- 자료구조(資料構造, 영어: data structure)는 전산학에서 자료를 효율적으로 이용할 수 있도록 컴퓨터에 저장하는 방법이다. 신중히 선택한 자료구조는 보다 효율적인 알고리즘을 사용할 수 있게 한다. 이러한 자료구조의 선택문제는 대개 추상 자료형의 선택으로부터 시작하는 경우가 많다. 효과적으로 설계된 자료구조는 실행시간 혹은 메모리 용량과 같은 자원을 최소한으로 사용하면서 연산을 수행하도록 해준다.

- 삽입 정렬(揷入整列, insertion sort)은 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘이다.

#define SWAP(X, Y, Z) Z=X; X=Y; Y=Z;
void insertSort(int * arr, int size) {
for (int ii = 0; ii < size; ii++) {
for (int jj = ii; jj > 0; jj--) {
int temp = 0;
if (arr[jj] < arr[jj - 1]) {
SWAP(arr[jj - 1], arr[jj], temp);
}
}
}
}- 퀵 정렬(Quicksort)은 찰스 앤터니 리처드 호어가 개발한 정렬 알고리즘이다. 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다. 퀵 정렬은 n개의 데이터를 정렬할 때, 최악의 경우에는 O(n2)번의 비교를 수행하고, 평균적으로 O(n log n)번의 비교를 수행한다. 퀵 정렬의 내부 루프는 대부분의 컴퓨터 아키텍처에서 효율적으로 작동하도록 설계되어 있고(그 이유는 메모리 참조가 지역화되어 있기 때문에 CPU 캐시의 히트율이 높아지기 때문이다.), 대부분의 실질적인 데이터를 정렬할 때 제곱 시간이 걸릴 확률이 거의 없도록 알고리즘을 설계하는 것이 가능하다. 때문에 일반적인 경우 퀵 정렬은 다른 O(n log n) 알고리즘에 비해 훨씬 빠르게 동작한다. 그리고 퀵 정렬은 정렬을 위해 O(log n)만큼의 memory를 필요로한다. 또한 퀵 정렬은 불안정 정렬에 속한다.

