TensorFlow 2.X reimplementation of Visual Attention Network, Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
- Exact TensorFlow reimplementation of official PyTorch repo, including
timmmodules used by authors, preserving models and layers structure. - ImageNet pretrained weights ported from PyTorch official implementation.
While originally designed for natural language processing (NLP) tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, the authors propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. The authors further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple and efficient, VAN outperforms the state-of-the-art vision transformers (ViTs) and convolutional neural networks (CNNs) with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc.

Figure 1. Compare with different vision backbones on ImageNet-1K validation set.
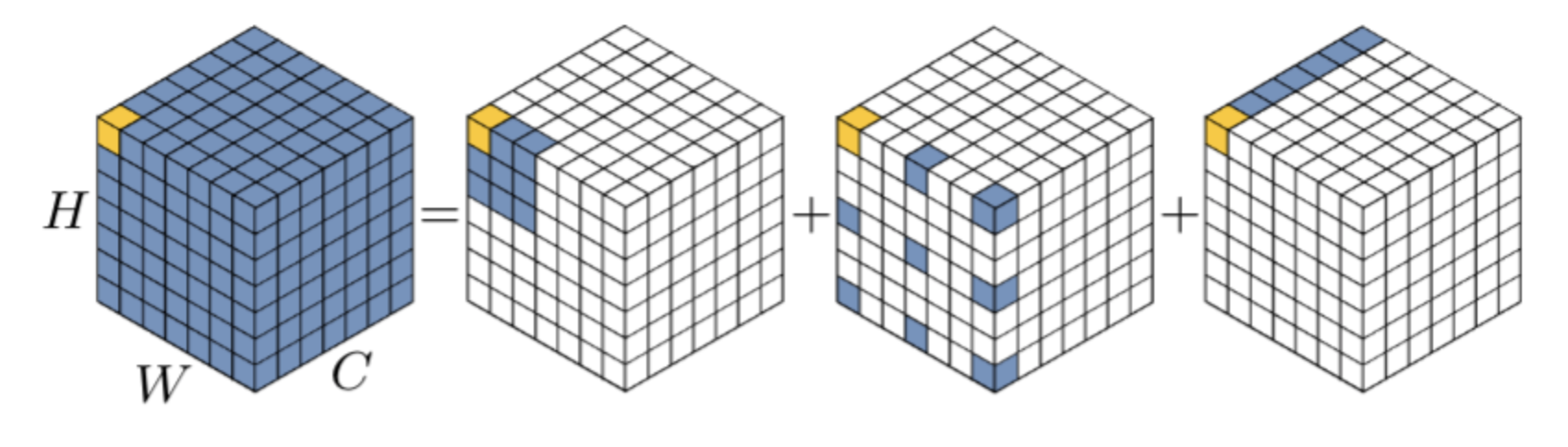
Figure 2. Decomposition diagram of large-kernel convolution. A standard convolution can be decomposed into three parts: a depth-wise convolution (DW-Conv), a depth-wise dilation convolution (DW-D-Conv) and a 1×1 convolution (1×1 Conv).

Figure 3. The structure of different modules: (a) the proposed Large Kernel Attention (LKA); (b) non-attention module; (c) the self-attention module (d) a stage of our Visual Attention Network (VAN). CFF means convolutional feed-forward network. The difference between (a) and (b) is the element-wise multiply. It is worth noting that (c) is designed for 1D sequences.
TensorFlow implementation and ImageNet ported weights have been compared to the official PyTorch implementation on ImageNet-V2 test set.
| Configuration | Resolution | Top-1 (Original) | Top-1 (Ported) | Top-5 (Original) | Top-5 (Ported) | #Params |
|---|---|---|---|---|---|---|
| VAN-B0 | 224x224 | 0.59 | 0.59 | 0.81 | 0.81 | 4.1M |
| VAN-B1 | 224x224 | 0.64 | 0.64 | 0.84 | 0.84 | 13.9M |
| VAN-B2 | 224x224 | 0.69 | 0.69 | 0.88 | 0.88 | 26.6M |
| VAN-B3 | 224x224 | 0.71 | 0.71 | 0.89 | 0.89 | 44.8M |
Metrics difference: 0.
