Python
# This is a sample of Python script.
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
import os, sys, platform
print("\nPlatform:", platform.platform())
print("Python version: ", sys.version)
os.system('pip --version')
print("System path: ", os.environ.get('PATH'))
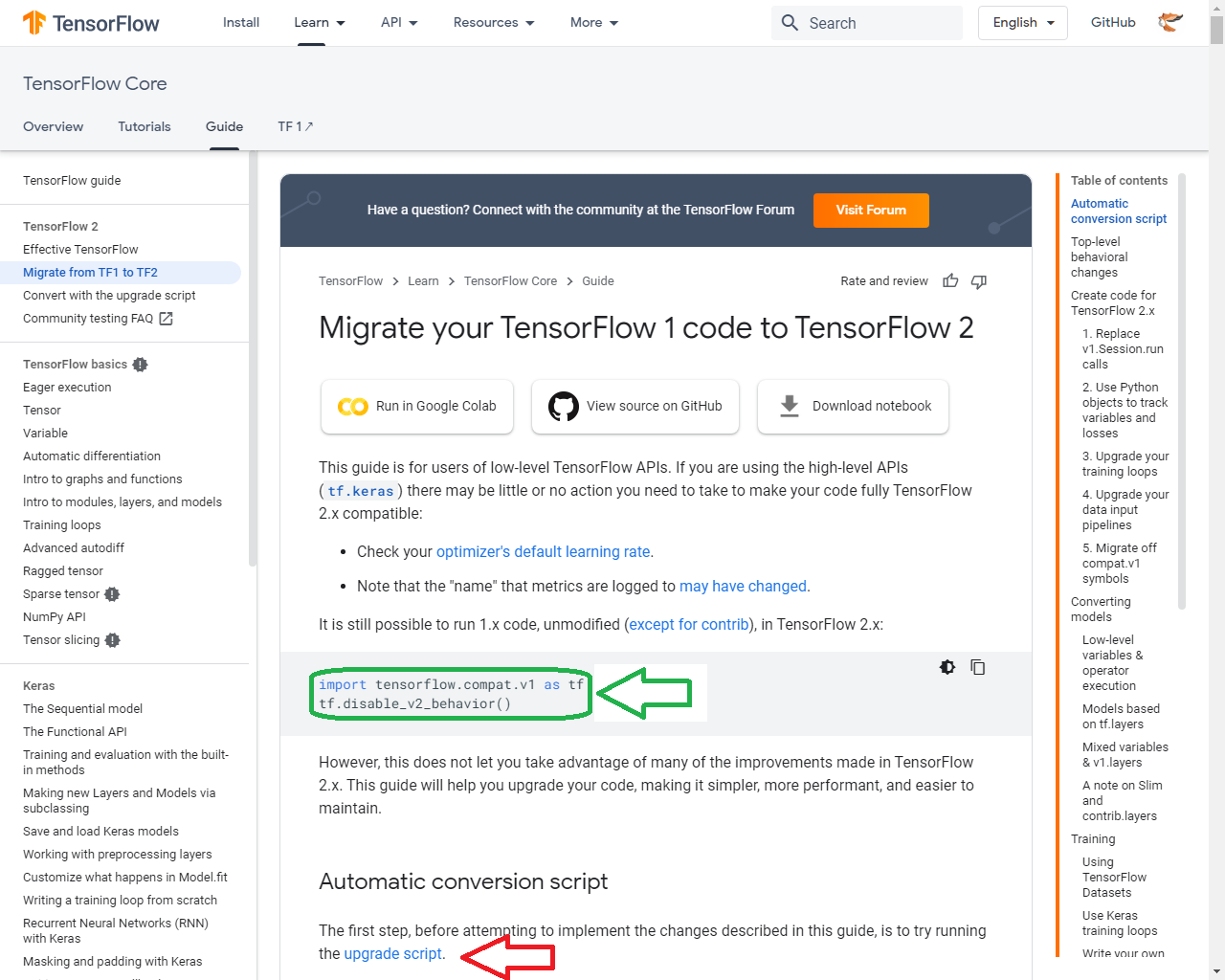
#Migrate your TensorFlow 1 code to TensorFlow 2
#https://www.tensorflow.org/guide/migrate
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
print("\nNum GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
print("Tensorflow version: ", tf.__version__)
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
x_train = [1.0, 2.0, 3.0, 4.0]
y_train = [-1.0, -2.0, -3.0, -4.0]
# Graph construction
# W and b are variables that our model will change
W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
b = tf.Variable(initial_value=[1.0], dtype=tf.float32)
# x is an input placeholder and y is a placeholder used to tell model what correct answers are
x = tf.placeholder(dtype=tf.float32)
y_input = tf.placeholder(dtype=tf.float32)
# y_output is the formula we are trying to follow to produce an output given input from x
y_output = W * x + b
# Loss function and optimizer aim to minimize the difference between actual and expected outputs (total sums)
loss = tf.reduce_sum(input_tensor=tf.square(x=y_output - y_input))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_step = optimizer.minimize(loss=loss)
# Sessions are used to evaluate the tensor value of a node or nodes
session = tf.Session()
session.run(tf.global_variables_initializer())
# Total loss before training
print("\nTotal kerugian sebelum training:", session.run(fetches=loss, feed_dict={x: x_train, y_input: y_train}))
# Training phase, run the train step 1000 times
for _ in range(1000):
session.run(fetches=train_step, feed_dict={x: x_train, y_input: y_train})
# Total loss and modified W and b values after training
print("Total kerugian setelah training:", session.run(fetches=[loss, W, b], feed_dict={x: x_train, y_input: y_train}))
# Test the model with some new values
print("Test kerugian dengan model baru:", session.run(fetches=y_output, feed_dict={x: [5.0, 10.0, 15.0]}))
Jika dalam proses muncul masalah python requirements dengan Microsoft Visual C++ v14.0 seperti dijelaskan dibawah ini silahkan lihat cara download dan instalnya di Visual-Studio.