-
리스트 가운데서 하나의 원소를 고른다. 이렇게 고른 원소를 피벗이라고 한다.
-
피벗 앞에는 피벗보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 리스트를 둘로 나눈다. 이렇게 리스트를 둘로 나누는 것을 분할이라고 한다. 분할을 마친 뒤에 피벗은 더 이상 움직이지 않는다.
-
분할된 두 개의 작은 리스트에 대해 재귀(Recursion)적으로 이 과정을 반복한다. 재귀는 리스트의 크기가 0이나 1이 될 때까지 반복된다.
#define SWAP(X, Y, Z) Z=X; X=Y; Y=Z;
/* Quick Sorting */
void QuickSort(int * mArr, int left, int right)
{
int pivot = mArr[(left + right) / 2]; /* 중심축 */
int mLeft = left; /* 정렬 대상의 가장 왼쪽 지점 */
int mRight = right; /* 정렬 대상의 가장 오른쪽 지점 */
int mTemp = 0;
while (mLeft <= mRight) /* mLeft와 mRight가 교차하지 않을 때 경우까지 반복한다. */
{
while (mArr[mLeft] < pivot) { ++mLeft; } /* pivot 보다 큰 값을 찾는 경우 */
while (mArr[mRight] > pivot) { --mRight; } /* pivot 보다 큰 값을 찾는 경우 */
if (mLeft <= mRight) /* mLeft 보다 mRight가 값이 크거나 같은 경우 */
{
SWAP(mArr[mLeft], mArr[mRight], mTemp); /* mLeft와 mRight 값을 교환한다. */
++mLeft, --mRight; /* mLeft 증가, mRight 감소 */
}
}
if (left < mRight) { QuickSort(mArr, left, mRight); }
if (mLeft < right) { QuickSort(mArr, mLeft, right); }
}func QuickSort(array: inout [Int], left: Int, right: Int) {
var mLeft = left, mRight = right
let pivot: Int = array[(left + right) / 2]
while mLeft <= mRight {
while array[mLeft] < pivot { mLeft = mLeft + 1 }
while array[mRight] > pivot { mRight = mRight - 1 }
if mLeft <= mRight {
array.swapAt(mLeft, mRight)
mLeft = mLeft + 1
mRight = mRight - 1
}
}
if left < mRight { QuickSort(array: &array, left: left, right: mRight) }
if mLeft < right { QuickSort(array: &array, left: mLeft, right: right) }
}- In computer science, merge sort (also commonly spelled mergesort) is an efficient, general-purpose, comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the order of equal elements is the same in the input and output. Merge sort is a divide and conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up mergesort appeared in a report by Goldstine and von Neumann as early as 1948.
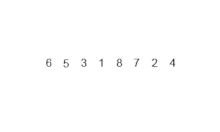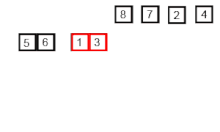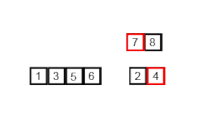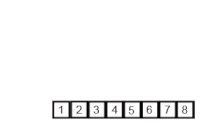
- 합병 정렬 또는 병합 정렬(merge sort)은 O(n log n) 비교 기반 정렬 알고리즘이다. 일반적인 방법으로 구현했을 때 이 정렬은 안정 정렬에 속하며, 분할 정복 알고리즘의 하나이다. 존 폰 노이만이 1945년에 개발했다.
-
리스트의 길이가 0 또는 1이면 이미 정렬된 것으로 본다. 그렇지 않은 경우에는 정렬되지 않은 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
-
각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
-
두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.
void mergeTwoArea(vector<int> & arr, int left, int mid, int right) {
// fIdx와 rIdx에는 각각 병합할 두 영역의 첫 번째 위치정보가 담긴다. (fIdx = Left Array, rIdx = Right Array)
int fIdx = left, rIdx = mid + 1;
// 병합 한 결과를 담을 Vector
vector<int> sortArr;
// 병합 할 두 영역의 데이터들을 비교하여, 정렬순서대로 Vector에 하나씩 옮겨 담는다.
while (fIdx <= mid && rIdx <= right) {
if (arr[fIdx] <= arr[rIdx]) { sortArr.push_back(arr[fIdx++]); }
else { sortArr.push_back(arr[rIdx++]); }
}
if (fIdx > mid) {
// 배열의 앞 부분이 모두 Vector에 옮겨졌다면, 배열의 뒷 부분에 남은 데이터들을 Vector에 그대로 옮긴다.
for (int ii = rIdx; ii <= right; ii++) { sortArr.push_back(arr[ii]); }
}
else {
// 배열의 뒷 부분이 모두 Vector에 옮겨졌다면, 배열의 앞 부분에 남은 데이터들을 Vector에 그래도 옮긴다.
for (int ii = fIdx; ii <= mid; ii++) { sortArr.push_back(arr[ii]); }
}
for (int ii = left, jj = 0; ii <= right; ii++, jj++) { arr[ii] = sortArr[jj]; }
}
void mergeSort(vector<int> & arr, int left, int right) {
// 배열의 중간 지점 인덱스를 구한다.
const int mid = (left + right) / 2;
if (left < right) {
mergeSort(arr, left, mid); // [Left Index ~ Mid Index] 분할한다.
mergeSort(arr, mid + 1, right); // [Mid Index ~ Right Index] 분할한다.
// 분할 된 두 배열을 하나로 병합한다.
mergeTwoArea(arr, left, mid, right);
}
}- 스택(stack)은 제한적으로 접근할 수 있는 나열 구조이다. 그 접근 방법은 언제나 목록의 끝에서만 일어난다. 끝먼저내기 목록(Pushdown list)이라고도 한다.

- 스택은 한 쪽 끝에서만 자료를 넣거나 뺄 수 있는 선형 구조(LIFO - Last In First Out)으로 되어 있다. 자료를 넣는 것을 '밀어넣는다' 하여 푸시(push)라고 하고 반대로 넣어둔 자료를 꺼내는 것을 팝(pop)이라고 하는데, 이때 꺼내지는 자료는 가장 최근에 보관한 자료부터 나오게 된다. 이처럼 나중에 넣은 값이 먼저 나오는 것을 LIFO 구조라고 한다.

-
큐(queue)는 컴퓨터의 기본적인 자료 구조의 한가지로, 먼저 집어 넣은 데이터가 먼저 나오는 FIFO (First In First Out)구조로 저장하는 형식을 말한다. 영어 단어 queue는 표를 사러 일렬로 늘어선 사람들로 이루어진 줄을 말하기도 하며, 먼저 줄을 선 사람이 먼저 나갈 수 있는 상황을 연상하면 된다. 나중에 집어 넣은 데이터가 먼저 나오는 스택과는 반대되는 개념이다.
-
프린터의 출력 처리나 윈도 시스템의 메시지 처리기, 프로세스 관리 등 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에 이용된다.
※ Queue Swift Source Code
public struct Queue<T> {
fileprivate var array = [T]()
public var front: T? { return array.first }
public var count: Int { return array.count }
public var isEmpty: Bool { return array.isEmpty }
public mutating func enqueue(_ element: T) { array.append(element) }
public mutating func dequeue() -> T? { return isEmpty ? nil : array.removeFirst() }
}양쪽 끝에서 삽입과 삭제가 모두 가능한 자료 구조의 한 형태이다. 두 개의 포인터를 사용하여, 양쪽에서 삭제와 삽입을 발생 시킬 수 있다.
-
스크롤 (Scroll) - 입력이 한쪽 끝으로만 가능하도록 설정한 데크 (입력 제한 데크)
-
셸프 (Self) - 출력이 한쪽 끝으로만 가능하도록 설정한 데크 (출력 제한 데크)

