-
Notifications
You must be signed in to change notification settings - Fork 6
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
3 changed files
with
157 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,45 @@ | ||
| --- | ||
| layout: post | ||
| title: 'Detecting Twenty-thousand Classes using Image-level Supervision' | ||
| date: 2023-11-09 | ||
| author: 郑之杰 | ||
| cover: 'https://pic.imgdb.cn/item/658924a6c458853aef6934fc.jpg' | ||
| tags: 论文阅读 | ||
| --- | ||
|
|
||
| > 使用图像级监督检测两万个类别. | ||
| - paper:[Detecting Twenty-thousand Classes using Image-level Supervision](https://arxiv.org/abs/2201.02605) | ||
|
|
||
| 限制现阶段目标检测器性能的主要原因是其可获得的训练数据量规模太小。**LVIS 120K**的图片,包含了**1000+**类,**OpenImages 1.8M**的图片,包含了**500+**类。而图像分类的数据量就相对来说大得多同时更加容易收集。 | ||
|
|
||
|  | ||
|
|
||
| 作者提出了目标检测训练方法**Detic**,直接使用**ImageNet21K**的分类图像数据集和目标检测数据集一起,对检测模型进行联合训练。**Detic**易于实现,在大部分的检测**backbone**上都可以接入使用。**Detic**的主要特点: | ||
| 1. 针对现阶段目标检测弱监督训练的问题使用了更简单易用的替换方案。 | ||
| 2. 提出一个新的损失函数,使用图像级别的监督信号提升目标检测器的性能。 | ||
| 3. 训练出来的目标检测器可以无需微调,直接迁移到新的数据集和检测词汇表上。 | ||
|
|
||
| 常规的弱监督目标检测方法是一种基于预测的**label-box**分配机制,由**RPN**获取**proposal**,然后将每个图像层面类别分配到待定的**proposal**中,由于缺少区域级别的监督信号,这样的做法很容易产生误差。 | ||
|
|
||
| 而**Detic**的做法是选取最大面积的**proposal**(通常情况下这个**proposal**几乎包括了整张图片),然后这个**proposal**对应的**label**就是整个图像层面的类别。 | ||
|
|
||
|  | ||
|
|
||
| 训练集中包含目标检测数据和**ImageNet21K**的分类图像数据。如果是检测数据,则直接进行正常的两阶段目标检测流程,**Reg Head**回归**bbox**,**Classification Head**分类。如果是**ImageNet21K**图像数据,则使用检测器检测**Max-size**的图像区域并截取,然后送入**Classification Head**进行分类。通过共享**Classification Head**实现更多的**ImageNet21K**中的**object concept**知识的迁移。 | ||
|
|
||
| $$ | ||
| L(\mathbf{I})= \begin{cases} L_{\mathrm{rpn}}+L_{\mathrm{reg}}+L_{\mathrm{cls}}, & \mathrm{if~I\in\mathcal{D}}^{\mathrm{det}} \\ \lambda L_{\mathrm{max-size}}, & \mathrm{if~I\in\mathcal{D}}^{\mathrm{cls}} \end{cases} | ||
| $$ | ||
|
|
||
| 作者提出了以下损失函数来让目标检测器可以使用图像级别的标签进行训练: | ||
|
|
||
| $$ | ||
| L_{\mathrm{max-size}}=B C E({\bf W f}_{j},c),j=\arg\mathrm{max}_{j}(\mathrm{size}({\bf b}_{j})) | ||
| $$ | ||
|
|
||