# This is a sample of Python script.
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
import os, sys, platform
print("\nPlatform:", platform.platform())
print("Python version: ", sys.version)
os.system('pip --version')
print("System path: ", os.environ.get('PATH'))


#Migrate your TensorFlow 1 code to TensorFlow 2
#https://www.tensorflow.org/guide/migrate
import tensorflow as tf
import tensorflow.compat.v1 as v1
v1.disable_v2_behavior()


print("\nNum GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
print("Tensorflow version: ", tf.__version__)











import tensorflow as tf
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
x_train = [1.0, 2.0, 3.0, 4.0]
y_train = [-1.0, -2.0, -3.0, -4.0]
# Graph construction
# W and b are variables that our model will change
W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
b = tf.Variable(initial_value=[1.0], dtype=tf.float32)
# x is an input placeholder and y is a placeholder used to tell model what correct answers are
x = tf.placeholder(dtype=tf.float32)
y_input = tf.placeholder(dtype=tf.float32)
# y_output is the formula we are trying to follow to produce an output given input from x
y_output = W * x + b
# Loss function and optimizer aim to minimize the difference between actual and expected outputs (total sums)
loss = tf.reduce_sum(input_tensor=tf.square(x=y_output - y_input))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_step = optimizer.minimize(loss=loss)
# Sessions are used to evaluate the tensor value of a node or nodes
session = tf.Session()
session.run(tf.global_variables_initializer())
# Total loss before training
print("\nTotal kerugian sebelum training:", session.run(fetches=loss, feed_dict={x: x_train, y_input: y_train}))
# Training phase, run the train step 1000 times
for _ in range(1000):
session.run(fetches=train_step, feed_dict={x: x_train, y_input: y_train})
# Total loss and modified W and b values after training
print("Total kerugian setelah training:", session.run(fetches=[loss, W, b], feed_dict={x: x_train, y_input: y_train}))
# Test the model with some new values
print("Test kerugian dengan model baru:", session.run(fetches=y_output, feed_dict={x: [5.0, 10.0, 15.0]}))



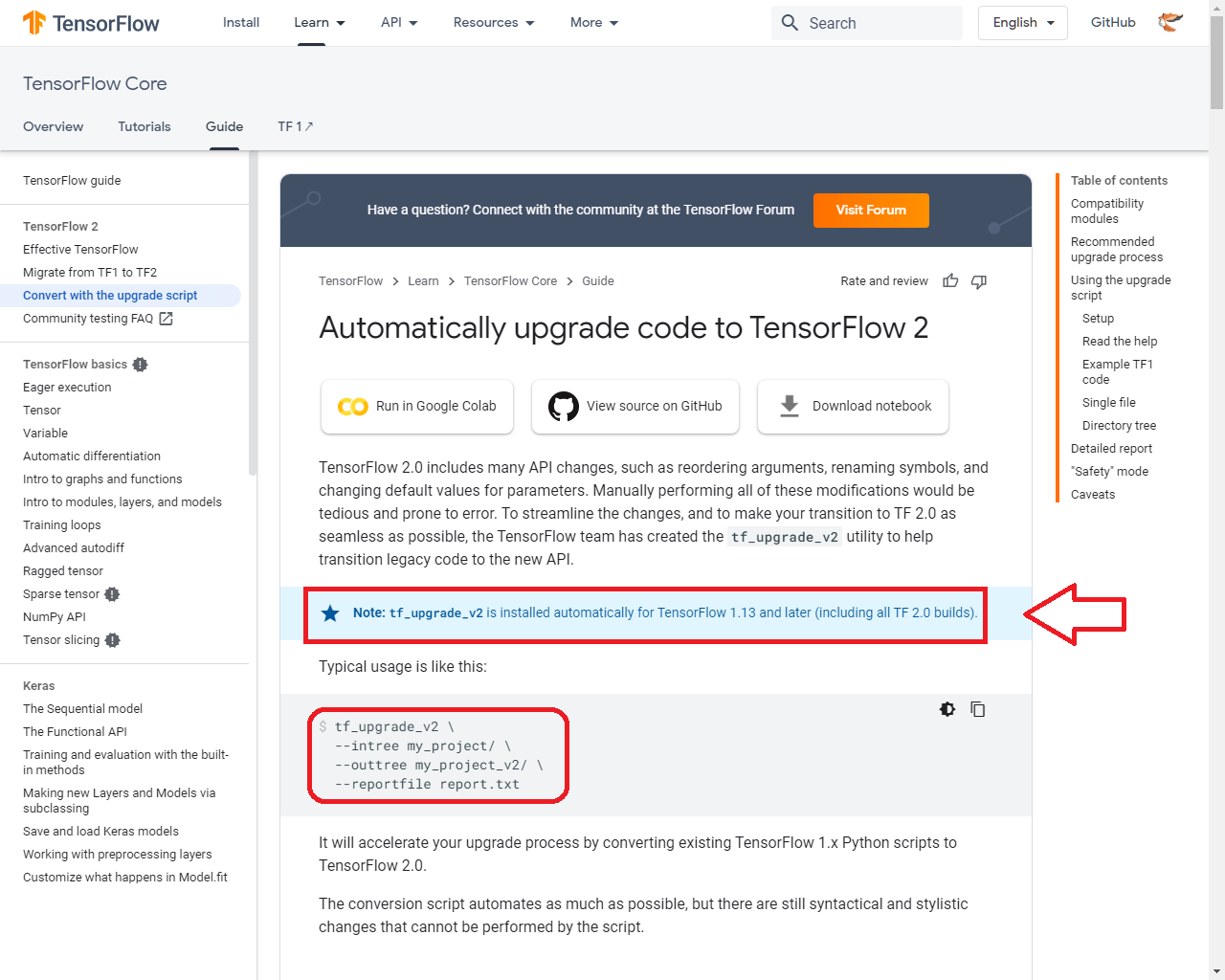
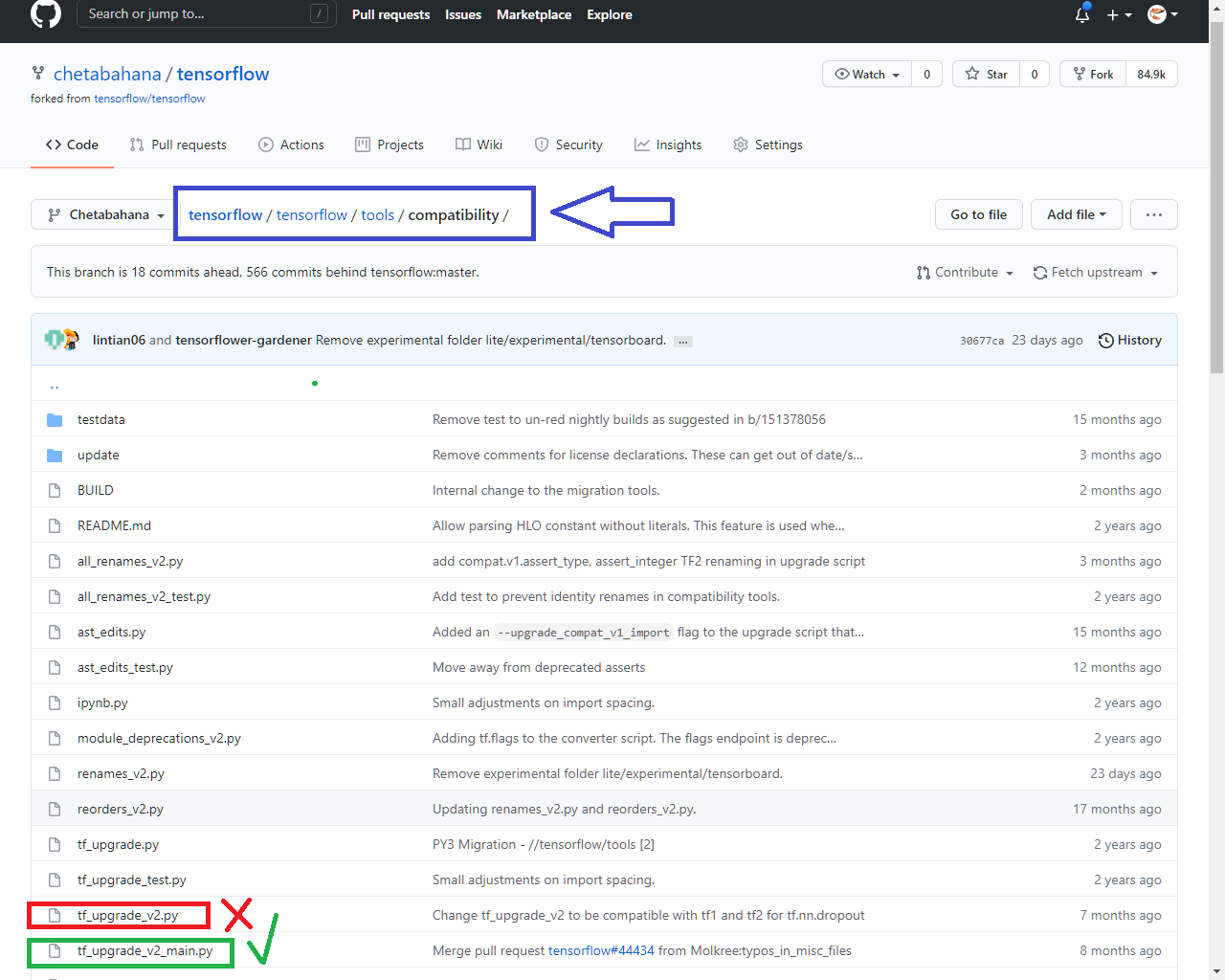
$ conda info --envs
$ conda activate tf250
(tf250)$python tf_upgrade_v2_main.py -h
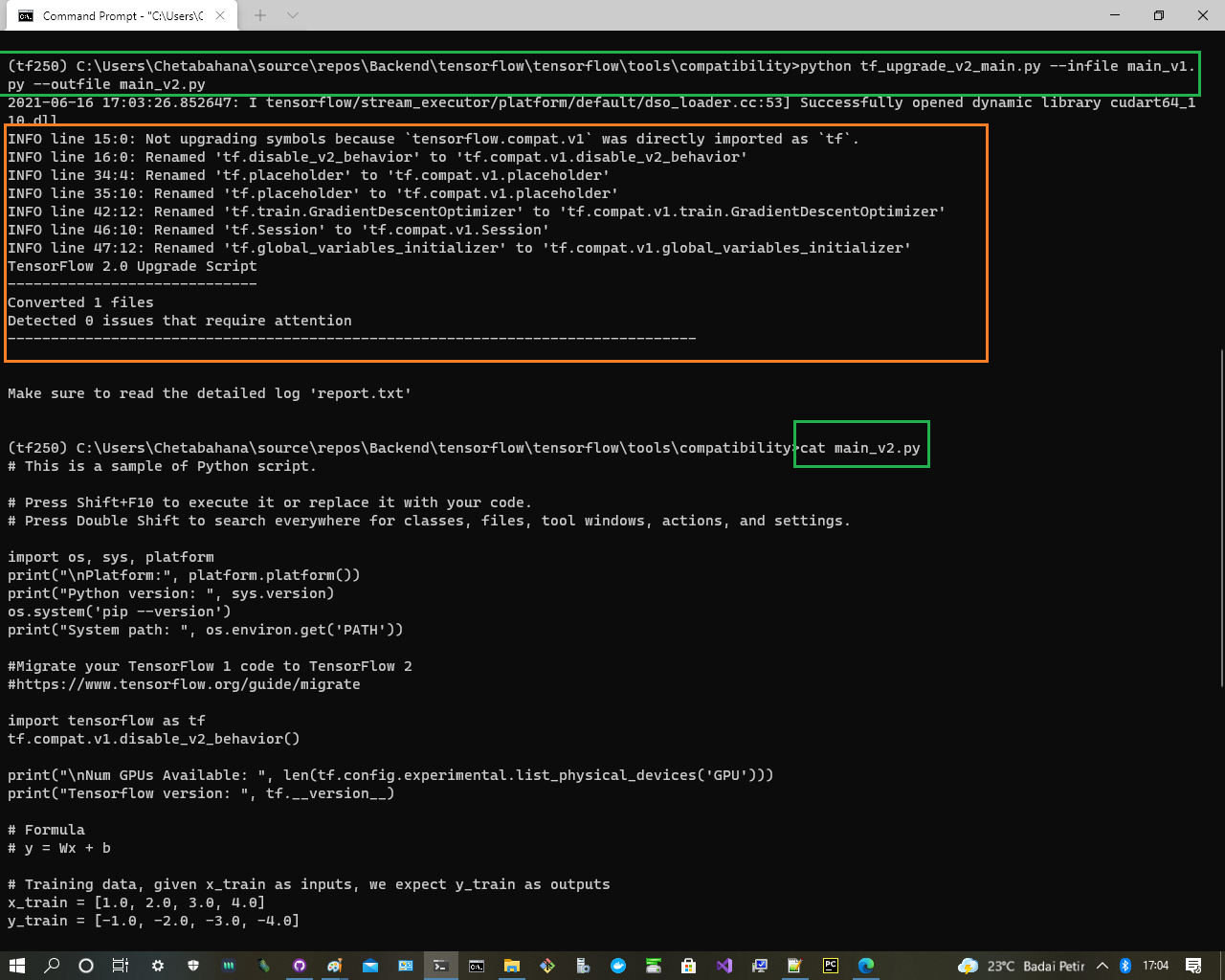
(tf250)$python tf_upgrade_v2_main.py --infile main_v1.py --outfile main_v2.py
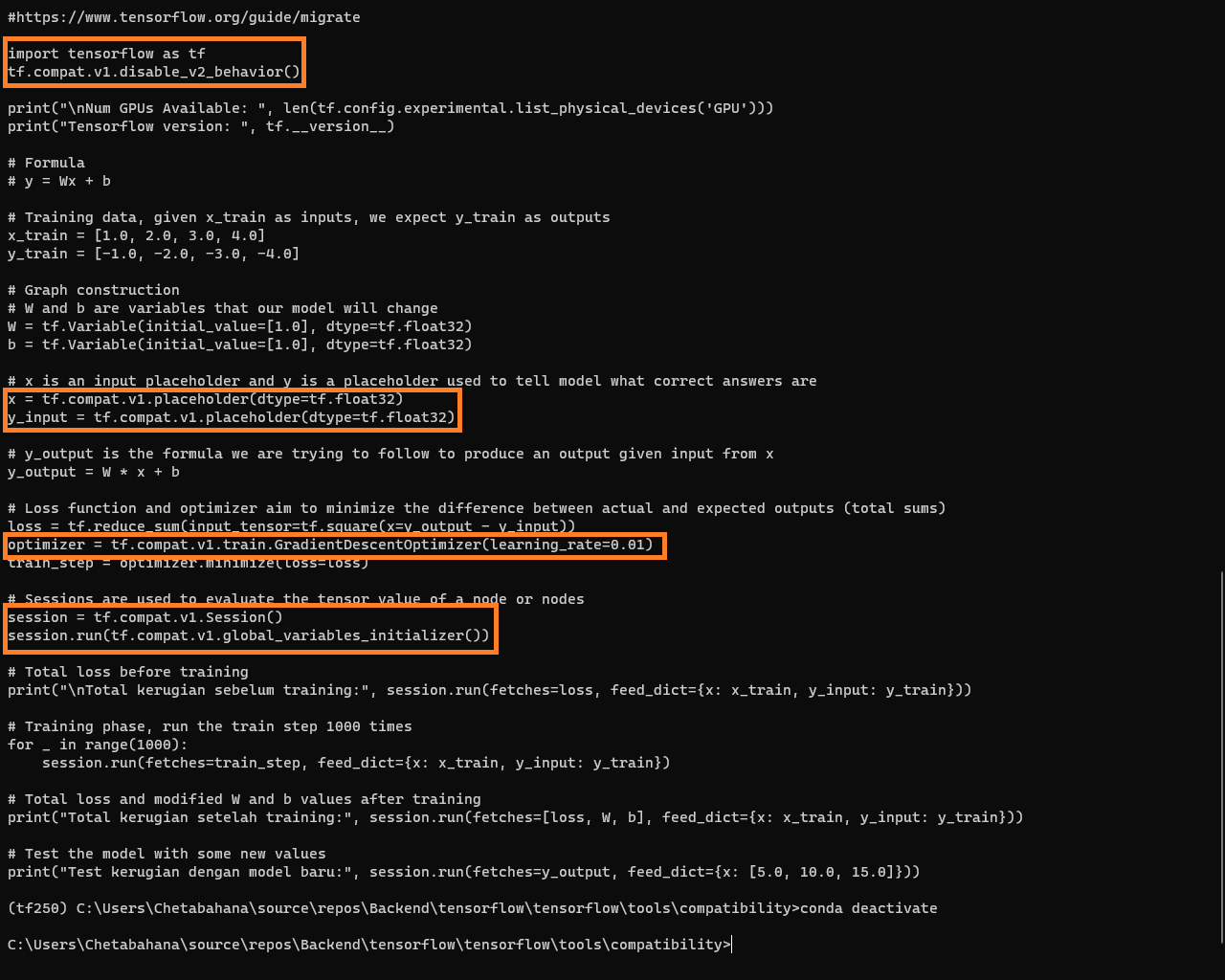
(tf250)$cat main_v2.py