- 게임 서버는 클라이언트에서 보낸 패킷을 차례대로 처리합니다. 서버에서 네트워크 데이터를 받는 함수에서 데이터를 받으면 패킷으로 만든 후 받은 순서대로 순차적으로 처리합니다. 이렇게 순차적으로 저장한 패킷을 처리할 때는 deque가 가장 적합한 자료구조입니다. 다만, 실제 현업에서는 이 부분에 STL의 deque를 사용하지 않는 경우가 종종 있습니다. 이유는 네트워크에서 데이터를 받아 패킷으로 만들어 저장하고, 그 패킷을 처리하는 부분은 게임 서버의 성능 면에서 가장 중요한 부분이므로 deque보다 더 빠르게 처리하기를 원하므로 독자적인 자료구조를 만들어 사용합니다(즉, 범용성보다는 성능을 우선시합니다).
- 크기가 가변적이다.
- 앞과 뒤에서 삽입과 삭제가 좋다.
- 중간에 데이터 삽입, 삭제가 용이하지 않다.
- 구현이 쉽지 않다.
- 랜덤 한 접근이 가능하다.
A circular buffer, circular queue, cyclic buffer or ring buffer is a data structure that uses a single, fixed-size buffer as if it were connected end-to-end. This structure lends itself easily to buffering data streams.

increment_address_one = (address + 1) % Length
decrement_address_one = (address + Length - 1) % Length- 트리 구조(tree 構造, 문화어: 나무구조)란 그래프의 일종으로, 여러 노드가 한 노드를 가리킬 수 없는 구조이다. 간단하게는 회로가 없고, 서로 다른 두 노드를 잇는 길이 하나뿐인 그래프를 트리라고 부른다.
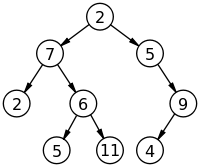
- 트리에서 최상위 노드를 루트 노드(root node 뿌리 노드[])라고 한다. 또한 노드 A가 노드 B를 가리킬 때 A를 B의 부모 노드(parent node), B를 A의 자식 노드(child node)라고 한다. 자식 노드가 없는 노드를 잎 노드(leaf node 리프 노드[])라고 한다. 잎 노드가 아닌 노드를 내부 노드(internal node)라고 한다.
- 각각의 노드가 최대 두 개의 자식 노드를 가지는 트리 자료 구조로, 자식 노드를 각각 왼쪽 자식 노드와 오른쪽 자식 노드라고 한다. 단순히 집합론의 개념을 사용하는 재귀적 정의에서 (비어있지 않은) 이진 트리는 하나의 튜플 (L, S, R)로, L과 R은 이진 트리 또는 공집합이고 S는 싱글턴 집합이다. 일부 구현자는 공집합인 이진 트리도 허용한다.

-
B+ 트리(Quaternary Tree라고도 알려져 있음)는 컴퓨터 과학용어로, 키에 의해서 각각 식별되는 레코드의 효율적인 삽입, 검색과 삭제를 통해 정렬된 데이터를 표현하기 위한 트리자료구조의 일종이다.
이는 동적이며, 각각의 인덱스 세그먼트 (보통 블록 또는 노드라고 불리는) 내에 최대와 최소범위의 키의 개수를 가지는 다계층 인덱스(multilevel index)로 구성된다.
B트리와 대조적으로 B+트리는, 모든 레코드들이 트리의 가장 하위 레벨에 정렬되어있다. 오직 키들만이 내부 블록에 저장된다. -
The difference between a B and B+ tree is that, in a B-tree, the keys and data can be stored in both the internal and leaf nodes, whereas in a B+ tree, the data and keys can only be stored in the leaf nodes.
-
A B+ tree is the same as a B tree; the only difference is that, in the B+ tree there is an additional level added at the bottom with linked leaves. Also, unlike the B tree, each node in a B+ tree contains only keys and not key–value pairs.