- Install from PyPI.
pip install van-classification-tensorflow
- Install from GitHub.
pip install git+https://github.com/EMalagoli92/VAN-Classification-TensorFlow
- Clone the repo and install necessary packages.
git clone https://github.com/EMalagoli92/VAN-Classification-TensorFlow.git
pip install -r requirements.txt
Tested on Ubuntu 20.04.4 LTS x86_64, python 3.9.7.
- Define a custom VAN configuration.
from van_classification_tensorflow import VAN
# Define a custom VAN configuration
model = VAN(
in_chans=3,
num_classes=1000,
embed_dims=[64, 128, 256, 512],
mlp_ratios=[4, 4, 4, 4],
drop_rate=0.0,
drop_path_rate=0.0,
depths=[3, 4, 6, 3],
num_stages=4,
include_top=True,
classifier_activation="softmax",
data_format="channels_last",
)- Use a predefined VAN configuration.
from van_classification_tensorflow import VAN
model = VAN(
configuration="van_b0", data_format="channels_last", classifier_activation="softmax"
)
model.build((None, 224, 224, 3))
print(model.summary())Model: "van_b0"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
patch_embed1 (OverlapPatchE ((None, 32, 56, 56), 4864
mbed) (),
())
block1/0 (Block) (None, 32, 56, 56) 25152
block1/1 (Block) (None, 32, 56, 56) 25152
block1/2 (Block) (None, 32, 56, 56) 25152
norm1 (LayerNorm_) (None, 3136, 32) 64
patch_embed2 (OverlapPatchE ((None, 64, 28, 28), 18752
mbed) (),
())
block2/0 (Block) (None, 64, 28, 28) 89216
block2/1 (Block) (None, 64, 28, 28) 89216
block2/2 (Block) (None, 64, 28, 28) 89216
norm2 (LayerNorm_) (None, 784, 64) 128
patch_embed3 (OverlapPatchE ((None, 160, 14, 14), 92960
mbed) (),
())
block3/0 (Block) (None, 160, 14, 14) 303040
block3/1 (Block) (None, 160, 14, 14) 303040
block3/2 (Block) (None, 160, 14, 14) 303040
block3/3 (Block) (None, 160, 14, 14) 303040
block3/4 (Block) (None, 160, 14, 14) 303040
norm3 (LayerNorm_) (None, 196, 160) 320
patch_embed4 (OverlapPatchE ((None, 256, 7, 7), 369920
mbed) (),
())
block4/0 (Block) (None, 256, 7, 7) 755200
block4/1 (Block) (None, 256, 7, 7) 755200
norm4 (LayerNorm_) (None, 49, 256) 512
head (Linear_) (None, 1000) 257000
pred (Activation) (None, 1000) 0
=================================================================
Total params: 4,113,224
Trainable params: 4,105,800
Non-trainable params: 7,424
_________________________________________________________________
- Train from scratch the model.
# Example
model.compile(
optimizer="sgd",
loss="sparse_categorical_crossentropy",
metrics=["accuracy", "sparse_top_k_categorical_accuracy"],
)
model.fit(x, y)- Use ported ImageNet pretrained weights.
# Example
from van_classification_tensorflow import VAN
model = VAN(
configuration="van_b1",
pretrained=True,
include_top=True,
classifier_activation="softmax",
)
y_pred = model(image)- Use ported ImageNet pretrained weights for feature extraction (
include_top=False).
import tensorflow as tf
from van_classification_tensorflow import VAN
# Get Features
inputs = tf.keras.layers.Input(shape=(224, 224, 3), dtype="float32")
features = VAN(configuration="van_b0", pretrained=True, include_top=False)(inputs)
# Custom classification
num_classes = 10
outputs = tf.keras.layers.Dense(num_classes, activation="softmax")(features)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)VAN-Classification (Official PyTorch implementation).
@article{guo2022visual,
title={Visual Attention Network},
author={Guo, Meng-Hao and Lu, Cheng-Ze and Liu, Zheng-Ning and Cheng, Ming-Ming and Hu, Shi-Min},
journal={arXiv preprint arXiv:2202.09741},
year={2022}
}This work is made available under the MIT License.