(tf250)$conda deactivate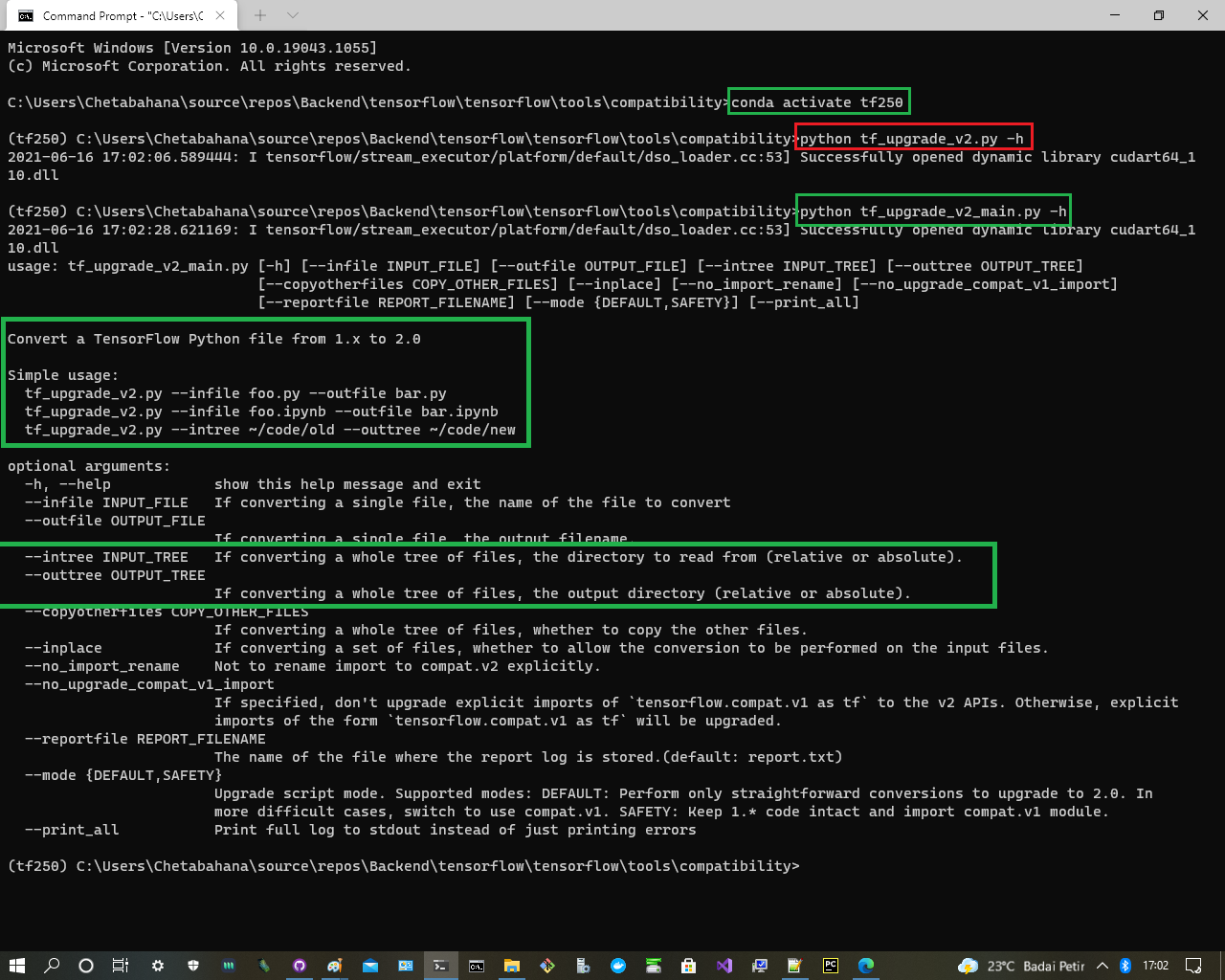
# This is a sample of Python script.
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
import os, sys, platform
print("\nPlatform:", platform.platform())
print("Python version: ", sys.version)
os.system('pip --version')
print("System path: ", os.environ.get('PATH'))
#Migrate your TensorFlow 1 code to TensorFlow 2
#https://www.tensorflow.org/guide/migrate
import tensorflow as tf
tf.compat.v1.disable_v2_behavior()
print("\nNum GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
print("Tensorflow version: ", tf.__version__)
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
x_train = [1.0, 2.0, 3.0, 4.0]
y_train = [-1.0, -2.0, -3.0, -4.0]
# Graph construction
# W and b are variables that our model will change
W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
b = tf.Variable(initial_value=[1.0], dtype=tf.float32)
# x is an input placeholder and y is a placeholder used to tell model what correct answers are
x = tf.compat.v1.placeholder(dtype=tf.float32)
y_input = tf.compat.v1.placeholder(dtype=tf.float32)
# y_output is the formula we are trying to follow to produce an output given input from x
y_output = W * x + b
# Loss function and optimizer aim to minimize the difference between actual and expected outputs (total sums)
loss = tf.reduce_sum(input_tensor=tf.square(x=y_output - y_input))