| 其中$f$代表**proposal**对应的**RoI feature**,**c**是最大的**proposal**对应的类别,也就是是该图片对应的类别,$W$是分类器的权重。 | ||
|
|
||
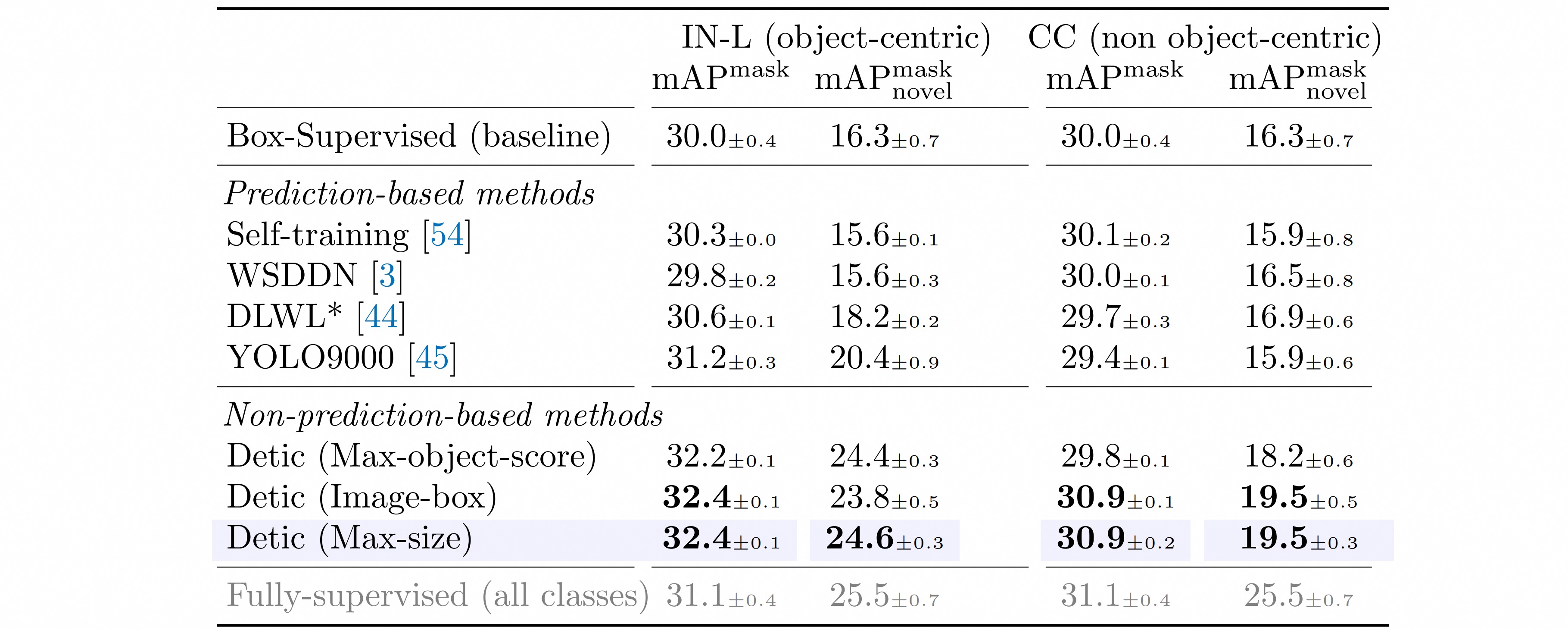
| **Box-Supervised**表示只使用传统的目标检测数据进行训练的目标检测器。剩余的训练方法就是其余的使用图像级别的数据来做弱监督训练的目标检测器。从中可以看出使用**Detic**方法训练出来的目标检测器在各项指标上都获得了最佳成绩。 | ||
|
|
||
|  |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,57 @@ | ||
| --- | ||
| layout: post | ||
| title: 'RegionCLIP: Region-based Language-Image Pretraining' | ||
| date: 2023-11-10 | ||
| author: 郑之杰 | ||
| cover: 'https://pic.imgdb.cn/item/658a72a2c458853aefc127a6.jpg' | ||
| tags: 论文阅读 | ||
| --- | ||
|
|
||
| > RegionCLIP:基于区域的语言图像预训练. | ||
| - paper:[RegionCLIP: Region-based Language-Image Pretraining](https://arxiv.org/abs/2112.09106) | ||
|
|
||
| 视觉-语言模型取得了很大的突破,这些模型使用了大量图文对来学习图像和文本的匹配。为了探索这种思路能否在 **region-caption** 的情况下起作用,作者基于预训练好的 **CLIP** 模型构建了一个 **R-CNN** 形式的目标检测器**RegionCLIP**。 | ||
|
|
||
| 在 **LVIS** 数据集上,当使用 **proposal** 作为输入时,**CLIP** 的得分无法指代定位的质量;使用 **gt** 框作为输入,**CLIP** 在 **LVIS** 框上的分类准确率只有 $19\%$,所以直接将预训练好的 **CLIP** 拿来用于对 **region** 的分类不太适合。 | ||
|
|
||
|  | ||
|
|
||
| **CLIP** 模型的训练是使用整个 **image** 作为输入的,使用的是 **image-level** 的文本描述来训练的,所以模型学习到的是整张图的特征,无法将文本概念和图像中的区域联系起来。**RegionCLIP**在预训练过程中将 **image region** 和 **text token** 进行对齐,先从输入图像中抠出候选区域,然后使用 **CLIP** 模型将抠出的区域和 **text embedding** 进行匹配。 | ||
|
|
||
|  | ||
|
|
||
| 由于 **CLIP** 缺少 **region** 层面的训练,所以 **RegionCLIP** 构建了一些 **region** 的伪标签来和 **image-text** 一起预训练:从网络数据中收集图像描述语句,然后使用 **NLP parser** 来提取出有效的目标词汇,构建词汇池,然后将词汇池的每个词都填入 **prompt** 模版(**a photo of xxx**),并且对每个词汇对应的 **prompt** 模版使用 **CLIP** 的 **text encoder** 来得到语义特征,所有的 **region concept** 都能够使用 **semantic embedding** $$\{l_j\}_{j=1,...,C}$$来表示。 | ||
|
|
||
| 为了使得构建的 **region** 伪标签和 **region** 对应,使用 **CLIP** 的 **visual encoder** 来提取每个 **region** 的 **visual feature** $v_i^t$,计算其和词汇池中的向量的距离,得分最大的向量就作为该 **region** 对应的伪标签$$\{v_i, l_m\}$$。 | ||
|
|
||
| $$ | ||
| S(v,l)=\frac{v^{T}\cdot l}{|| v||\cdot||l||} | ||
| $$ | ||
|
|
||
|
|
||
| 将 **images-concept** 和 **region-concept** 的数据联合进行预训练,训练的时候会同时使用对比学习 **loss** 和蒸馏 **loss**: | ||
|
|
||