-
In computer science, a trie, also called digital tree, radix tree or prefix tree, is a kind of search tree—an ordered tree data structure used to store a dynamic set or associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the key with which it is associated. All the descendants of a node have a common prefix of the string associated with that node, and the root is associated with the empty string. Keys tend to be associated with leaves, though some inner nodes may correspond to keys of interest. Hence, keys are not necessarily associated with every node. For the space-optimized presentation of prefix tree, see compact prefix tree.
-
컴퓨터 과학에서 디지털 트리, 기수 트리 또는 접두사 트리라고도하는 트리는 일종의 검색 트리로, 키가 일반적으로 문자열 인 동적 세트 또는 연관 배열을 저장하는 데 사용되는 정렬 트리 데이터 구조입니다. 이진 검색 트리와 달리 트리의 노드는 해당 노드와 관련된 키를 저장하지 않습니다. 대신 트리에서의 위치는 연관된 키를 정의합니다. 노드의 모든 하위 항목에는 해당 노드와 연관된 문자열의 공통 접두사가 있으며 루트는 빈 문자열과 연관됩니다. 일부 내부 노드는 트리의 계층과 연관이 있는 키에 해당 할 수 있지만 키는 단말 노드와 연관되는 경향이 있습니다. 따라서 키가 반드시 모든 노드와 연관 될 필요는 없습니다.
/* Trie의 각 노드들은 MAX_LEN 만큼의 자식노드들을 가질 수 있다. */
#define MAX_LEN 26
#define TO_NUMBER(X) X - 'A'
/* Trie의 하나의 노드를 나타내는 객체 */
typedef struct TrieNode {
/* 해당 노드가 종료 노드인지 확인하는 변수 */
bool terminal = false;
TrieNode * children[MAX_LEN];
TrieNode() { memset(children, 0, sizeof(children)); }
~TrieNode() {
for (int index = 0; index < MAX_LEN; index++) {
if (children[index]) { delete children[index]; }
}
}
/* 이 노드를 루트로 하는 Trie에 문자열 Key를 추가한다. */
void insert(const char * key) {
// 문자열이 끝나면 종료 노드임을 표시
if (*key == 0) { terminal = true; }
else {
const int next = TO_NUMBER(*key);
// 해당 자식 노드가 없으면 생성한다.
if (children[next] == NULL) { children[next] = new TrieNode(); }
children[next]->insert(key + 1); // 해당 자식 노드를 재귀로 호출한다.
}
}
/* 이 노드를 루트로 하는 Trie에 문자열 Key와 대응되는 노드를 찾고 없는경우 NULL을 반환한다. */
TrieNode* find(const char * key) {
if (*key == 0) { return this; }
const int next = TO_NUMBER(*key);
if (children[next] == NULL) { return NULL; } // 문자열 Key와 대응되는 노드를 찾기 못한 경우
return children[next]->find(key + 1); // 문자열 Key와 대응되는 노드를 찾은 경우
}
} Trie;
void printWord(string & contents, const Trie * node) {
if (node->terminal) { cout << contents << endl; return; }
for (int ii = 0; ii < MAX_LEN; ii++) {
if (node->children[ii]) {
contents.push_back(ii + 'A');
printWord(contents, node->children[ii]);
contents.pop_back();
}
}
}

