answer for the complex question",
"gold_parse": "Gold sparql query for complex question",
"preprocessed_gold_parse": "Preprocessed gold parse with entities and prefix replaced",
"predicted_parse": "Predicted sparql query by initial semantic parser",
"gold_sub_lfs": "A list of gold sub-logical forms after decomposition",
"pred_sub_lfs": "A list of predicted sub-logical forms after decomposition",
"gold_sub_qs": [
{
"sub_id": "ID of sub questions",
"sub_question": "Rephrased sub question",
"temp_sub_question": "Templated sub question for gold sub-logical form",
"answer": "Answer for each sub question",
}, "..."],
"pred_sub_qs": [
{
"sub_id": "ID of sub questions",
"sub_question": "Rephrased sub question",
"temp_sub_question": "Templated sub question for predicted sub-logical form",
"answer": "Answer for each sub question",
}, "..."],
"feedback": "A list of human feedback"
}Following HSP, we preprocess the original SPARQL queries in CWQ dataset and convert them into simplified and compacted version.
Script is available at
./data_process/preprocess_lf.py
Given a processed SPARQL query above, we decompose it into a series of sub-queries. Then we create a template corpus for those predicates that appear in CWQ dataset. Our translation strategy then converts the sub-queries into templated sub-questions, which are the ones we show to the crowdworkers.
In addition to a template corpus for normal predicates, we also maintain two small corpuses to handle restriction predicates. Check our paper for more details.
Check
./data_process/translation.pyfor translation script including the logical form decomposition. Several corpora mentioned above are saved at./data_process/corpus
Given a sub-question as NL feedback, the parse correction task is to convert it into a corrected sub-LF. Our experiments are mostly based on the implementation of seq2seq model on HuggingFace. We found that the BART-large model with inputs that leverage the dialogue history of sub-LFs and sub-questions achieves the best performance. Different dialogue histories are concatenated with the original input using a separate token
</s>.
We release the best-performed checkpoints here.
Sub-question generation aims to translate a sub-LF into a natural sub-question. Similarly, based on the HuggingFace, the BART-large model with the input containing both the complex question and the history of templated sub-questions performs the best.
The checkpoints are stored here.
@misc{mo2021transparent,
title={Towards Transparent Interactive Semantic Parsing via Step-by-Step Correction},
author={Lingbo Mo and Ashley Lewis and Huan Sun and Michael White},
year={2021},
eprint={2110.08345},
archivePrefix={arXiv},
primaryClass={cs.CL}
}