DoJobber is a python task orchestration framework based on writing small single-task idempotent classes (Jobs), defining interdependencies, and letting python do all the work of running them in the "right order".
DoJobber builds an internal graph of Jobs. It will run Jobs that have no unmet dependencies, working up the chain until it either reaches the root or cannot go further due to Job failures.
Each Job serves a single purpose, and must be idempotent, i.e. it will produce the same results if executed once or multiple times, without causing any unintended side effects. Because of this you can run your python script multiple times and it will get closer and closer to completion as any previously-failed Jobs succeed.
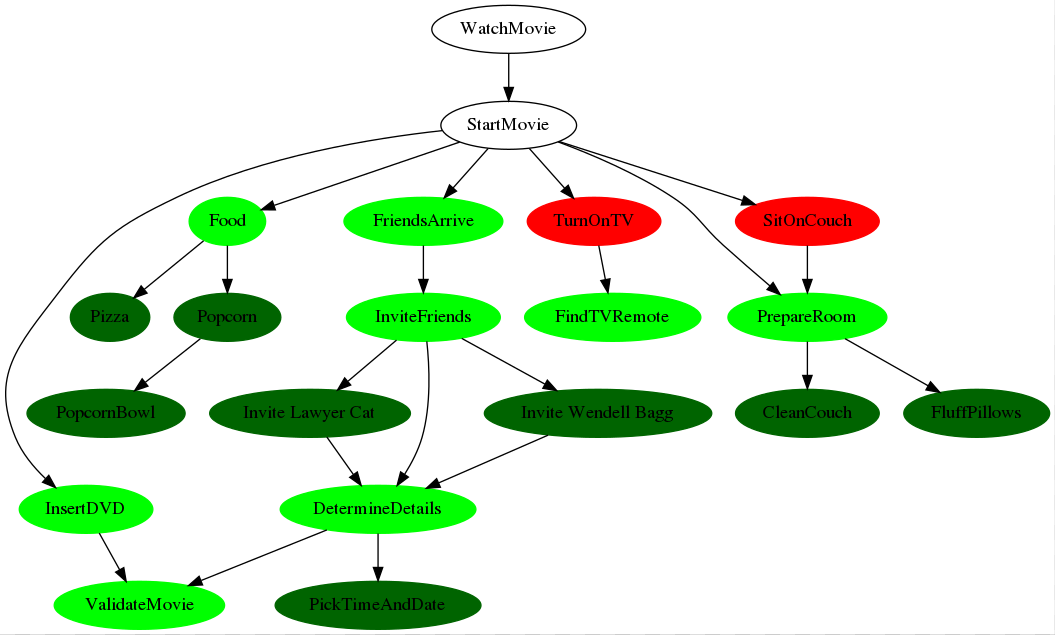
Here's an example of how one might break down the overall
goal of inviting friends over to watch a movie - this
is the result of the tests/dojobber_example.py script.
{kind=link}
Rather than a yaml-based syntax with many plugins, DoJobber lets you write in native python, so anything you can code you can plumb into the DoJobber framework.
DoJobber is conceptually based on a Google program known as Masher that was built for automating service and datacenter spinups, but shares no code with it.
Each Job is is own class. Here's an example:
class FriendsArrive(Job):
DEPS = (InviteFriends,)
def Check(self, *dummy_args, **dummy_kwargs):
# Do something to verify that everyone has arrived.
pass
def Run(self, *dummy_args, **dummy_kwargs):
pass
Each Job has a DEPS attribute, Check method, and Run method.
DEPS defines which other Jobs it is dependent on. This is used for generating the internal graph.
Check executes and, if it does not raise an Exception, is considered
to have passed. If it passes then the Job passed and the next Job will
run. It's purpose is to verify that we are in the desired state for
this Job. For example if the job was to create a user, this may
look up the user in /etc/passwd.
Run executes if Check failed. Its job is to do something to achieve
our goal. DoJobber doesn't care if it returns anything, throws an
exception, or exits - all this is ignored.
An example might be creating a user account, or adding a database entry, or launching an ansible playbook.
The Recheck phase simply executes the Check method again. Hopefully
the Run method did the work that was necessary, so Check will verify
all is now well. If so (i.e. Check does not raise an Exception) then
we consider this Job a success, and any dependent Jobs are not blocked
from running.
Jobs can take both positional and keyword arguments. These are set via the set_args method:
dojob = dojobber.DoJobber()
dojob.configure(RootJob, ......)
dojob.set_args('arg1', 'arg2', foo='foo', bar='bar', ...)
Because of this it is best to accept both in your Check and Run
methods:
def Check(self, *args, **kwargs):
....
def Run(self, *args, **kwargs):
....
If you're generating your keyword arguments from argparse or optparse, then you can be even lazier - send it in as a dict:
myparser = argparse.ArgumentParser()
myparser.add_argument('--movie', dest='movie', help='Movie to watch.')
...
args = myparser.parse_args()
dojob.set_args(**args.__dict__)
An then in your Check/Run you can use them by name:
def Check(self, *args, **kwargs):
if kwargs['movie'] == 'Zardoz':
raise Error('Really?')
Local Storage allows you to share information between
a Job's Check and Run methods. For example a Check
may do an expensive lookup or initialization which
the Run may then use to speed up its work.
To use Local Job Storage, simply use the
self.storage dictionary from your Check and/or
Run methods.
Local Storage is not available to any other Jobs. See Global Job Storage for how you can share information between Jobs.
Example:
class UselessExample(Job):
def Check(self, \*dummy_args, **dummy_kwargs):
if not self.storage.get('sql_username'):
self.storage['sql_username'] = (some expensive API call)
(check something)
def Run(self, *dummy_args, **kwargs):
subprocess.call(COMMAND + [self.storage['sql_username']])
Global Storage allows you to share information between Jobs. Naturally it is up to you to assure any Job that requires Global Storage is defined as dependent on the Job(s) that set Global Storage.
To use Global Job Storage, simply use the
self.global_storage dictionary from your
Check and/or Run methods.
Global Storage is available to all Jobs. It is up to you to avoid naming collisions.
Example:
# Store the number of CPUs on this machine for later
# Jobs to use for nefarious purposes.
class CountCPUs(Job):
def Check(self, *dummy_args, **dummy_kwargs):
self.global_storage['num_cpus'] = len(
[x
for x in open('/proc/cpuinfo').readlines()
if 'vendor_id' in x])
# FixFanSpeed is dependent on CountCPUs
class FixFanSpeed(Job):
DEPS = (CountCPUs,)
def Check(self, *args, **kwargs):
for cpu in range(self.global_storage['num_cpus']):
....
Jobs can have a Cleanup method. After checknrun is complete,
the Cleanup method of each Job that ran (i.e. Run was executed)
will be excuted. They are run in LIFO order, so Cleanups 'unwind'
everything.
You can pass the cleanup=False option to DoJobber() to prevent Cleanup from happening and run it manually if you prefer:
dojob = dojobber.DoJobber() dojob.configure(RootJob, cleanup=False, ......) dojob.checknrun() dojob.cleanup()
You can dynamically create Jobs by making new Job classes and adding them to the DEPS of an existing class. This is useful if you need to create new Jobs based on commandline options. Dynamically creating many small single-purpose jobs is a better pattern than creating one large monolithic job that dynamically determines what it needs to do and check.
Here's an example of how you could create a new Job dynamically.
We start with a base Job, SendInvite, which has uninitialized
class valiables EMAIL and NAME:
# Base Job
class SendInvite(Job):
EMAIL = None
NAME = None
def Check(self, *args, **kwargs):
r = requests.get(
'https://api.example.com/invited/' + self.EMAIL)
assert(r.status_code == 200)
def Run(self, *args, **kwargs):
requests.post(
'https://api.example.com/invite/' + self.EMAIL)
This example Job has Check/Run methods which use class
attribute EMAIL and NAME for their configuration.
So to get new Jobs based on this class, you create them and them
to the DEPS of an existing Job such that they appear in the graph:
class InviteFriends(DummyJob):
"""Job that will become dynamically dependent on other Jobs."""
DEPS = []
def invite_friends(people):
"""Add Invite Jobs for these people.
People is a list of dictionaries with keys email and name.
"""
for person in people:
job = type('Invite {}'.format(person['name']),
(SendInvite,), {})
job.EMAIL = person['email']
job.NAME = person['name']
InviteFriends.DEPS.append(job)
def main():
# do a bunch of stuff
...
# Dynamically add new Jobs to the InviteFriends
invite_friends([
{'name': 'Wendell Bagg', 'email': 'bagg@example.com'},
{'name': 'Lawyer Cat', 'email': 'lawyercat@example.com'}
])
DoJobber is meant to be able to be retried over and over until you achieve success. You may be tempted to write something like this:
...
retry = 5
while retry:
dojob.checknrun()
if dojob.success():
break
print('Trying again...')
retry -= 1
However this is not necessary, and in fact is a waste of computing cycles. The above code would cause us to check even the already successful nodes unnecessarily, slowing everything down.
Instead, you can use two class attribute to configure retry
parameters. TRIES specifies how many times your Job can
erun before we give up, and RETRY_DELAY specifies the
minimum amount of time between retries.
Retries are useful for those cases where an action in Run
fails due to a temporary condition (maybe the remote server
is unavailable briefly), or where the activities triggered
in the Run take time to complete (maybe an API call
returns immediately, but background fullfillment takes 30
seconds).
By relying on retry logic, instead of adding in arbirtary
sleep cycles in your code, you can have a more robust
Job graph.
When a Job is retried, it will be created from scratch. This means
that storage is not available between runs, however global_storage
is. This is done to keep things as pristine as possible between
Job executions.
TRIES defines the number of tries (check/run/recheck cycles) that the Job is allowed to do before giving up. It must be >= 1.
The TRIES default if unspecified is 3, which can be changed
in configure() via the default_tries=### argument, for
example:
class Foo(Job):
TRIES = 10
...
class Bar(Job):
DEPS = (Foo,)
... # No TRIES attribute
...
dojob = dojobber.DoJobber()
dojob.configure(Foo, default_tries=1)
In the above case, Foo can be tried 10 times, while Bar can only be
tried 1 time, since it has no TRIES specified and default_tries
in configure is 1.
RETRY_DELAY defines the minimum amount of time to wait between tries (check/run/recheck cycles) of this Job before giving up with permanent failure. It is measured in seconds, and may be any non-negative numeric value, including 0 and fractional seconds like 0.02.
The RETRY_DELAY default if unspecified is 1 , which can be
changed in configure() via the default_retry-delay=### argument,
for example:
class Foo(Job):
RETRY_DELAY = 10.5 # A long but strangely precise value...
...
class Bar(Job):
DEPS = (Foo,)
... # No RETRY_DELAY attribute
...
dojob = dojobber.DoJobber()
dojob.configure(Foo, default_retry_delay=0.5)
In the above case, Foo will never start unless at least 10.5 seconds
have passed since the previous Foo attempt, while Bar only required
0.5 seconds have passed since it has no RETRY_DELAY specified
and default_retry_delay in configure is 0.5.
When a Job has a failure it is not immediately retried. Instead we will hit all Jobs in the graph that are still awaiting check/run/recheck. Once every reachable Job has been hit we will 'start over' on the Jobs that failed.
In practice this means that you aren't wasting the full RETRY_DELAY because other Jobs were likely doing work between retries of this Job. (Unless your graph is highly linear and there are no unblocked Jobs.)
You can see how Job retries are interleaved by looking at the example code:
$ tests/dojobber_example.py -v | grep 'recheck: fail' TurnOnTV.recheck: fail "Remote batteries are dead." SitOnCouch.recheck: fail "No space on couch." PopcornBowl.recheck: fail "Dishwasher cycle not done yet." Pizza.recheck: fail "Giordano's did not arrive yet." TurnOnTV.recheck: fail "Remote batteries are dead." SitOnCouch.recheck: fail "No space on couch." PopcornBowl.recheck: fail "Dishwasher cycle not done yet." Pizza.recheck: fail "Giordano's did not arrive yet." TurnOnTV.recheck: fail "Remote batteries are dead." SitOnCouch.recheck: fail "No space on couch." PopcornBowl.recheck: fail "Dishwasher cycle not done yet." PopcornBowl.recheck: fail "Dishwasher cycle not done yet." PopcornBowl.recheck: fail "Dishwasher cycle not done yet." Popcorn.recheck: fail "Still popping..." Popcorn.recheck: fail "Still popping..."
Note initially we have several Jobs that fail on distinct branches, and these can be retried in a round-robin sort of fashion. Only once we end up at strict dependencies of PopcornBowl and Popcorn do we see single Jobs being retried without others getting their time.
There are several DoJobber Job types:
Job requires a Check, Run, and may have optional Cleanup:
class CreateUser(Job):
"""Create our user's account."""
def Check(self, *_, **kwargs):
"""Verify the user exists"""
import pwd
pwd.getpwnam(kwargs['username'])
def Run(self, *_, **kwargs):
"""Create user given the commandline username/gecos arguments"""
import subprocess
subprocess.call([
'sudo', '/usr/sbin/adduser',
'--shell', '/bin/tcsh',
'--gecos', kwargs['gecos'],
kwargs['username'])
### Optional Cleanup method
#def Cleanup(self):
# """Do something to clean up."""
# pass
DummyJob has no Check, Run, nor Cleanup. It is used simply to
have a Job for grouping dependent or dynamically-created Jobs.
So a DummyJob may look as simple as this:
class PlaceHolder(DummyJob):
DEPS = (Dependency1, Dependency2, ...)
A RunonlyJob has no check, just a Run, which will run every time.
If Run raises an exception then the Job is considered failed.
They cannot succeed in no_act mode, because
in this mode the Run is never executed.
So an example Run may look like this:
class RemoveDangerously(RunonlyJob):
DEPS = (UserAcceptedTheConsequences,)
def Run(...):
os.system('rm -rf /')
In general, avoid RunonlyJobs - it's better if you can understand if
a change even needs making.
There are two types of logging for DoJobber: runtime information about Job success/failure for anyone wanting more details about the processing of your Jobs, and developer DoJobber debugging which is useful when writing your DoJobber code.
To increase verbosity of Job success and failures you pass verbose or debug keyword arguments to configure:
dojob = dojobber.DoJobber() dojob.configure(RootJob, verbose=True, ....) # or dojob.configure(RootJob, debug=True, ....)
Setting verbose will show a line of check/run/recheck status to stderr, as well as any failure output from rechecks, such as:
FindTVRemote.check: fail FindTVRemote.run: pass FindTVRemote.recheck: pass TurnOnTV.check: fail TurnOnTV.run: pass ...
Using debug will additionally show a full stacktrace of any failure of check/run/recheck phases.
When writing your DoJobber code you may want to turn on the developer debugging capabilities. This is enabled when DoJobber is initialized by passing the dojobber_loglevel keyword argument:
import logging dojob = DoJobber(dojobber_loglevel=logging.DEBUG)
DoJobber's default is to show CRITICAL errors only. Acceptable levels are those defined in the logging module.
This can help identify problems when writing your code, such as passing a non-iterable as a DEPS variable, watching as your Job graph is created from the classes, etc.
The tests/dojobber_example.py script in the source directory is
fully-functioning suite of tests with numerous comments strewn
throughout.
Bri Hatch gave a talk about DoJobber at LinuxFestNorthwest in 2018. You can find his presentation on his website, and the presentation video is available on YouTube.