- In computer science, a segment tree also known as a statistic tree is a tree data structure used for storing information about intervals, or segments. It allows querying which of the stored segments contain a given point. It is, in principle, a static structure; that is, it's a structure that cannot be modified once it's built. A similar data structure is the interval tree.
#include <vector>
#include <cstdio>
#include <climits>
#include <iostream>
#include <algorithm>
using namespace std;
#define INT_PAIR pair<int, int>
/* Segment Tree: 저장 된 자료들을 적절히 전처리하여 그들에 대한 질의들을 빠르게 대답할 수 있는 트리 */
typedef struct RMQ {
int length = 0; // 배열의 길이를 저장하는 변수
vector<int> rangeMin; // 각 구간의 최소치를 저장하는 배열
RMQ(const vector<int> & arr) {
this->length = arr.size();
this->rangeMin.resize(this->length * 4);
this->init(arr, 0, length - 1, 1);
}
// Node 노드가 Array[left..right] 배열을 표현할 때, Node를 루트로 하는 서브트리를 초기화하고, 이 구간의 최소치를 반환한다.
const int init(const vector<int> & arr, int left, int right, int node) {
/* 현재 구간을 두 개로 나누어 재귀 호출한 뒤, 두 구간의 최소치 중 더 작은 값을 선택하여 해당 구간의 최소치를 계산한다. */
/* 터미널 노드 (Leaf node, a node of a tree data structure that has no child nodes.)일 경우 */
if (left == right) { return (this->rangeMin[node] = arr[left]); }
const int mid = (left + right) / 2;
const int leftMin = init(arr, left, mid, node * 2);
const int rightMin = init(arr, mid + 1, right, node * 2 + 1);
/* 구간 합 또는 곱으로 구현하고 싶은 경우에는 return this->rangeMin[node] = init(arr, left, mid, node * 2) + init(arr, mid + 1, right, node * 2 + 1)로 변경한다. */
return this->rangeMin[node] = min(leftMin, rightMin); // Time Complxity - log(n)
}
private:
// Node가 표현하는 범위 [NodeLeft, NodeRight]와 우리가 최소치를 찾기 원하는 구간 [left, right]의 교집합의 최소 원소를 반환한다.
const int query(int left, int right, int node, int nodeLeft, int nodeRight) {
// 두 구간이 겹치지 않으면 아주 큰 값을 반환한다. (교집합이 공집합인 경우)
if (right < nodeLeft || nodeRight < left) { return INT_MAX; } /* 구간 합 또는 곱으로 변경시 1 또는 0으로 */
// Node가 표현하는 범위 Array[nodeLeft, NodeRight]에 완전히 포함되는 경우
if (left <= nodeLeft && nodeRight <= right) { return this->rangeMin[node]; }
// 이 외의 모든 경우 (양쪽 구간을 나누어서 푼 뒤 결과를 합친다.)
const int mid = (nodeLeft + nodeRight) / 2;
return min(query(left, right, node * 2, nodeLeft, mid), query(left, right, node * 2 + 1, mid + 1, nodeRight));
} // 노드가 표현하는 구간이 찾고자하는 구간에 완전히 포함되거나 아예 겹쳐지지 않는 경우에는 탐색을 종료한다.
// Array[Index] = newValue로 바뀌었을 때 node를 루트로 하는 구간 트리를 갱신하고 노드가 표현하는 구간의 최소치를 반환한다.
const int update(int index, int newValue, int node, int nodeLeft, int nodeRight) {
// Index가 노드가 표현하는 구간과 상관이 없는 경우
if (index < nodeLeft || index > nodeRight) { return this->rangeMin[node]; }
/* 터미널 노드 (Leaf node, a node of a tree data structure that has no child nodes.)일 경우 */
if (nodeLeft == nodeRight) { return this->rangeMin[node] = newValue; }
const int mid = (nodeLeft + nodeRight) / 2;
/* 구간 합 또는 곱으로 변경시에는 update(index, newValue, node * 2, nodeLeft, mid) + update(index, newValue, node * 2 + 1, mid + 1, nodeRight) 로 변경한다. */
return rangeMin[node] = min(update(index, newValue, node * 2, nodeLeft, mid), update(index, newValue, node * 2 + 1, mid + 1, nodeRight));
}
public:
const int query(int left, int right) { return this->query(left, right, 1, 0, length - 1); } // Time Complxity - log(n)
const int update(int index, int newValue) { return this->update(index, newValue, 1, 0, length - 1); }
} RMQ;- 깊이 우선 탐색(depth-first search: DFS)은 맹목적 탐색방법의 하나로 탐색트리의 최근에 첨가된 노드를 선택하고, 이 노드에 적용 가능한 동작자 중 하나를 적용하여 트리에 다음 수준(level)의 한 개의 자식노드를 첨가하며, 첨가된 자식 노드가 목표노드일 때까지 앞의 자식 노드의 첨가 과정을 반복해 가는 방식이다.

| 😺 장점 | 😿 단점 |
|---|---|
| 현 경로상의 노드들만을 기억하면 되므로 저장 공간의 수요가 비교적 적다. | 해가 없는 경로에 깊이 빠질 가능성이 있다. 따라서 실제의 경우 미리 지정한 임의의 깊이까지만 탐색하고 목표노드를 발견하지 못하면 다음의 경로를 따라 탐색하는 방법이 유용할 수 있다. |
| 목표노드가 깊은 단계에 있을 경우 해를 빨리 구할 수 있다. | 얻어진 해가 최단 경로가 된다는 보장이 없다. 이는 목표에 이르는 경로가 다수인 문제에 대해 깊이우선 탐색은 해에 다다르면 탐색을 끝내버리므로, 이때 얻어진 해는 최적이 아닐 수도 있다. |
void recalsiveDFS(int index, int length) {
isVisit[index] = true;
cout << index << endl;
for (int ii = 0; ii < length; ii++) {
if (!isVisit[ii] && vertaxs[index][ii] == 1) { recalsiveDFS(ii, length); }
}
}void stackDFS(int index, int length) {
stack<int> stx;
stx.push(index);
isVisit[index] = true;
while (!stx.empty()) {
const int box = stx.top(); stx.pop();
for (int ii = 0; ii < length; ii++) {
if (!isVisit[ii] && vertaxs[box][ii] == 1) {
stx.push(ii);
isVisit[ii] = true;
}
}
// Output
cout << box << endl;
}
}- 너비 우선 탐색(Breadth-first search, BFS)은 맹목적 탐색방법의 하나로 시작 정점을 방문한 후 시작 정점에 인접한 모든 정점들을 우선 방문하는 방법이다. 더 이상 방문하지 않은 정점이 없을 때까지 방문하지 않은 모든 정점들에 대해서도 너비 우선 검색을 적용한다. OPEN List 는 큐를 사용해야만 레벨 순서대로 접근이 가능하다.