| $$ | ||
| {\cal L}={\cal L}_{c n t r s t}+{\cal L}_{d i s t}+{\cal L}_{c n t r s t-i m g} | ||
| $$ | ||
|
|
||
| **region-text** 对比学习 **loss** 计算学生模型学习的 **region-text pairs** 的相似度: | ||
|
|
||
| $$ | ||
| L_{c n t r s t}={\frac{1}{N}}\sum_{i}-\log(p(v_{i},l_{m})) \\ | ||
| p(v_{i},l_{m})=\frac{\exp(S(v_{i},l_{m})/\tau)}{\exp(S(v_{i},l_{m})/\tau)+\sum_{k\in{\cal{N}}_{r_{i}}}\exp(S(v_{i},l_{k})/\tau)} | ||
| $$ | ||
|
|
||
| 蒸馏 **loss** 计算教师模型和学生模型得到的 **region-text** 的 **matching score**: | ||
|
|
||
| $$ | ||
| L_{d i s t}=\frac{1}{N}\sum_{i}L_{K L}(q_{i}^{t},q_{i}) | ||
| $$ | ||
|
|
||
| **image-text** 的对比 **loss** 可以从 **region level** 扩展而来,即一个 **box** 覆盖了整张图,文本描述来源于网络。 | ||
|
|
||
| 预训练之后,训练得到的 **visual encoder** 可以直接用于 **region reasoning** 任务,比如从 **RPN** 获得区域,从训练的 **visual encoder** 得到该区域的视觉表达,然后和文本词汇表达进行匹配,得到相似度最高的文本。实验证明使用 **RPN score** 能够提升 **zero-shot** 推理的效果,所以作者使用 **RPN objectness score + category confidence score** 的均值来作为最终的得分,用于匹配。 | ||
|
|
||
| 预训练中的 **visual encoder** 是从 **teacher model** 提供的 **region-text alignment** 中学习的,不需要人为一些操作,所以也会有噪声;可以进一步微调 **visual encoder**。作者通过初始化目标检测器的 **visual backbone** 来实现,先使用现有的 **RPN** 网络来进行目标区域的定位,然后将区域和文本匹配。 | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,55 @@ | ||
| --- | ||
| layout: post | ||
| title: 'Exploiting Unlabeled Data with Vision and Language Models for Object Detection' | ||
| date: 2023-11-11 | ||
| author: 郑之杰 | ||
| cover: 'https://pic.imgdb.cn/item/658a8d37c458853aef1f9dc8.jpg' | ||
| tags: 论文阅读 | ||
| --- | ||
|
|
||
| > 通过视觉和语言模型探索目标检测中的无标签数据. | ||
| - paper:[Exploiting Unlabeled Data with Vision and Language Models for Object Detection](https://arxiv.org/abs/2207.08954) | ||
|
|
||
| 构建通用目标检测框架需要扩展到更大的标签和训练数据集,然而大规模获取类别标注的成本过高。作者利用最近视觉和语言模型中丰富的语义来定位和分类未标记图像中的目标,有效地生成用于目标检测的伪标签。从通用的和类无关的**region proposal**机制开始,作者使用视觉和语言模型将图像的每个区域分类为下游任务所需的任何目标类别。 | ||
|
|
||
| 该方法利用最近提出的视觉和语言模型**CLIP**来生成用于目标检测的伪标签。首先使用两阶段**proposal**生成器预测区域。对于每个区域使用预训练的**V&L**模型获得预测类别的概率分布。为了改进定位质量,作者融合两阶段**proposal**生成器的**CLIP**分数和目标分数,并通过在**proposal**生成器中重复应用定位头来移除冗余提**proposal**。最后将生成的伪标签与原始**ground truth**相结合,训练最终检测器。 | ||