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01)
train_step = optimizer.minimize(loss=loss)
# Sessions are used to evaluate the tensor value of a node or nodes
session = tf.compat.v1.Session()
session.run(tf.compat.v1.global_variables_initializer())
# Total loss before training
print("\nTotal kerugian sebelum training:", session.run(fetches=loss, feed_dict={x: x_train, y_input: y_train}))
# Training phase, run the train step 1000 times
for _ in range(1000):
session.run(fetches=train_step, feed_dict={x: x_train, y_input: y_train})
# Total loss and modified W and b values after training
print("Total kerugian setelah training:", session.run(fetches=[loss, W, b], feed_dict={x: x_train, y_input: y_train}))
# Test the model with some new values
print("Test kerugian dengan model baru:", session.run(fetches=y_output, feed_dict={x: [5.0, 10.0, 15.0]}))

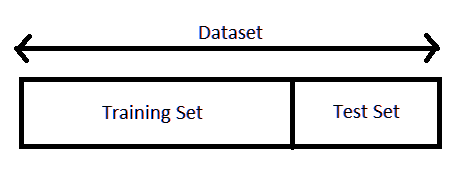
The training dataset is used to prepare a model, to train it. We pretend the test dataset is new data where the output values are withheld from the algorithm. We gather predictions from the trained model on the inputs from the test dataset and compare them to the withheld output values of the test set.