void BFS(const int start, const int vertax) {
vector<bool> check = vector<bool>(vertax, true);
check[start] = false;
queue<int> que;
que.push(start);
while (!que.empty()) {
const int index = que.front();
que.pop();
cout << index << endl;
for (int ii = 0; ii < vertax; ii++) {
if (arr[index][ii] == 1 && check[ii]) {
check[ii] = false;
que.push(ii);
}
}
}
}- 컴퓨터 과학에서, 데이크스트라 알고리즘(영어: Dijkstra algorithm) 또는 다익스트라 알고리즘은 도로 교통망 같은 곳에서 나타날 수 있는 그래프에서 꼭짓점 간의 최단 경로를 찾는 알고리즘이다.

- 그래프에서 주어진 소스 꼭짓점에 대해서, 데이크스트라 알고리즘은 그 노드와 다른 모든 꼭짓점 간의 가장 짧은 경로를 찾는다.[4]:196–206 이 알고리즘은 어떤 한 꼭짓점에서 다른 한 도착점까지 가는 경로를 찾을 때, 그 도착점까지 가는 가장 짧은 경로가 결정되면 멈추는 식으로 사용할 수 있다. 예컨대 어떤 그래프에서, 꼭짓점들이 각각 도시를 나타내고, 변들이 도시 사이를 연결하는 도로의 길이를 나타낸다면, 데이크스트라 알고리즘을 통하여 두 도시 사이의 최단 경로를 찾을 수 있다. 따라서 최단 경로 알고리즘은 네트워크 라우팅 프로토콜에서 널리 이용되며, 특히 IS-IS (Intermediate System to Intermediate System)와 OSPF(Open Shortest Path First)에서 주로 사용된다. 또한 데이크스트라 알고리즘은 존슨 알고리즘 같은 알고리즘의 서브루틴으로 채택되었다.
-
모든 꼭짓점을 미방문 상태로 표시한다. 미방문 집합이라는 모든 미방문 꼭짓점의 집합을 만든다.
-
모든 꼭짓점에 시험적 거리 값을 부여한다: 초기점을 0으로, 다른 모든 꼭짓점을 무한대로 설정한다. 초기점을 현재 위치로 설정한다.
-
현재 꼭짓점에서 미방문 인접 꼭짓점을 찾아 그 시험적 거리를 현재 꼭짓점에서 계산한다. 새로 계산한 시험적 거리를 현재 부여된 값과 비교해서 더 작은 값을 넣는다. 예를 들어, 현재 꼭짓점 A의 거리가 6이라고 표시되었고, 인접 꼭짓점 B으로 연결되는 변의 길이가 2라고 한다면, A를 통한 B의 거리는 6 + 2 = 8이 될 것이다. B가 이전에 거리가 8보다 크다고 표시되었었다면 8로 바꾸고, 그렇지 않다면 그대로 놔둔다.
-
만약 현재 노드에 인접한 모든 미방문 꼭짓점을 계산했다면, 현재 꼭짓점을 방문한 것으로 표시하고 미방문 집합에서 제거한다. 방문한 꼭짓점은 이후에는 다시 검사하지 않는다.
-
도착점이 방문한 상태로 표시되거나 (특정 두 꼭짓점 사이의 경로를 계획하고 있을 때) 미방문 집합에 있는 꼭짓점들의 시험적 거리 중 최솟값이 무한대이면(완전 순회를 계획중일 때. 이 현상은 초기점과 나머지 미방문 집합 간에 연결이 없을 때 일어난다), 멈춘다. 알고리즘을 종료한다.
-
아니면 시험적 거리가 가장 작은 다음 미방문 꼭짓점을 새로운 "현재 위치"로 선택하고 3단계로 되돌아간다.
#define PAIR pair<int, int>
#define MAX_V 1001
/* 그래프 인접 리스트 (연결 된 정점 번호, 간선 가중치)의 쌍을 담는다. */
vector<PAIR> adj[MAX_V];
const vector<int> Dijkstra(const int vertax, const int start) {
vector<int> dist = vector<int>(vertax, INT_MAX);
dist[start] = 0;
priority_queue<PAIR> pq;
pq.push(make_pair(dist[start], start)); /* (Vertax Cost, Vertax Index) */
while (!pq.empty()) {
int cost = -pq.top().first; // Vertax Cost
int here = pq.top().second; // Vertax Index
pq.pop();
/* 만약 지금 꺼낸 것보다 더 짧은 경로를 알고 있는 경우 지금 꺼낸 것을 버린다. */
if (dist[here] < cost) { continue; }
/* 갈 수 있는 인접 한 정점들을 모두 검사한다. */
for (int index = 0; index < adj[here].size(); index++) {
int there = adj[here][index].first; // 현재 정점에서 연결 된 노드
int nextDist = cost + adj[here][index].second;
/* 다음 경로의 값보다 현재 경로가 작은 경우 Distance를 갱신하고 우선순위 큐에 저장한다. */
if (nextDist < dist[there]) {
dist[there] = nextDist;
pq.push(make_pair(-nextDist, there)); /* 음수를 붙이는 이유는 거리가 작은 정점으로 부터 꺼내질 수 있도로 하기 위함이다. */
}
}
}
return dist;
}
/* INPUT
for (size_t ii = 0; ii < edge; ii++) {
size_t start = 0, end = 0, weigth = 0;
scanf("%d %d %d", &start, &end, &weigth);
adj[start].push_back(make_pair(end, weigth));
}
*/- 프림 알고리즘(Prim's algorithm)은 가중치가 있는 연결된 무향 그래프의 모든 꼭짓점을 포함하면서 각 변의 비용의 합이 최소가 되는 부분 그래프인 트리, 즉 최소 비용 생성나무를 찾는 알고리즘이다.

