{kind=link}
{kind=link}
{kind=link}
{kind=link}
Pre-Tasks for LFX Mentorship project " Support piper as a new backend of the WASI-NN WasmEdge plugin"
This repo contains the record of pre-qualifying task for the LFX Mentorship project under WasmEdge project. I am currently using Debian 12 Bookworm
Icon name: computer-laptop
Chassis: laptop 💻 Machine ID: f4cf47ccae8d41be85ed6fec77733513
Boot ID: bef04fc4ac9447f0999005928c062ada
Operating System: Debian GNU/Linux 12 (bookworm)
Kernel: Linux 6.1.0-21-amd64
Architecture: x86-64
Hardware Vendor: Lenovo
Hardware Model: IdeaPad Gaming3 15ARH05D
Firmware Version: FCCN18WW
My previous contribution to Piper Framework :
To build the piper Framework first we need to have Piper-phonemize in the lib/linux-x86_64/ directory.
I cloned the forked repo from my github and build using docker :
docker buildx build . -t piper-phonemize --output 'type=local,dest=dist'
then I copied the piper-phonemize folder into the /lib/x86_64-linux-gnu/ folder.
Clone the fork of Piper to my local directory. I then made a build folder inside piper directory.
mkdir build
cd build/
since the CMakeLists.txt is in the folder above.
cmake .. && make . &&> piper_build_logs.txt
build logs for piper can be found here
checking if piper is installed correctly :
> ./piper --version
1.2.0
after the build was successfull I downloaded a voice and a config file and placed it inside the same folder. I chose "lessac_en_US" voice.
then I Ran a sample tts in piper with the followwing command :
echo 'Welcome to the world of speech synthesis!, the build has been successfull' | \
./piper --model en_US-lessac-medium.onnx --output_file welcome.wav
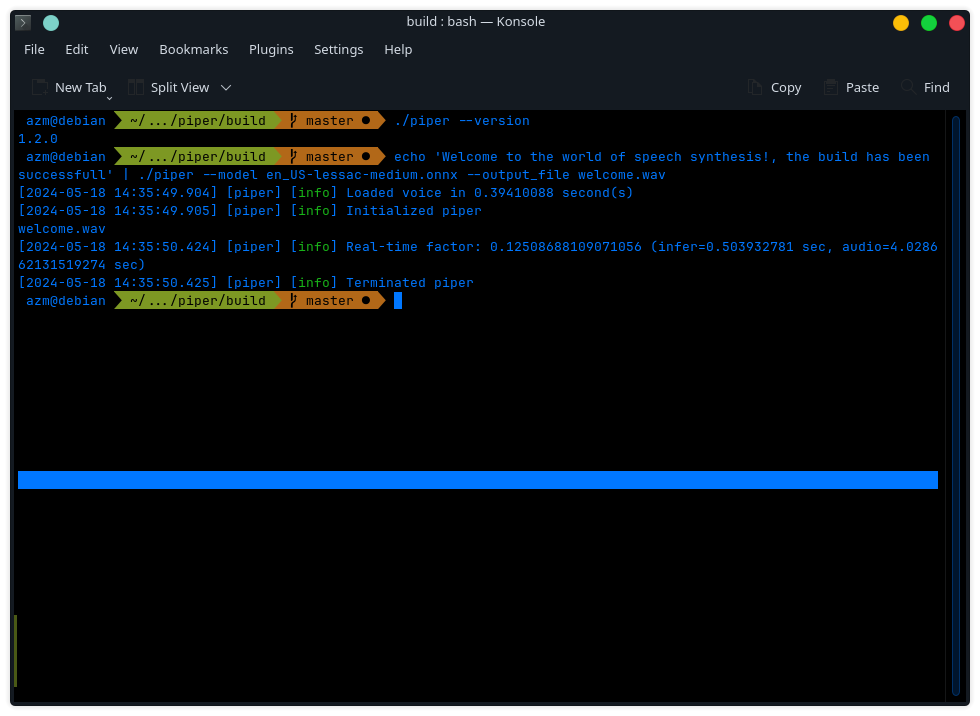
The output audio file welcome.wav
Now Lets Run a Sample application, lets convert the Paragraph 3 of Beyond Good and Evil by Fredrich nietzche from here using a different "high model" voice en_US-ryan-high
According to README.md file from piper we have to format the text in json format as text object with text field in .json file :
{ "text": "First sentence to speak." }
{ "text": "Second sentence to speak." }
to pass the JSON file as input we have to specify with --json-input flag.
cat bge_nietzche.json | ./piper --model en_US-ryan-high.onnx --json-input --output_file bge_nietzche.wav

the output file can be found here
To build WasmEdge I followed the following guide
docker pull wasmedge/wasmedge
docker rub -it --rm \
-v /home/azm/projects/WasmEdge/:/root/wasmedge \
wasmedge/wasmedge:latest
cmake -GNinja -Bbuild -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="60;61;70" \
-DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc \
-DWASMEDGE_PLUGIN_WASI_NN_BACKEND="GGML" \
-DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_BLAS=OFF \
-DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_CUBLAS=ON \
.
cmake --build build
cmake --install build
The build logs for WasmEdge with llama.cpp Can be found here
then I tested the build by running tests :
LD_LIBRARY_PATH=$(pwd)/lib/api ctest

To run llama2-7b I followed the following repo
Compiling the application to Wasm :
cd llama
cargo build --target wasm32-wasi --release
Downloading Model :
curl -LO https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/resolve/main/llama-2-7b-chat.Q5_K_M.gguf
Running the Llama-2-7b-Chat-GGUF model :
wasmedge --dir .:. \
--nn-preload default:GGML:AUTO:llama-2-7b-chat.Q5_K_M.gguf \
wasmedge-ggml-llama.wasm default