- Training Dataset adalah data yang kita siapkan sebagai model.
- Test Dataset adalah data baru yang outputnya sesuai dengan model.
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
x_train = [1.0, 2.0, 3.0, 4.0]
y_train = [-1.0, -2.0, -3.0, -4.0]
# Graph construction
# W and b are variables that our model will change
W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
b = tf.Variable(initial_value=[1.0], dtype=tf.float32)
# x is an input placeholder and y is a placeholder used to tell model what correct answers are
x = tf.compat.v1.placeholder(dtype=tf.float32)
y_input = tf.compat.v1.placeholder(dtype=tf.float32)
# y_output is the formula we are trying to follow to produce an output given input from x
y_output = W * x + b
import tensorflow as tf
a = tf.constant([[1, 2],
[3, 4]])
b = tf.constant([[1, 1],
[1, 1]]) # Could have also said `tf.ones([2,2])`
print(a + b, "\n") # element-wise addition
print(a * b, "\n") # element-wise multiplication
print(a @ b, "\n") # matrix multiplicationOutput:
tf.Tensor(
[[2 3]
[4 5]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[3 3]
[7 7]], shape=(2, 2), dtype=int32)


# This will be an int32 tensor by default; see "dtypes" below.
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)
# Output:
tf.Tensor(4, shape=(), dtype=int32)
# Let's make this a float tensor.
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
print(rank_1_tensor)
# Output:
tf.Tensor([2. 3. 4.], shape=(3,), dtype=float32)
# If you want to be specific, you can set the dtype (see below) at creation time
rank_2_tensor = tf.constant([[1, 2],
[3, 4],
[5, 6]], dtype=tf.float16)
print(rank_2_tensor)
# Output:
tf.Tensor(
[[1. 2.]
[3. 4.]
[5. 6.]], shape=(3, 2), dtype=float16)


# There can be an arbitrary number of
# axes (sometimes called "dimensions")
rank_3_tensor = tf.constant([
[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]],
[[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]],])
print(rank_3_tensor)
# Output:
tf.Tensor(
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]]
[[10 11 12 13 14]
[15 16 17 18 19]]
[[20 21 22 23 24]
[25 26 27 28 29]]], shape=(3, 2, 5), dtype=int32)import tensorflow as tf
#tf.compat.v1.disable_v2_behavior()
print("\nNum GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
print("Tensorflow version: ", tf.__version__)
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
#x_train = [1.0, 2.0, 3.0, 4.0]
#y_train = [-1.0, -2.0, -3.0, -4.0]
x_train = tf.constant([1.0, 2.0, 3.0, 4.0])
y_train = tf.constant([-1.0, -2.0, -3.0, -4.0])
print(x_train, "\n")
print(y_train, "\n")
# Graph construction
# W and b are variables that our model will change
W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
b = tf.Variable(initial_value=[1.0], dtype=tf.float32)

#x is an input placeholder and y is a placeholder used to tell model what correct answers are
x = tf.compat.v1.placeholder(dtype=tf.float32)
y_input = tf.compat.v1.placeholder(dtype=tf.float32)
# y_output is the formula we are trying to follow to produce an output given input from x
y_output = W * x + b


import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
x_train = [1.0, 2.0, 3.0, 4.0]
y_train = [-1.0, -2.0, -3.0, -4.0]
#x_train = tf.constant([1.0, 2.0, 3.0, 4.0])
#y_train = tf.constant([-1.0, -2.0, -3.0, -4.0])
print("x_train = ", x_train)
print("y_train = ", y_train, "\n")
# Graph construction
# W and b are variables that our model will change
W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
b = tf.Variable(initial_value=[1.0], dtype=tf.float32)
#x is an input placeholder and y is a placeholder used to tell model what correct answers are
x = tf.placeholder(dtype=tf.float32)
print("x = ", x)
y_input = tf.placeholder(dtype=tf.float32)
print("y_input = ", y_input, "\n")
print("W = ", W)
print("b = ", b, "\n")
# y_output is the formula we are trying to follow to produce an output given input from x
y_output = W * x + b
print("W * x = ", W * x)
print("y_output = ", y_output)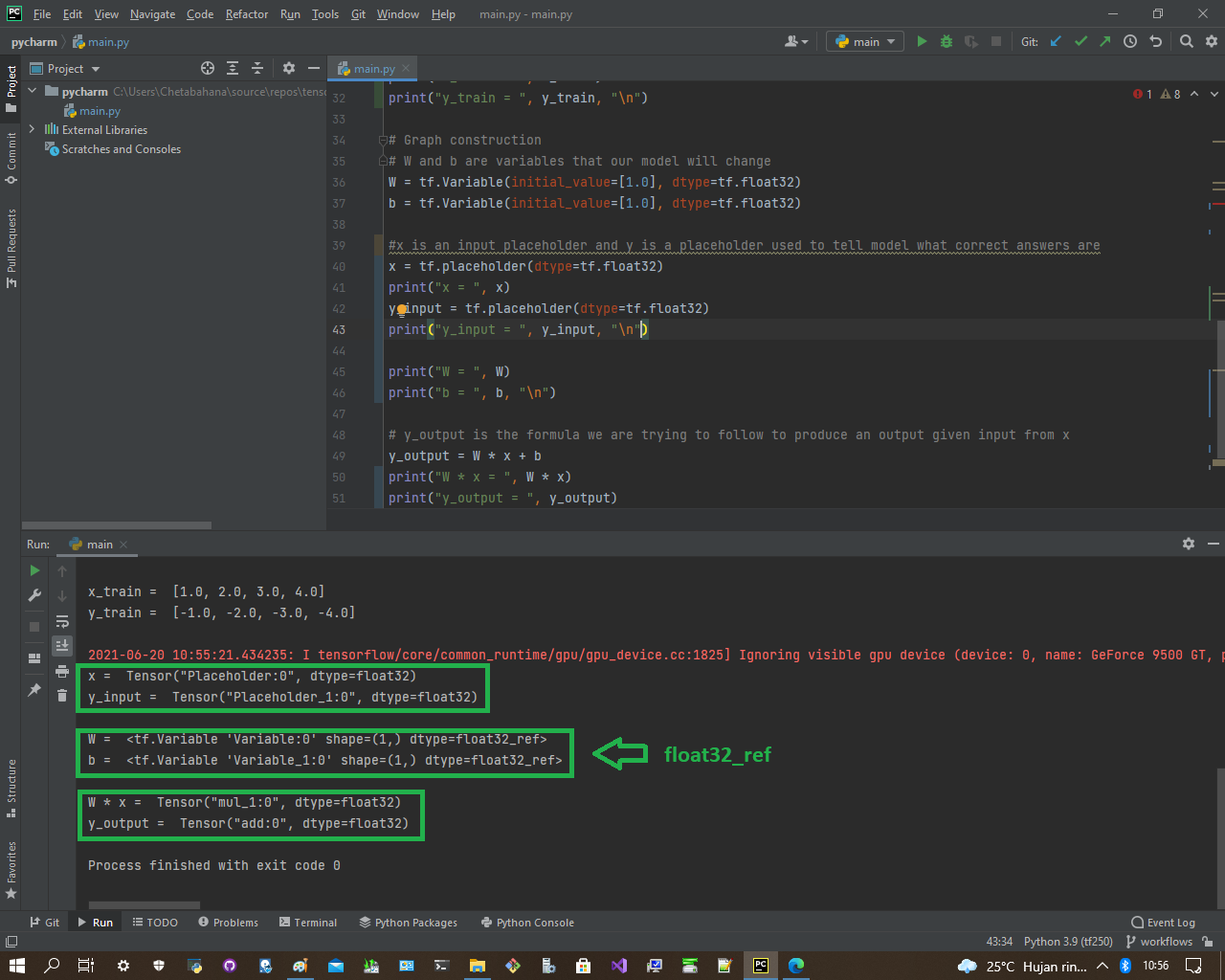
Sebelum konversi

Setelah konversi

import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
x_train = [1.0, 2.0, 3.0, 4.0]
y_train = [-1.0, -2.0, -3.0, -4.0]
# Graph construction
# W and b are variables that our model will change
W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
b = tf.Variable(initial_value=[1.0], dtype=tf.float32)
# x is an input placeholder and y is a placeholder used to tell model what correct answers are
x = tf.compat.v1.placeholder(dtype=tf.float32)
y_input = tf.compat.v1.placeholder(dtype=tf.float32)
# y_output is the formula we are trying to follow to produce an output given input from x
y_output = W * x + bhasil dari tf1
x = Tensor("Placeholder:0", dtype=float32)
y_input = Tensor("Placeholder_1:0", dtype=float32)
W = <tf.Variable 'Variable:0' shape=(1,) dtype=float32_ref>
b = <tf.Variable 'Variable_1:0' shape=(1,) dtype=float32_ref>
W * x = Tensor("mul_1:0", dtype=float32)
y_output = Tensor("add:0", dtype=float32)maka di tf2 yang kita jadikan rujukan adalah float32_ref yaitu W dan b
import tensorflow as tf
# Formula
# y = Wx + b
# Training data, given x_train as inputs, we expect y_train as outputs
#x_train = [1.0, 2.0, 3.0, 4.0]
#y_train = [-1.0, -2.0, -3.0, -4.0]
x_train = tf.constant([1.0, 2.0, 3.0, 4.0])
y_train = tf.constant([-1.0, -2.0, -3.0, -4.0])
print("x_train = ", x_train)
print("y_train = ", y_train, "\n")
# Graph construction
# W and b are variables that our model will change
#W = tf.Variable(initial_value=[1.0], dtype=tf.float32)
#b = tf.Variable(initial_value=[1.0], dtype=tf.float32)
W = tf.Variable(tf.zeros(shape=(1,)), name="W")
b = tf.Variable(tf.ones(shape=(1,)), name="b")
print("W = ", W)
print("b = ", b, "\n")
#x is an input placeholder and y is a placeholder used to tell model what correct answers are
#x = tf.placeholder(dtype=tf.float32)
#print("x = ", x)
#y_input = tf.placeholder(dtype=tf.float32)