-
그래프에서 하나의 꼭짓점을 선택하여 트리를 만든다.
-
그래프의 모든 변이 들어 있는 집합을 만든다.
-
모든 꼭짓점이 트리에 포함되어 있지 않은 동안 트리와 연결된 변 가운데 트리 속의 두 꼭짓점을 연결하지 않는 가장 가중치가 작은 변을 트리에 추가한다.
#define MAX_V 10001
#define PAIR pair<int, int>
vector<PAIR> adj[MAX_V];
int primAlgorithm(int vertax, int src) {
// 가중치의 합을 저장하는 변수
int ret = 0;
// 해당 정점이 트리에 포함 된 적이 있는지 확인하는 Vector
vector<bool> check = vector<bool>(vertax + 1, false);
check[src] = true; // 시작 할 정점을 시작점으로 트리에 가장 먼저 추가한다.
// 시작 할 정점에 연결 된 모든 노드들을 추가한다. <Weigth, Node>
priority_queue<PAIR> pq;
for (const PAIR edge : adj[src]) { pq.push(make_pair(-edge.second, edge.first)); }
while (!pq.empty()) {
PAIR edge = pq.top(); pq.pop();
// 해당 정점이 추가 된 노드인 경우는 건너뛴다.
if (check[edge.second]) { continue; }
ret += -edge.first; // 해당 정점까지의 가중치 합
check[edge.second] = true; // 해당 정점 추가 표시
// 정점에 인접 한 간선 검사한다.
int node = edge.second;
for (const PAIR edge : adj[node]) { pq.push(make_pair(-edge.second, edge.first)); }
}
return ret;
}#define MAX_V 101
#define PAIR pair<int, int>
vector<PAIR> adj[MAX_V];
int primAlgorithm(vector<PAIR> & selected, int vertax) {
selected.clear();
// 가중치의 합을 저장하는 변수
int ret = 0;
// 해당 정점이 트리에 포함 된 적이 있는지 확인하는 Vector
vector<bool> added(vertax, false);
// 트리에 인접한 간선 중 해당 정점에 닿는 최소 간선의 정보를 저장하는 Vector
vector<int> minWeight(vertax, INT_MAX), parent(vertax, EOF);
minWeight[0] = parent[0] = 0; // 0번 정점을 시작점으로 트리에 가장 먼저 추가한다.
for (int iter = 0; iter < vertax; iter++) {
// 다음에 트리에 추가할 정점 U를 찾는다.
int u = EOF;
for (int ii = 0; ii < vertax; ii++) {
if (!added[ii] && (u == -1 || minWeight[u] > minWeight[ii])) { u = ii; }
}
// 트리에 추가한다.
if (parent[u] != u) { selected.push_back(make_pair(parent[u], u)); }
ret += minWeight[u];
added[u] = true;
// U에 인접 한 간선 (U, V)들을 검사한다.
for (int ii = 0; ii < adj[u].size(); ii++) {
int v = adj[u][ii].first, weight = adj[u][ii].second;
if (!added[v] && minWeight[v] > weight) { minWeight[v] = weight; parent[v] = u; }
}
}
return ret;
}- 크러스컬 알고리즘(영어: Kruskal’s algorithm)은 최소 비용 생성나무를 찾는 알고리즘이다.