|
|
||
|  | ||
|
|
||
| 从未标记数据中学习的方法是通过伪标签。首先在有限的**Ground Truth**数据上训练教师模型,然后为未标记的数据生成伪标签,最后训练学生模型。作者提出了一种用于目标检测的通用训练策略,以处理不同形式的未标记数据。定义一个目标检测器的通用损失函数: | ||
|
|
||
| $$ | ||
| \mathcal{L}(\theta,\mathcal{I})=\frac{1}{N_{\mathcal{I}}}\sum_{i=1}^{N_{\mathcal{I}}}[I_{i}\in \mathcal{I}_{L}] l_{s}(\theta,I_{i})+\alpha[I_{i}\in \mathcal{I}_{U}] l_{u}(\theta,I_{i}) | ||
| $$ | ||
| 监督损失包含分类的标准交叉熵损失和回归的**L1**损失: | ||
|
|
||
| $$ | ||
| l_{s}(\theta,I)=\frac{1}{N^{s}}\sum_{i}l_{c l s}\left(C_{i}^{\theta}(I),c_{\sigma(i)}^{s}\right)+[\sigma(i)\neq nil] l_{r e g}\left(T_{i}^{\theta}(I),\mathrm{t}_{\sigma(i)}^{s}\right) | ||
| $$ | ||
|
|
||
| 无监督损失使用具有高置信度的伪标签作为监督信号: | ||
|
|
||
| $$ | ||
| l_{u}(\theta,I)=\frac{1}{N^{u}}\sum_{i}[\max(p_{\sigma(i)}^u)\geq \tau]\cdot l_{c l s}\left(C_{i}^{\theta}(I),c_{\sigma(i)}^{u}\right)+[\sigma(i)\neq nil] l_{r e g}\left(T_{i}^{\theta}(I),\mathrm{t}_{\sigma(i)}^{u}\right) | ||
| $$ | ||
|
|
||
| 通过使用网络抓取的数据 (图像和相应的文本),**VL**语言模型可以在没有昂贵人工注释的情况下在大规模图像-文本对数据集上进行训练,覆盖不同的图像域和自然文本中丰富的语义。**VL**模型是为任意类别生成伪标签的理想外部知识来源,可用于下游任务,例如开放词汇或半监督目标检测。 | ||
|
|
||
| 使用最近的**V & L**模型**CLIP**生成伪标签的整体流水线如图所示。首先将一个未标记的图像输入两阶段检测器以获得区域**proposal**。然后根据这些区域裁剪图像块,并将其输入图像编码器,以嵌入**CLIP**视觉空间中。使用相应的**CLIP**文本编码器为特定任务所需的类别名称生成嵌入。对于每个区域,通过点积计算区域嵌入和文本嵌入之间的相似性,并使用**softmax**获得类别上的分布。 | ||
|
|
||
|  | ||
|
|
||
| 上述框架面临两个关键挑战: | ||
| 1. 为开放词汇检测所需的新类别生成可靠的区域**proposal**; | ||
| 2. 克服原始**CLIP**模型的定位质量较差的特点。 | ||
|
|
||
| 为了利用未标记数据进行开放式词汇检测等任务,**proposal**生成器不仅应该能够定位训练期间看到的类别,还应该能够定位新类别。两级检测器的区域建议网络(**RPN**)对于新类别具有良好的泛化能力。因此作者训练了一个标准的两阶段检测器**Faster R-CNN**作为**proposal**生成器。 | ||
|
|
||
| 在裁剪区域**proposal**上直接应用**CLIP**会产生较低的定位质量。作者发现**RPN**分数是衡量区域**proposal**定位质量的一个良好指标。利用这一观察结果,将**RPN**分数与**CLIP**预测值进行平均。其次作者去除**proposal**生成器的阈值和**NMS**,并将**proposal**框多次馈送到**RoI**头。通过重复**RoI**头将冗余框推近彼此。这样可以产生位置更好的边界框,并提供更好的伪标签。 | ||
|
|
||
|  | ||
|
|
||
| 作者演示了生成伪标签在两个特定任务中的价值:开放词汇检测,其中模型需要推广到看不见的目标类别;半监督目标检测,其中可以使用额外的未标记图像来改进模型。本文的实证评估显示了伪标签在这两项任务中的有效性,在这两项任务中,本文的表现优于竞争基线,并实现了开放词汇表目标检测的**SOTA**。 | ||
|
|
||
|  |