Cannot reuse same history list with different slices on different indicators #170
Comments
|
here a screenshot to show you current data that gets passed to the second indicator
|
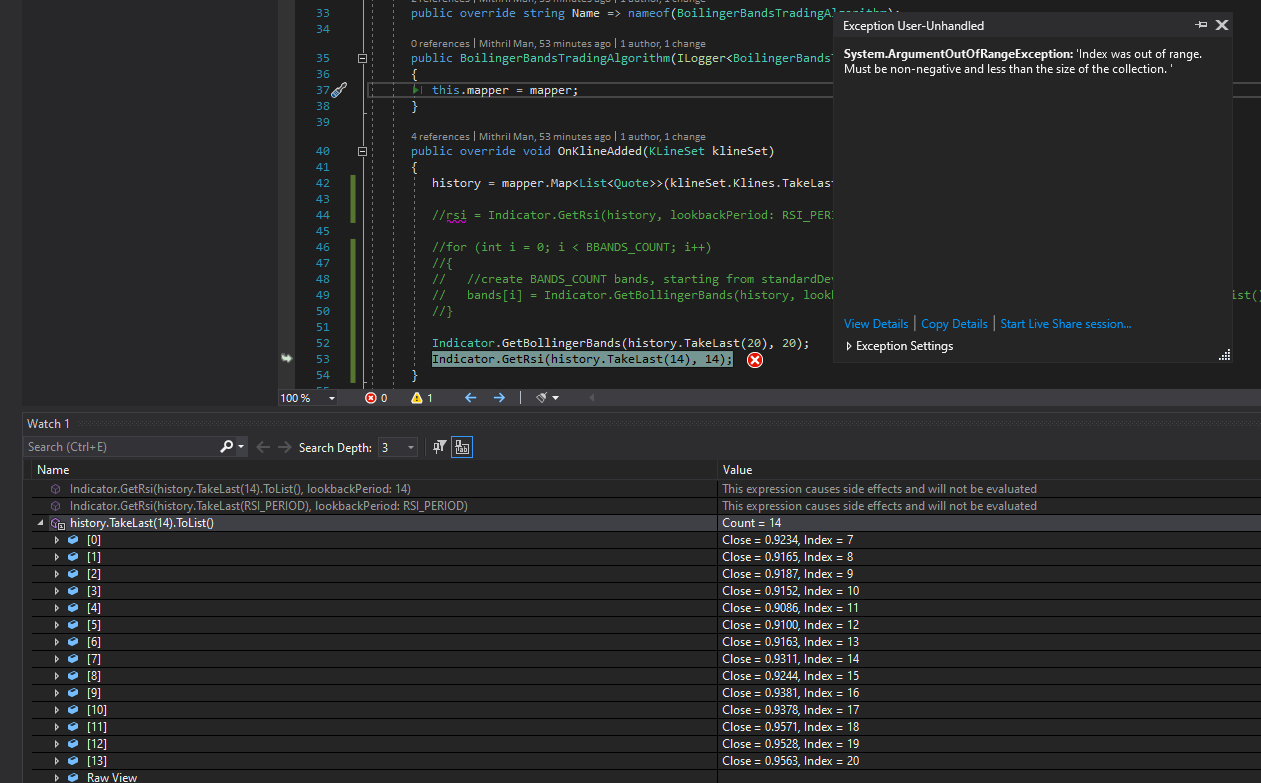
|
Yah, the Index number itself is important for locating the start of the dataset relative to the lookback period. Using For now, you might try to cut the results down instead of the input history. The difference in performance would be extremely small between 20 and 100 point datasets. Let me think about it. There’s likely both another workaround, so you can cut it like you depict, and perhaps a bug fix where we detect bad indexes and do a recompose. I’ll also consider options for dropping the Index altogether as well — can probably find a better way. |
An easy way before implementing a proper solution could be to implement an extension of that way I can use that extension like |
|
Another concern is that if you cut down history, you might not be able to restore it to a larger slice. The current quote cleaner will essentially “resave” it, I think, when recomposing new indices. It may take me a few days to review, but will probably get to it this weekend. If you want to submit a PR with a recommended fix, that’s also appreciated, only if you’re up to it. |
|
I see if I'll find time tomorrow after my daily job (3 am here), I need to take time to find the right place to put that extension on your codebase Note that I'm not cutting my history. The use case makes sense, anyway take your time for your considerations about it. |
|
If it’s not permanently cutting, I’ll probably just check the first Index number in the dataset in the PrepareHistory method. If it’s not 1, redo the Index. |
|
I think this fix will work fine. I need to add some unit tests to confirm when I have more time, and not writing code from my iPad :) |
|
As a side note, I’d recommend using more history for RSI anyway. It uses a convergence algorithm. Less history means less precision. If you compare 14 periods vs 250 periods of history for RSI(14) you’ll see small decimal point differences. Not much of an issue for most use cases, but worth pointing out. |
|
thanks for your tip, I'm now using 250 values to try it out Update |
|
I've added a fix to recompose the index if it detects a bad starting value. I'm also adding an undocumented This fix was implemented in version 1.0.6 |
|
cool thanks will test it |
|
ok I tested latest version (1.1.2) and the fix doesn't work
In your attempt to fix it, you check the wrong condition because as you see, when I use just a subset of my historical data and then try to use again the full history, I'm in a situation like the screenshot where I have anotehr Index = 1 in between, that of course make it crash. It's not enough to check if first index is 1 because you have to ensure that there aren't other index = 1 in between You can add a simple test as computing an indicator 3 times: full set, reduced set, full set |

|
also, what's the need of Index? but if we take for example the RSI implementation that uses the Index property, to me it can just make use of the for iteration variable Stock.Indicators/indicators/Rsi/Rsi.cs Line 38 in 873fc24 it's used like Stock.Indicators/indicators/Rsi/Rsi.cs Line 42 in 873fc24 but we already know that Index starts from 1 so that Index property has no meaning to me and for instance Stock.Indicators/indicators/Rsi/Rsi.cs Line 51 in 873fc24 is just |
|
Okay, I'll check that scenario. I worried that this might happen. I had a unit test to check for corruption for this use case and thought I had fixed it. For now, I'd avoid trying to mess with As a side note, I already have a plan (AB#763) to review and probably remove the use of Index internally. I just need to see if I can reasonably do that without causing other problems. |
I'm actually appending |
|
I think for this one, it's probably best for me to just revert the fix. It's better to get an error in this use case than to get corrupted data without an error. I'll leave the |
|
fine |
|
I'm closing this issue since it is remediated with the |
|
This Issue has been automatically locked since there has not been any recent activity after it was closed. Please open a new Issue for related bugs. |
Hello
I'm trying your library (thanks for the effort so far) and I've found a bug regarding the usage of the quotes to generate different indicators using the same set of historical quotes but taking a different slice of them
Debug was hard on my side, so I took a look at your code and I see that your model classes have an internal Index that you use and I think that's the problem.
Suppose I get historical data from my POCO classes and convert them to your
Quotemodelsuppose I've a list
List<Quote> historyof 100QuotesNow if I call
I get a
System.ArgumentOutOfRangeException: 'Index was out of range. Must be non-negative and less than the size of the collection.'I think the problem is that if I reuse Quote objects taking a different slice of the array, the bugs pops out because there is the Index field inconsistence inside your model classes
This means that historical quotes cannot be reused this way but I must always use the same set and I think it's not good because of performance (I'm not interested in applying indicators on the whole historical set in my scenario
Thanks
The text was updated successfully, but these errors were encountered: