This project is a case study of CSR, it aims to explore the potential of client-side rendered apps compared to server-side rendering.
CSR: Client-side Rendering
SSR: Server-side Rendering
SSG: Static Site Generation
- Intro
- Motivation
- Performance
- SEO
- CSR vs. SSR
- Conclusion
Client-side rendering is the practice of sending the web browser static assets and leaving it to perform the entire rendering process of the app. Server-side rendering is the practice of rendering the entire app (or page) on the server, sending to the browser a pre-rendered HTML document ready to be displayed. Static Site Generation is the practice of pre-generating HTML pages as static assets to be sent and displayed by the browser.
Contrary to popular belief, the SSR process of modern frameworks such as React, Angular, Vue and Svelte, makes the app render twice: one time on the server and another time on the browser (this is called "hydration"). Without the latter, the app cannot become interactive and would just be a static, "lifeless", web page.
The "hydration" process takes about the same time as a full render.
Needless to say that SSG apps have to be "hydrated" aswell.
The HTML document is fully constucted in both SSR and SSG, which gives them the following advantages:
- Web crawlers will be able to crawl their pages out-of-the-box, which is critical for SEO.
- When inlining critical CSS, the FCP of the page will usually be very good (in SSR it heavily depends on the API server response times).
On the other hand, CSR has the following advantages:
- The app itself is completely decoupled from the server, which means it loads without being affected by the API server's response times.
- The developer experience is seemless, all libraries and packages just work without any special customizations.
- Newly introduced framework updates can be used right away, without having to wait for the wrapping SSR framework to implement them.
- The learning curve is better, since developers only have to learn the framework instead of both the framework and its SSR wrapper.
In this case-study, we will focus on CSR and how to overcome its built-in shortages while leaveraging its strong points.
Our deployed app can be found here: https://client-side-rendering.pages.dev
"Recently, SSR (Server Side Rendering) has taken the JavaScript front-end world by storm. The fact that you can now render your sites and apps on the server before sending them to your clients is an absolutely revolutionary idea (and totally not what everyone was doing before JS client-side apps got popular in the first place...).
However, the same criticisms that were valid for PHP, ASP, JSP, (and such) sites are valid for server-side rendering today. It's slow, breaks fairly easily, and is difficult to implement properly.
Thing is, despite what everyone might be telling you, you probably don't need SSR. You can get almost all the advantages of it (without the disadvantages) by using prerendering."
Over the last few years, server-side rendering has started to (re)gain popularity in the form of frameworks such as Next.js and Remix to the point that developers just start working with them as a default, without understanding their limitations and even in apps which do not require SEO at all.
While SSR has some advantages, these frameworks keep emphasizing how fast they are ("Performance as a default"), implying client-side rendering is slow.
In addition, it is a common misconception that perfect SEO can only be achieved by using SSR, and that there's nothing we can do to improve the way search engines crawl CSR apps.
This project implements a basic CSR app with some tweaks such as code-splitting and preloading, with the ambition that as the app scales, the loading time of a single page would mostly remain unaffected. The objective is to simulate the number of packages used in a production grade app and try to decrease its loading time as much as possible, mostly by parallelizing requests.
It is important to note that improving performance should not come at the expense of the developer experience, so the way this project is architected should vary only slightly compared to "normal" react projects, and it won't be as extremely opinionated as Next.js (or as limiting as SSR is in general).
This case study will cover two major aspects: performance and SEO. We will see how we can achieve great scores in both of them.
Note that while this project is implemented with React, the vast majority of its tweaks are not tied to any framework and are purely browser-based.
We will assume a standard Webpack 5 setup and add the required customizations as we progress.
Most of the code changes that we'll go throught will be in the webpack.config.js configuration file and the index.js HTML template.
The first rule of thumb is to use as fewer dependencies as possible, and among those, to select the ones with smaller filesize.
For example:
We can use day.js instead of moment, zustand instead of redux toolkit etc.
This is crucial not only for CSR apps, but also for SSR (and SSG) apps, since the bigger our bundle is - the longer it will take the page to be visible or interactive.
Ideally, every hashed file should be cached, and index.html should never be cached.
It means that the browser would initially cache main.[hash].js and would have to redownload it only if its hash (content) changes.
However, since main.js includes the entire bundle, the slightest change in code would cause its cache to expire, meaning the browser would have to download it again.
Now, what part of our bundle comprises most of its weight? The answer is the dependencies, also called vendors.
So if we could split the vendors to their own hashed chunk, that would allow a separation between our code and the vendors code, leading to less cache invalidations.
Let's add the following part to our webpack.config.js file:
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
name: 'vendors'
}
}
}
}This will create a vendors.[hash].js file.
Although this is a substantial improvement, what would happen if we updated a very small dependency?
In such case, the entire vendors chunk's cache will invalidate.
So, in order to make this even better, we will split each dependency to its own hashed chunk:
- name: 'vendors'
+ name: ({ context }) => (context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/) || [])[1]This will create files like react-dom.[hash].js, react-router-dom.[hash].js etc.
More info about the default configurations (such as the split threshold size) can be found here:
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
A lot of the features we write end up being used only in a few of our pages, so we would like them to be loaded only when the user visits the page they are being used in.
For Example, we wouldn't want users to download, parse and execute the react-big-calendar package if they merely loaded the home page. We would only want that to happen when they visit the calendar page.
The way we achieve this is (preferably) by route-based code splitting:
const Home = lazy(() => import(/* webpackChunkName: "home" */ 'pages/Home'))
const LoremIpsum = lazy(() => import(/* webpackChunkName: "lorem-ipsum" */ 'pages/LoremIpsum'))
const Pokemon = lazy(() => import(/* webpackChunkName: "pokemon" */ 'pages/Pokemon'))So when the user visits the Lorem Ipsum page, they only download the main chunk script (which includes all shared dependencies such as the framework) and the lorem-ipsum.[hash].js chunk.
Note: it is completely fine (and even encouraged) to have the user download our entire app, so they can have a smooth app-like navigation experience. But it is very wrong to make all assets load initially, delaying the first render of the page.
These assets should be downloaded after the user-requested page has finished rendering and is entirely visible.
Code splitting has one major flaw - the runtime doesn't know which async chunks are needed until the main script executes, leading to them being fetched in a significant delay (since they make another round-trip to the CDN):

The way we can solve this issue is by implementing a script in the document that will be responsible for preloading relevant assets:
plugins: [
new HtmlPlugin({
scriptLoading: 'module',
templateContent: ({ compilation }) => {
const assets = compilation.getAssets().map(({ name }) => name)
const pages = pagesManifest.map(({ chunk, path }) => {
const script = assets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
return { path, script }
})
return htmlTemplate(pages)
}
})
]module.exports = pages => `
<!DOCTYPE html>
<html lang="en">
<head>
<title>CSR</title>
<script>
let { pathname } = window.location
if (pathname !== '/') pathname = pathname.replace(/\\/$/, '')
const pages = ${JSON.stringify(pages)}
for (const { path, script } of pages) {
if (pathname !== path) continue
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
break
}
</script>
</head>
<body>
<div id="root"></div>
</body>
</html>
`The imported pages-manifest.json file can be found here.
Please note that other types of assets can be preloaded the same way (like stylesheets).
This way, the browser is able to fetch the page-related script chunk in parallel with render-critical assets:

Code splitting introduced us to a new problem: async vendor duplication.
Say we have two async chunks: lorem-ipsum.[hash].js and pokemon.[hash].js.
If they both include the same dependency that is not part of the main chunk, that means the user will download that dependency twice.
So if that said dependency is moment and it weighs 72kb minzipped, then both async chunk's size will be at least 72kb.
We need to split this dependency from these async chunks so that it could be shared between them:
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/) || [])[1]
}
}
}
}Now both lorem-ipsum.[hash].js and pokemon.[hash].js will use the extracted moment.[hash].js chunk, sparing the user a lot of network traffic (and giving these assets better cache persistence).
However, we have no way of telling which async vendor chunks will be split before we build the application, so we wouldn't know which async vendor chunks we need to preload (refer to the "Preloading Async Chunks" section):

That's why we will append the chunks names to the async vendor's name:
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/) || [])[1]
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`
}
}
}
}
},
.
.
.
plugins: [
new HtmlPlugin({
scriptLoading: 'module',
templateContent: ({ compilation }) => {
const assets = compilation.getAssets().map(({ name }) => name)
const pages = pagesManifest.map(({ chunk, path, data }) => {
- const script = assets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = assets.filter(name => new RegExp(`[/.]${chunk}\\.(.+)\\.js$`).test(name))
if (data && !Array.isArray(data)) data = [data]
- return { path, script, data }
+ return { path, scripts, data }
})
return htmlTemplate(pages)
}
})
]module.exports = pages => `
<!DOCTYPE html>
<html lang="en">
<head>
<title>CSR</title>
<script>
const isStructureEqual = (pathname, path) => {
pathname = pathname.split('/')
path = path.split('/')
if (pathname.length !== path.length) return false
return pathname.every((segment, ind) => segment === path[ind] || path[ind].includes(':'))
}
let { pathname } = window.location
if (pathname !== '/') pathname = pathname.replace(/\\/$/, '')
const pages = ${JSON.stringify(pages)}
- for (const { path, script, data } of pages) {
+ for (const { path, scripts, data } of pages) {
const match = pathname === path || (path.includes(':') && isStructureEqual(pathname, path))
if (!match) continue
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
+ })
if (!data) break
data.forEach(({ url, dynamicPathIndexes, crossorigin }) => {
let fullURL = url
if (dynamicPathIndexes) {
const pathnameArr = pathname.split('/')
const dynamics = dynamicPathIndexes.map(index => pathnameArr[index])
let counter = 0
fullURL = url.replace(/\\$/g, match => dynamics[counter++])
}
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: fullURL, as: 'fetch', crossOrigin: crossorigin })
)
})
break
}
</script>
</head>
<body>
<div id="root"></div>
</body>
</html>
`Now all async vendor chunks will be fetched in parallel with their parent async chunk:

One of the disadvantages of CSR over SSR is that data will be fetched only after JS has been downloaded, parsed and executed in the browser:

To overcome this, we will use preloading once again, this time for the data itself:
plugins: [
new HtmlPlugin({
scriptLoading: 'module',
templateContent: ({ compilation }) => {
const assets = compilation.getAssets().map(({ name }) => name)
- const pages = pagesManifest.map(({ chunk, path }) => {
+ const pages = pagesManifest.map(({ chunk, path, data }) => {
const script = assets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ if (data && !Array.isArray(data)) data = [data]
- return { path, script }
+ return { path, script, data }
})
return htmlTemplate(pages)
}
})
]module.exports = pages => `
<!DOCTYPE html>
<html lang="en">
<head>
<title>CSR</title>
<script>
+ const isStructureEqual = (pathname, path) => {
+ pathname = pathname.split('/')
+ path = path.split('/')
+
+ if (pathname.length !== path.length) return false
+
+ return pathname.every((segment, ind) => segment === path[ind] || path[ind].includes(':'))
+ }
let { pathname } = window.location
if (pathname !== '/') pathname = pathname.replace(/\\/$/, '')
const pages = ${JSON.stringify(pages)}
- for (const { path, script } of pages) {
+ for (const { path, script, data } of pages) {
- if (pathname !== path) continue
+ const match = pathname === path || (path.includes(':') && isStructureEqual(pathname, path))
+
+ if (!match) continue
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
+ if (!data) break
+
+ data.forEach(({ url, dynamicPathIndexes, crossorigin }) => {
+ let fullURL = url
+
+ if (dynamicPathIndexes) {
+ const pathnameArr = pathname.split('/')
+ const dynamics = dynamicPathIndexes.map(index => pathnameArr[index])
+
+ let counter = 0
+
+ fullURL = url.replace(/\\$/g, match => dynamics[counter++])
+ }
+
+ document.head.appendChild(
+ Object.assign(document.createElement('link'), { rel: 'preload', href: fullURL, as: 'fetch', crossOrigin: crossorigin })
+ )
})
break
}
</script>
</head>
<body>
<div id="root"></div>
</body>
</html>
`Now we can see that the data is being fetched right away:

With the above script, we can even preload dynamic routes data (such as pokemon/:name).
The only limitation is that we can only preload GET resources, but this would not be a problem when the backend is well-architected.
If we take a closer look, here is what SSG essentially does: it creates a cacheable HTML file and injects static data into it.
This can be useful for data that is not highly dynamic, such as content from CMS.
So how can we create static data?
We will execute the following script during build time:
import { mkdir, writeFile } from 'fs/promises'
import axios from 'axios'
const path = 'public/json'
const axiosOptions = { transformResponse: res => res }
mkdir(path, { recursive: true })
const fetchLoremIpsum = async () => {
const { data } = await axios.get('https://loripsum.net/api/100/long/plaintext', axiosOptions)
writeFile(`${path}/lorem-ipsum.json`, JSON.stringify(data))
}
fetchLoremIpsum()That would create a json/lorem-ipsum.json file to be stored in the CDN.
And now we simply fetch the static data in our app:
fetch('json/lorem-ipsum.json')There are numerous advantages to this approach:
- We generate static data so we won't bother our server or CMS for every user request.
- The data will be fetched a lot faster from a nearby CDN edge than from a remote server.
- Since this script runs on our server during build time, we can authenticate with services however we want, there is no limit to what can be sent (secret tokens for example).
Whenever we need to update the static data we simply rebuild the app or, better yet, just rerun the script.
We can preload data when hovering over links (desktop) or when links enter the viewport (mobile):
const createPreload = url => {
if (document.head.querySelector(`link[href="${url}"]`)) return
document.head.appendChild(
Object.assign(document.createElement('link'), {
rel: 'preload',
href: url,
as: 'fetch'
})
)
}When we split a page from the main app, we separate its render phase, meaning the app will render before the page renders:


This happens due to the common approach of wrapping only the routes with Suspense:
const App = () => {
return (
<>
<Navigation />
<Suspense>
<Routes>{routes}</Routes>
</Suspense>
</>
)
}This method has a lot of sense to it:
We would prefer the app to be visually complete in a single render, but we would never want to stall the page render until the async chunk finishes loading.
However, since we preload all async chunks (and their vendors), this won't be a problem for us. So we should hide the entire app until the async chunk finishes loading (which, in our case, happens in parallel with all the render-critical assets):
const root = document.getElementById('root') as HTMLDivElement
document.body.style.overflow = 'hidden'
root.style.visibility = 'hidden'
new MutationObserver((_, observer) => {
if (!document.getElementById('layout')?.hasChildNodes()) return
document.body.removeAttribute('style')
root.removeAttribute('style')
observer.disconnect()
}).observe(root, { childList: true, subtree: true })import 'utils/delay-page-visibility'In our case, we only show the app when the Layout component has children (which means that an async page was loaded).
This would make our app and the async page visually show up at the same time.
Note: this technique requires React 18
We will see a similar effect when we move to another async page: a blank space that remains until the page's script finishes downloading.
React 18 introduced us to the useTransition hook, which allows us to delay a render until some criteria are met.
We will use this hook to delay the page's navigation until it is ready:
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useDelayedNavigate = () => {
const [, startTransition] = useTransition()
const navigate = useNavigate()
return to => startTransition(() => navigate(to))
}
export default useDelayedNavigateconst NavigationLink = ({ to, onClick, children }) => {
const navigate = useDelayedNavigate()
const onLinkClick = event => {
event.preventDefault()
navigate(to)
onClick?.()
}
return (
<NavLink to={to} onClick={onLinkClick}>
{children}
</NavLink>
)
}
export default NavigationLinkNow async pages will feel like they were never split from the main app.
Users should have a smooth navigation experience in our app.
However, splitting every page causes a noticeable delay in navigation, since every page has to be downloaded before it can be rendered on screen.
That's why I think all pages should be prefetched ahead of time.
We can do this by writing a wrapper function around React's lazy function:
import { lazy } from 'react'
const lazyPrefetch = chunk => {
if (window.requestIdleCallback) window.requestIdleCallback(chunk)
else window.addEventListener('load', () => setTimeout(chunk, 500), { once: true })
return lazy(chunk)
}
export default lazyPrefetch- const Home = lazy(() => import(/* webpackChunkName: "home" */ 'pages/Home'))
- const LoremIpsum = lazy(() => import(/* webpackChunkName: "lorem-ipsum" */ 'pages/LoremIpsum'))
- const Pokemon = lazy(() => import(/* webpackChunkName: "pokemon" */ 'pages/Pokemon'))
+ const Home = lazyPrefetch(() => import(/* webpackChunkName: "home" */ 'pages/Home'))
+ const LoremIpsum = lazyPrefetch(() => import(/* webpackChunkName: "lorem-ipsum" */ 'pages/LoremIpsum'))
+ const Pokemon = lazyPrefetch(() => import(/* webpackChunkName: "pokemon" */ 'pages/Pokemon'))Now all pages will be prefetched and parsed (but not executed) before the user even tries to navigate to them.
When a static asset is returned from a CDN, it includes an ETag header. An ETag is the content hash of the resource.
The next time the browser wants to fetch this asset, it first checks if it has stored an ETag for that asset. If it does, it sends that ETag inside an If-None-Match header along with the request.
The CDN then compares the received If-None-Match header with the asset's current ETag.
If they are different, the CDN will return a 200 Success status code along with the new asset.
However, if they match, the CDN will return a 304 Not Modified status code, notifying the browser that it can safely use its stored asset (without having to redownload it).
So in a traditional CSR app, when loading a page and then reloading it, we can see that the HTML request gets a 304 Not Modified status code (and all other assets are served from cache).
The ETag is stored per route, so /lorem-ipsum's and /pokemon's HTML ETags will be stored under different cache entries in the browser (even if their ETags are equal).
In a CSR SPA we have a single HTML file, and so the ETag that is returned from the CDN is the same for every page request.
However, since the ETag is stored per route (page), the browser won't send the If-None-Match if no ETag exists in that route's cache entry.
This means that for every unvisited page, the browser will get a 200 status code and will have to redownload the HTML, despite that fact that every page is the exact same HTML document.
The way we can overcome this disadvantage is by redirecting every HTML request to the root route using a Service Worker:
self.addEventListener('install', self.skipWaiting)
self.addEventListener('fetch', event => {
if (event.request.destination === 'document') {
event.respondWith(fetch(new Request(self.registration.scope)))
}
})Now every page we land on will request the root / HTML document from the CDN, making the browser send the If-None-Match header and get a 304 status code for every single route.
Up until now we've managed the make our app well-splitted, extremely cachable, with fluid navigations between async pages and with page and data preloads.
All of the above were achieved by adding a few lines of code to the webpack config and without imposing any limitations to how we develop our app.
In its current state, our app has amazing performance, far exceeding any preconfigured CSR solutions such as CRA.
From this point forward we are going to level it up one last time using a method that is a little less conservative but with unmatched benefits in terms of performance.
When using server-side rendering, it is most common to fetch the (dynamic) data on the server and then "bake" it into the HTML before sending the page to the browser.
This practice has a lot of sense to it, and fetching data on the browser will make the choice of using SSR completely unreasonable (it even falls behind CSR's performance since the fetch will occur only after the entire hydration process is finished).
However, inlining the data in the HTML has one major flaw: it eliminates the natural seperation between the app and the dynamic data.
The implications of this can be seen when trying to serve users cached pages.
It's obvious that we want our app to load fast for every user and especially for returning users. But since every user has a different connection speed, some users will see their requested pages only after several seconds.
In addition, even those with fast interent connection will have to pay the price of the initial connection before even starting to download their desired page:

In the sample above (caught by a 500Mbps interent connection speed), it tooks 600ms just to get the first byte of the HTML document.
These times vary greatly from several hundreds of milliseconds to (in extreme cases) more than a second. And to make things even worse, browsers keep the DNS cache only for about a minute, and so this process repeats very frequently.
The only reasonable way to rise above these issues is by caching HTML pages in the browser (for example, by setting a Max-Age value higher than 0).
But here is the problem with SSR: by doing so, users will potentailly see outdated content, since the data is inlined in the document.
The lack of seperation between the app (also called the "app shell") and its data prevents us from using the browser's cache without risking the freshness of the data.
However, in CSR apps we have complete seperation of the two, making it more than possible to cache only the app shell while still getting fresh data on every visit (just like in native apps).
We can easily implement app shell cache by setting the Cache-Control: Max-Age=x header of the HTML document to any value greater than 0. This way the app will load almost instantly (usually under 200ms) regardless of the user's connectivity or connection speed for the duration we set.
However, the Max-Age attribute has one major flaw: during the set time period, the browser won't even attempt to reach the CDN, requests will be fulfilled immidiately by the cached responses. This means that no matter how many times the user reloads the page - they will always get a "stale" (potentially outdated) response.
That's why the "Stale While Revalidate" (SWR) approach was invented.
When using SWR, the browser is allowed to use a cached asset or response (usually for a limited time) but in the same time it sends a request for the server and asks for the newest asset. After the fresh asset is downloaded, the browser replaces the stale cached asset with the fresh asset, ready to be used the next time the page is loaded.
This method completely surpasses any network conditions, it even allows our app to be available while offline (within the SWR allowed time period), and all of this without even compromising on the freshness of the app shell.
Many popular websites such as Twitter, CodeSandbox and Photopea implement SWR in their app shell.
There are two ways to achieve SWR in web applications:
- The stale-while-revalidate attribute.
- A custom service worker.
Although the first approach is completely usable (and can be set up within seconds), the second approach will give us a more granular control of how and when assets are cached and updated, so this is the approach we choose to implement.
Our SWR service worker needs to cache the HTML document and all of the fonts and scripts (and stylesheets) of all pages.
In addition, it needs to serve these cached assets right when the page loads and then send a request to the CDN, fetch all new assets (if exist) and finally replace the stale cached assets with the new ones.
plugins: [
...(production
? [
new InjectManifest({
include: [/fonts\//, /scripts\/.+\.js$/],
swSrc: path.join(__dirname, 'public', 'service-worker.js')
})
]
: [])
]const CACHE_NAME = 'my-csr-app'
const CACHED_URLS = ['/', ...self.__WB_MANIFEST.map(({ url }) => url)]
const MAX_STALE_DURATION = 7 * 24 * 60 * 60
const preCache = async () => {
await caches.delete(CACHE_NAME)
const cache = await caches.open(CACHE_NAME)
await cache.addAll(CACHED_URLS)
}
const staleWhileRevalidate = async request => {
const documentRequest = request.destination === 'document'
if (documentRequest) request = new Request(self.registration.scope)
const cache = await caches.open(CACHE_NAME)
const cachedResponsePromise = await cache.match(request)
const networkResponsePromise = fetch(request)
if (documentRequest) {
networkResponsePromise.then(response => cache.put(request, response.clone()))
if ((new Date() - new Date(cachedResponsePromise?.headers.get('date'))) / 1000 > MAX_STALE_DURATION) {
return networkResponsePromise
}
return cachedResponsePromise
}
return cachedResponsePromise || networkResponsePromise
}
self.addEventListener('install', event => {
event.waitUntil(preCache())
self.skipWaiting()
})
self.addEventListener('fetch', event => {
if (['document', 'font', 'script'].includes(event.request.destination)) {
event.respondWith(staleWhileRevalidate(event.request))
}
})service-worker-registration.js
const register = () => {
window.addEventListener('load', async () => {
try {
await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
} catch (err) {
console.error(err)
}
})
}
const unregister = async () => {
try {
const registration = await navigator.serviceWorker.ready
await registration.unregister()
console.log('Service worker unregistered!')
} catch (err) {
console.error(err)
}
}
if ('serviceWorker' in navigator) {
if (process.env.NODE_ENV === 'development') unregister()
else register()
}- const Home = lazyPrefetch(() => import(/* webpackChunkName: "home" */ 'pages/Home'))
- const LoremIpsum = lazyPrefetch(() => import(/* webpackChunkName: "lorem-ipsum" */ 'pages/LoremIpsum'))
- const Pokemon = lazyPrefetch(() => import(/* webpackChunkName: "pokemon" */ 'pages/Pokemon'))
+ const Home = lazy(() => import(/* webpackChunkName: "home" */ 'pages/Home'))
+ const LoremIpsum = lazy(() => import(/* webpackChunkName: "lorem-ipsum" */ 'pages/LoremIpsum'))
+ const Pokemon = lazy(() => import(/* webpackChunkName: "pokemon" */ 'pages/Pokemon'))We define a MAX_STALE_DURATION constant to set the maximum duration we are willing for our users to see the (potentially) stale app shell.
This duration can be derived from how often we update (deploy) our app in production. And it's important to remember that native apps, in comparison, can sometimes be "stale" for months without being updated by the app stores.
The results exceed all expectations:

These metrics are coming from a 5-year-old Intel i3-8130U laptop when the browser is using the disk cache (not the memory cache which is a lot faster), and are completely independent of network speed or status.
Now that we've seen that nothing can match SWR in terms of performance, our new goal is to try to keep users' apps as much up-to-date as possible, without compromising on the SWR allowed time period.
When a user opens our app and there's and update, the browser will replace the old cached files with the new ones. The user then will see the update only when they reload the page.
If we wanted the update to be visible right away, we could manually reload the app.
However, reloading the app while the user is viewing it is a very bad idea. Instead, we can reload the app while it is hidden:
const preCache = async () => {
await caches.delete(CACHE_NAME)
const cache = await caches.open(CACHE_NAME)
+ const [windowClient] = await clients.matchAll({ includeUncontrolled: true, type: 'window' })
await cache.addAll(CACHED_URLS)
+ windowClient.postMessage({ type: 'update-available' })
}service-worker-registration.js
import pagesManifest from 'pages-manifest.json'
const events = ['mousedown', 'keydown']
let userInteracted = false
events.forEach(event => addEventListener(event, () => (userInteracted = true), { once: true }))
const reloadIfPossible = () => {
if (userInteracted || document.visibilityState === 'visible') return
let { pathname } = window.location
if (pathname !== '/') pathname = pathname.replace(/\/$/, '')
const reloadAllowed = !!pagesManifest.find(
({ path, preventReload }) => !preventReload && isStructureEqual(pathname, path)
)
if (reloadAllowed) window.location.reload()
}
navigator.serviceWorker.addEventListener('message', ({ data }) => {
if (data.type === 'update-available') {
window.addEventListener('visibilitychange', reloadIfPossible)
}
})We reload the app only when it is hidden and the user did not interact with it. This way the app will self-update even without the user's notice.
Note that we do not consider the scroll event as an interaction, since this action is stateless and in most cases the browser will restore the scroll position upon reload.
In addition, we can define a preventReload property in pages that we wouldn't want to be automatically reloaded (such as a user's feed which potentially changes on every reload).
Some users leave the app open for extended periods of time, so another thing we can do is revalidate the app while it is running:
service-worker-registration.js
+ const ACTIVE_REVALIDATION_INTERVAL = 1 * 60 * 60
const register = () => {
window.addEventListener('load', async () => {
try {
- await navigator.serviceWorker.register('/service-worker.js')
+ const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
+ setInterval(() => registration.update(), ACTIVE_REVALIDATION_INTERVAL * 1000)
} catch (err) {
console.error(err)
}
})
}
navigator.serviceWorker.addEventListener('message', ({ data }) => {
if (data.type === 'update-available') {
+ reloadIfPossible()
+
window.addEventListener('visibilitychange', reloadIfPossible)
}
})The code above arbitrarily revalidates the app every hour. However, we could implement a more sophisticated revalidation process which will run every time we deploy our app and notify all online users either through SSE or WebSockets.
The final method we can use in order to promise our users always have the latest version of our app is called Periodic Background Sync.
This method only works for installed PWAs and allows the OS to periodically "wake-up" the service worker when the app is closed.
During its wake-up time, the service worker can perform any task, including revalidating assets:
self.addEventListener('periodicsync', event => {
if (event.tag === 'revalidate-assets') event.target.registration.update()
})service-worker-registration.js
const ACTIVE_REVALIDATION_INTERVAL = 1 * 60 * 60
+ const PERIODIC_REVALIDATION_INTERVAL = 12 * 60 * 60
const register = () => {
window.addEventListener('load', async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
setInterval(() => registration.update(), ACTIVE_REVALIDATION_INTERVAL * 1000)
+ const { state } = await navigator.permissions.query({ name: 'periodic-background-sync' })
+
+ if (state === 'granted') {
+ await registration.periodicSync.register('revalidate-assets', {
+ minInterval: PERIODIC_REVALIDATION_INTERVAL * 1000
+ })
+ }
} catch (err) {
console.error(err)
}
})
}This way we ensure that users who installed our app will always see the most recent version when they open it.
Note that this is currently only working in Chromium-based browsers and in a non-iOS environment.
Further reading: https://developer.chrome.com/articles/periodic-background-sync
We've managed to make the initial load of our app extremely fast, only what is needed for the requested page is being loaded.
In addition, we preload other pages (and even their data), which makes it seem as if they were never seperated to begin with.
And finally, we wrapped everything with SWR, so the repeated loads of our app are unbelievably fast, it's literaly impossible to get anything better than that.
All of these were achieved without compromising on the developer experience and without dictating which JS framework we choose or where we deploy our app, it can be on any CDN we choose (more on that in the next section).
The biggest advantage of a static app is that it can be served entirely from a CDN.
A CDN has many PoPs (Points of Presence), also called "Edge Networks". These PoPs are distributed around the globe and thus are able to serve files to every region much faster than a remote server.
The fastest CDN to date is Cloudflare, which has more than 250 PoPs (and counting):

https://blog.cloudflare.com/benchmarking-edge-network-performance
We can easily deploy our app using Cloudflare Pages:
https://pages.cloudflare.com
To conclude this section, we will perform a benchmark of our app compared to Next.js's documentation site (which is entirely SSG).
We will compare the minimalistic Accessibility page to our Lorem Ipsum page. Both pages include ~246kb of JS in their render-critical chunks (preloads and prefetches that come after are irrelevant).
You can click on each link to perform a live benchmark.
Accessibility | Next.js
Lorem Ipsum | Client-side Rendering
I performed Google's PageSpeed Insights benchmark (simulating a slow 4G network) about 20 times for each page and picked the highest score.
These are the results:


As it turns out, performance is not a default in Next.js.
Note that this benchmark only tests the first load of the page, without even considering how the app performs when it is fully cached (where our SWR implementation really shines).
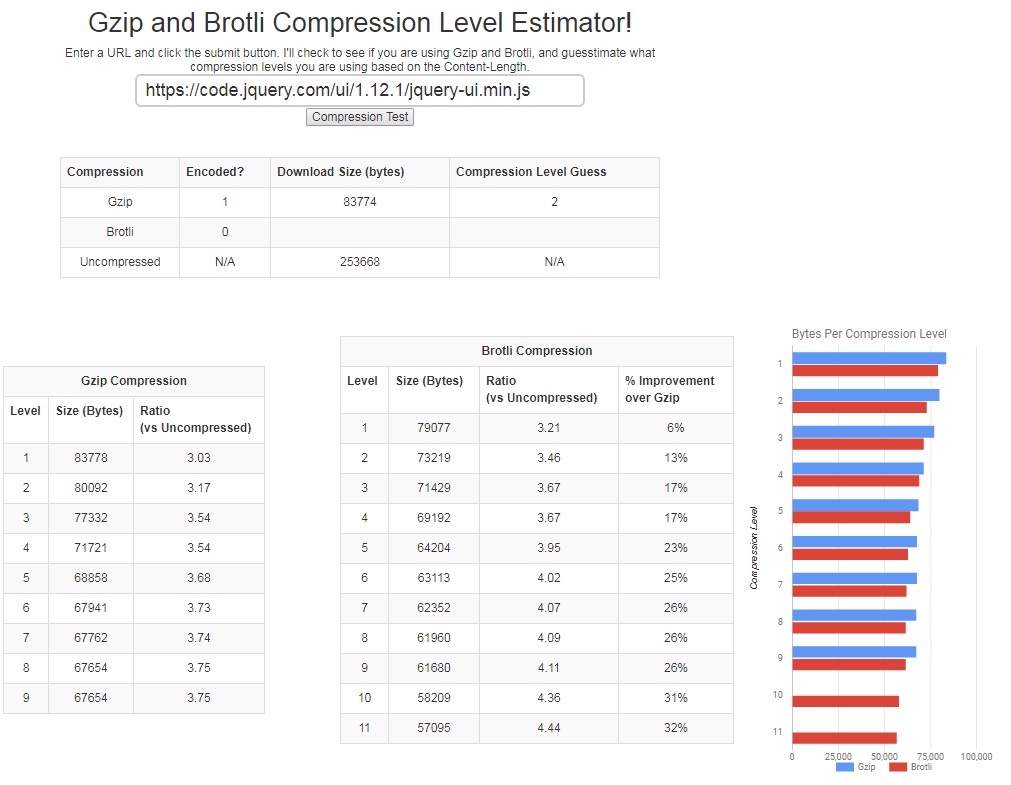
- Compress assets using Brotli level 11 (Cloudflare only uses level 4 to save on computing resources).
- Use the paid Cloudflare Argo service for even better response times.
{kind=link}
It is often said that Google is having trouble properly crawling CSR (JS) apps.
That might have been the case in 2018, but as of 2022, Google crawls CSR apps almost flawlessly.
The indexed pages will have a title, description and content, as long as we remember to dynamically set them (either manually or using something like react-helmet).
However, since Googlebot tries to save on computing power (aka "Crawl Budget"), there might be cases where it would take a snapshot of the page before its dynamic data finishes loading.
So for achieving perfect SEO results, we might prefer to "play it safe" and not to entirely rely on its ability to crawl JS apps (although it generally does a perfect job). We will discuss what we can do in the next section.
Other search engines such as Bing cannot render JS (despite claiming they can). So in order to have them crawl our app properly, we will serve them prerendered versions of our pages.
Prerendering is the act of crawling web apps in production (using headless Chromium) and generating a complete HTML file (with data) for each page.
We have two options when it comes to prerendering:
- We can use a dedicated service such as prerender.io.

- We can deploy our own prerender server using free open-source tools such as Prerender (a fully working example can be found here).
Then we redirect web crawlers (identified by their User-Agent header string) to our prerendered pages using a Cloudflare worker (in the following example we redirect to prerender.io):
const BOT_AGENTS = ['googlebot', 'bingbot', 'yandex', 'twitterbot', 'whatsapp', ...]
const fetchPrerendered = async request => {
const { url, headers } = request
const prerenderUrl = `https://service.prerender.io/${url}`
const headersToSend = new Headers(headers)
headersToSend.set('X-Prerender-Token', YOUR_PRERENDER_TOKEN)
const prerenderRequest = new Request(prerenderUrl, {
headers: headersToSend,
redirect: 'manual'
})
const { status, body } = await fetch(prerenderRequest)
return new Response(body, { status })
}
export default {
fetch(request, env) {
const pathname = new URL(request.url).pathname.toLowerCase()
const userAgent = (request.headers.get('User-Agent') || '').toLowerCase()
if (BOT_AGENTS.some(agent => userAgent.includes(agent)) && !pathname.includes('.')) return fetchPrerendered(request)
return env.ASSETS.fetch(request)
}
}Prerendering, also called Dynamic Rendering, is encouraged by Google and Microsoft.
Using prerendering produces the exact same SEO results as using SSR in all search engines.
https://www.google.com/search?q=site:https://client-side-rendering.pages.dev


https://www.bing.com/search?q=site%3Ahttps%3A%2F%2Fclient-side-rendering.pages.dev

In addition, cached prerendered pages will have unbelievably low response times, which may (or may not) positively affect their SEO score.
Note that when using CSS-in-JS, we should disable the speedy optimization during prerendering in order to have our styles omitted to the DOM.
When we share a CSR app link in social media, we can see that no matter what page we link to, the preview will remain the same.
This happens because most CSR apps have only one HTML file, and social share previews do not render JS.
This is where prerendering comes to our aid once again, we only need to make sure to set the correct meta tags dynamically:
const Home = props => {
return (
<Meta
title="Client-side Rendering"
description="This page demonstrates a large amount of components that are rendered on the screen."
image={`${window.location.origin}/icons/og-icon.png`}
/>
.
.
.
)
}The Meta component can be found here.
This, after going through prerendering, gives us the correct preview for every page:



In order to make all of our app pages discoverable to search engines, we should create a sitemap.xml file which specifies all of our website routes.
Since we already have a centralized pages-manifest.json file, we can easily generate a sitemap during build time:
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream, streamToPromise } from 'sitemap'
import pagesManifest from '../src/pages-manifest.json' assert { type: 'json' }
const stream = new SitemapStream({ hostname: 'https://client-side-rendering.pages.dev' })
const links = pagesManifest.map(({ path }) => ({ url: path, changefreq: 'daily' }))
streamToPromise(Readable.from(links).pipe(stream))
.then(data => data.toString())
.then(res => writeFile('public/sitemap.xml', res))
.catch(console.log)This will emit the following sitemap:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1" xmlns:news="http://www.google.com/schemas/sitemap-news/0.9" xmlns:video="http://www.google.com/schemas/sitemap-video/1.1" xmlns:xhtml="http://www.w3.org/1999/xhtml">
<url>
<loc>https://client-side-rendering.pages.dev/</loc>
<changefreq>daily</changefreq>
</url>
<url>
<loc>https://client-side-rendering.pages.dev/lorem-ipsum</loc>
<changefreq>daily</changefreq>
</url>
<url>
<loc>https://client-side-rendering.pages.dev/pokemon</loc>
<changefreq>daily</changefreq>
</url>
</urlset>We can manually submit our sitemap to Google Search Console and Bing Webmaster Tools.
Here's a list of some SSR drawbacks to consider:
- Server-side data fetching might be a bad idea in many cases, since some queries may take several hundreds of milliseconds to return (many will exceed that), and while pending, the user sees absolutely nothing in their browser.
- When using client-side data fetching, SSR will always be slower than CSR, since its document is always bigger and takes longer to download. In addition, all web crawlers (except for Googlebot) will index the page without its data.
- Streaming SSR also has some major drawbacks.
- SSR apps are always heavier than CSR apps, since every page is composed of both a fully-constructed HTML document and its scripts (used for hydration).
- Since all images are initially included in the document, scripts and images will compete for bandwidth, causing delayed interactivity on slow networks.
- Since accessing browser-related objects during the server render phase throws an error, some very helpful tools become unusable, while others (such as react-media) require SSR-specific customizations.
- SSR pages cannot respond with a 304 Not Modified status.
We have seen the advantages of static files: they are cacheable; a 304 Not Modified status can be returned for them; they can be served from a nearby CDN and serving them doesn't require a Node.js server.
This may lead us to believe that SSG combines both CSR and SSR advantages: we can make our app visually appear very fast (FCP) and it will even be interactive very quickly.
However, in reality, SSG has one major limitation:
Since JS isn't active during the first moments, everything that relies on JS to be presented simply won't be visible, or it will be visible in its incorrect state (like components which rely on the window.matchMedia function to be displayed).
A classic example of this problems is demonstrated by the following website:
https://death-to-ie11.com
Notice how the timer isn't available right away? that's because its generated by JS, which takes time to download and execute.
We can also see that refreshing Next.js's Accessibility page introduces a layout shift in the menu. This is caused by the fact that the static HTML doesn't know which section is selected (or some similar reason) until JS is loaded.
Another example for this is JS animations - they would first appear static and start animating only when JS is loaded.
There are various examples of how this delayed functionality negatively impacts the user experience, like the way some websites only show the navigation bar after JS has been loaded (since they cannot access the Local Storage to check if it has a user info entry).
Another issue which can be especially critical for E-commere websites is that SSG pages might reflect outdated data (a product's price or availability for example).
It is a fact that under fast internet connection, both CSR and SSR perform great (as long as they are both optimized). And the higher the connection speed - the closer they get in terms of loading times.
However, when dealing with slow connections (such as mobile networks), it seems that SSR has an edge over CSR regarding loading times.
Since SSR apps are rendered on the server, the browser receives the fully-constructed HTML file, and so it can show the page to the user without waiting for JS to download. When JS is eventually download and parsed, the framework is able to "hydrate" the DOM with functionality (without having to reconstruct it).
Although it seems like a big advantage, this behaviour has one major flaw on slow connections - until JS is loaded, users can click wherever they desire but the app won't react to their interactions.
It is a bad user experience when buttons don't respond to user interaction, but it becomes a much larger problem when default events are not being prevented.
This is a comparison between Next.js's website and Client-side Rendering app on a fast 3G connection:


What happened here?
Since JS hasn't been loaded yet, Next.js's website could not prevent the default behaviour of anchor tags to navigate to another page, resulting in every click on them triggering a full page reload.
And the slower the connection is - the more severe this issue becomes.
In other words, where SSR should have had a performance edge over CSR, we see a very "dangerous" behavior that might degrade the user experience.
It is impossible for this issue to occur in CSR apps, since the moment they render - JS has already been fully loaded.
We saw that client-side rendering performance is on par and sometimes even better than SSR in terms of loading times.
We also learned that prerendering produces perfect SEO results, and that we don't even need to think about it once it is set up.
And above all - we have achieved all this mainly by modifiying 2 files (Webpack config and HTML template) and using a prerender service, so every existing CSR app should be able to quickly and easily implement these modifications and benefit from them.
These facts lead to the conclusion that there is no particular reason to use SSR, it would only add a lot of complexity and limitations to our project and degrade the developer experience.
As time passes, connection speed is getting faster and end-user devices get stronger. So the performance differences between all possible website rendering methods are guarenteed to be mitigated even further.
There are some new SSR methods (such as Streaming SSR with Server Components) and frameworks (such as Marko and Qwik) which pretend to reduce the inital JS that has to be downloaded.
Nevertheless, it's important to note that nothing makes pages load faster than the SWR approach, which is only possible through client-side rendering.