- Kruskal's algorithm is a minimum-spanning-tree algorithm which finds an edge of the least possible weight that connects any two trees in the forest.[1] It is a greedy algorithm in graph theory as it finds a minimum spanning tree for a connected weighted graph adding increasing cost arcs at each step. This means it finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized. If the graph is not connected, then it finds a minimum spanning forest (a minimum spanning tree for each connected component).

- 컴퓨터 과학에서, 플로이드-워셜 알고리즘(Floyd-Warshall Algorithm)은 변의 가중치가 음이거나 양인 (음수 사이클은 없는) 가중 그래프에서 최단 경로들을 찾는 알고리즘이다. 알고리즘을 한 번 수행하면 모든 꼭짓점 쌍 간의 최단 경로의 길이(가중치의 합)을 찾는다.
#define VECTOR vector<int>
// 그래프의 인접 행렬 (adj[u][v] = u에서 v로가는 간선의 가중치 값이며 간선이 없을 경우 무한 값을 넣는다.)
vector<VECTOR> adj;
// Graph에서의 모든 정점 사이의 최단 거리를 구하는 알고리즘 (시간복잡도 V^3, 공간복잡도 V^2)
void floyd(const int v) {
for (int ii = 0; ii < v; ii++) { adj[ii][ii] = 0; }
for (int kk = 0; kk < v; kk++) { // kk = 경유 노드
for (int ii = 0; ii < v; ii++) { // ii = 출발 노드
for (int jj = 0; jj < v; jj++) { // jj 도착 노드
// adj[ii][kk] (출발점에서 경유점)까지 갈 수 없거나 adj[kk][jj] (경유점에서 도착점)까지 갈 수 없는 경우는 버린다.
if (adj[ii][kk] == INT_MAX || adj[kk][jj] == INT_MAX) { continue; }
// adj[ii][jj] (출발점에서 도착점)까지의 거리 중 adj[ii][kk] (출발점에서 경유점) + adj[kk][jj] (경유점에서 도착점)까지의 거리의 값이 더 작은 경우 [ii][jj] 값을 갱신한다.
adj[ii][jj] = min(adj[ii][jj], adj[ii][kk] + adj[kk][jj]);
}
}
}
}| ⚡ Preorder Order | ⚡ Inorder Order | ⚡ Postorder Order |
|---|---|---|
 |
 |
 |
- 트리 구조에서 각각의 노드를 정확히 한 번만, 체계적인 방법으로 방문하는 과정을 말한다. 이는 노드를 방문하는 순서에 따라 분류된다.
typedef struct node {
char value;
struct node * reftChild;
struct node * rightChild;
node(const char val) {
this->value = val;
this->reftChild = NULL;
this->rightChild = NULL;
}
} Node;
- 노드를 방문한다.
- 왼쪽 서브 트리를 전위 순회한다.
- 오른쪽 서브 트리를 전위 순회한다.
/* Result: F->B->A->D->C->E->G->I->H*/
void preOrder(Node * node) {
if (node) {
cout << "※ PreOrder: " << node->value << endl;
preOrder(node->reftChild);
preOrder(node->rightChild);
}
}- 왼쪽 서브 트리를 중위 순회한다.
- 노드를 방문한다.
- 오른쪽 서브 트리를 중위 순회한다.
/* Result: Result: A->B->C->D->E->F->G->H->I */
void inOrder(Node * node) {
if (node) {
inOrder(node->reftChild);
cout << "※ InOrder: " << node->value << endl;
inOrder(node->rightChild);
}
}- 왼쪽 서브 트리를 후위 순회한다.
- 오른쪽 서브 트리를 후위 순회한다.
- 노드를 방문한다.
/* Result: Result: A->C->E->D->B->H->I->G->F */
void postOrder(Node * node) {
if (node) {
postOrder(node->reftChild);
postOrder(node->rightChild);
cout << "※ PostOrder: " << node->value << endl;
}
}- 레벨 순서 순회(level-order)는 모든 노드를 낮은 레벨부터 차례대로 순회한다.
- 레벨 순서 순회는 너비 우선 순회(breadth-first traversal)라고도 한다.
/* Result: F-B-G-A-D-I-C-E-H */
void leverOrder(Node * node) {
queue<Node*> que;
que.push(node);
while (!que.empty()) {
Node * child = que.front(); que.pop();
cout << "※ LevelOrder: " << child->value << endl;
if (child->reftChild) { que.push(child->reftChild); }
if (child->rightChild) { que.push(child->rightChild); }
}
}| 🚀 Github QR Code | 📝 Naver-Blog QR Code | 👓 Linked-In QR Code |
|---|---|---|
 |
 |
 |