#print("y_input = ", y_input, "\n")
# y_output is the formula we are trying to follow to produce an output given input from x
#y_output = W * x + b
@tf.function
def forward(x):
return W * x + b
y_output = forward(x_train)
print("y_output = ", y_output)

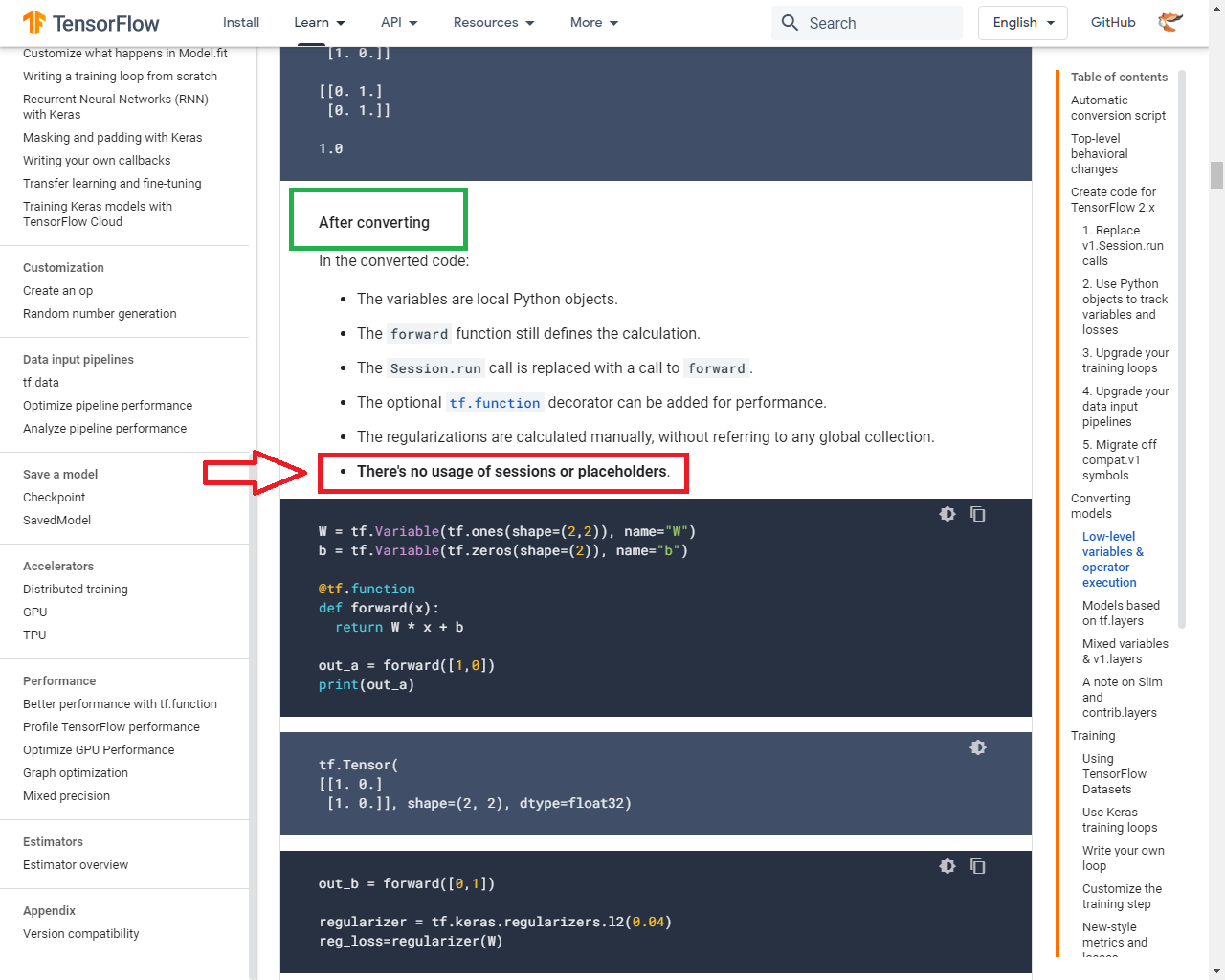
After converting
In the converted code:
- The variables are local Python objects.
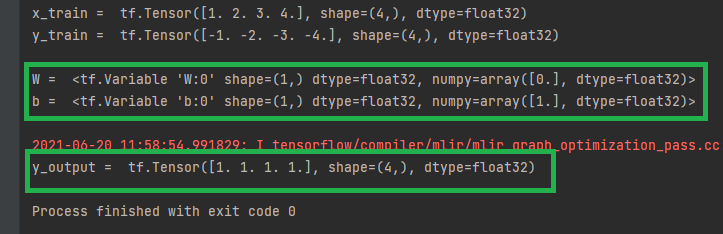
x_train = tf.Tensor([1. 2. 3. 4.], shape=(4,), dtype=float32)y_train = tf.Tensor([-1. -2. -3. -4.], shape=(4,), dtype=float32)y_output = tf.Tensor([1. 1. 1. 1.], shape=(4,), dtype=float32)
- The forward function still defines the calculation.
- menancapkan posisi x siap ditempat
- menggantikan fungsi y_input secara otomatis
- The Session.run call is replaced with a call to forward.
- akan dibahas di sesi berikut
- The optional tf.function decorator can be added for performance.
- ditto
- The regularizations are calculated manually, without referring to any global collection.
- ditto
- There's no usage of sessions or placeholders.
- tidak perlu lagi define
x = Tensor("Placeholder:0", dtype=float32) - tidak perlu juga define
y_input = Tensor("Placeholder_1:0", dtype=float32)
- tidak perlu lagi define
Silahkan cek Running Code di Google Lab:

- Training & evaluation with the built-in methods
- How to test the dataset if model was created on training dataset?
import math
import pandas_datareader as web
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
df = web.DataReader('AAPL', data_source='yahoo', start='2021-07-01', end='2021-07-20')
print(df)
print(df.shape[0])
plt.plot(figsize=(16,8))
plt.title('Close Price History')
plt.plot(df['Close'])
plt.xlabel('Data', fontsize=18)
plt.ylabel('Close Price USD($)', fontsize=18)
plt.show()
data = df.filter(['Close'])
print(data)
print(data.shape[0])
dataset = data.values
print('dataset -- numpy array')
print(dataset)
print(len(dataset))
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(dataset)
print(scaled_data)
print(len(scaled_data))
training_data_len = math.ceil ( len(dataset) * 0.8 ) # asli 22 row dataset dibikin jadi 18 row data_training
train_data = scaled_data[0:training_data_len , :] #print train data yg 18 row
print(train_data)
x_train = []
y_train = []
M=5
for i in range(M, len(train_data)):
x_train.append(train_data[i-M:i, 0]) #x_train : M_baris awal dari data_train
y_train.append(train_data[i, 0]) #y_train : satu baris ke M+1
if i<=M:
print(x_train)
print(y_train)
print()
x_train, y_train = np.array(x_train), np.array(y_train)
print(x_train)
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
print(x_train.shape)
from keras.models import Sequential
from keras.layers import Dense, LSTM
import tensorflow as tf
#Membangun model LSTM (Long Short Term Memory)
model = Sequential ()
model.add(LSTM(50, return_sequences=True, input_shape = (x_train.shape[1], 1)))
model.add(LSTM(50, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))