Knowledge cutoff is one of the issues that hasn’t been properly solved yet. The one and only solution currently available for this problem is RAG. However, the associated cost and computation make it unaffordable for individual developers. As the data increases, storing vector databases and querying or fetching it become challenging, with no guarantee of retrieving appropriate results.
We will explore the most economical way (Classification) to make your LLM aware of current events so that when a user asks for information about something that has happened today, this week, or this month, your LLM can provide an answer instead of apologizing for its knowledge cutoff.
Our architecture relies on multiple libraries, so the initial step is to import the necessary ones.
# Import the sys module for system-related functionality
import sys
# Import the openai module for using OpenAI's API
import openai
# Import the streamlit library for creating web applications
import streamlit as st
# Import the numpy library for numerical operations
import numpy as np
# Import cosine_similarity function from sklearn for calculating cosine similarity
from sklearn.metrics.pairwise import cosine_similarity
# Import SentenceTransformer from sentence_transformers for sentence embeddings
from sentence_transformers import SentenceTransformer
# Import google.generativeai module (if it exists; please verify the correct module)
import google.generativeai as genai
# Import json module for working with JSON data
import json
# Import requests module for making HTTP requests
import requests
# Import re module for regular expressions
import re
# Import word_tokenize and stopwords from nltk for natural language processing
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwordsYou might already be familiar with many libraries, while some may need installation, like the Google Generative AI library, if they don’t exist on your system.
# Install google generative ai library
pip install -q -U google-generativeai grpcio grpcio-tools
Our architecture begins by taking the user prompt, for example: “When is Apple releasing their electric vehicles?” As seen earlier, Mistral alone cannot answer this. The first stage is to classify this prompt under a relevant category. Based on the sample prompt, it might be classified under “current events” or “tech news.” Once a category is assigned, the next step is to invoke the correct API. If the detected category is “current events,” the Bing News API will be triggered with that user prompt and will fetch relevant information. This information, along with the prompt, will be passed to our base LLM (Mistral). Mistral will then generate a response based on the provided information.
Now that we have an overview of our architecture, let’s start coding each component one by one and observe how it will impact our LLM.
I will be using Mistral-7B-Instruct-v0.1 as my base LLM because it can generate responses very effectively, and we will be enhancing its memory. Alternatively, mistral-7b-GPTQ provided by TheBloke can also be used, it can be run on Colab, and the notebook is available here. Feel free to choose any other LLM of your preference.
# Set the device to load the model onto (e.g., "cuda" for GPU)
device = "cuda"
# Load the pre-trained model and tokenizer from the Mistral-7B-Instruct-v0.1 checkpoint
base_LLM = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
############ User input ############
user_input = "what is your knowledge cutoff?"
# Tokenize the user input
encoded_user_input = tokenizer(user_input, return_tensors="pt")
# Move the model inputs to the specified device (e.g., GPU)
model_inputs = encoded_user_input.to(device)
# Move the entire model to the specified device (e.g., GPU)
base_LLM.to(device)
# Generate a response from the model using the provided code snippet
output = base_LLM.generate(inputs=model_inputs, do_sample=True, max_new_tokens=2048)
# Decode and print the generated response
decoded_response = tokenizer.decode(output[0])
print(decoded_response)Just to confirm, the above code returns: “My knowledge cutoff is 2021–08–09.” So, most likely, when we ask a current knowledge question, Mistral-7B respond with this information.

A recent news of 2024, where Apple has recently confirmed the delay of their electric vehicle release from 2026 to 2028. While it has been circulating on the internet since 2021, the exact date was never announced before 2024. Mistral provided information based on its knowledge up to 2021, but the ideal output should reflect the current information.

Once we have chosen our base LLM, the next step is to find a strategy that can quickly and accurately classify the user prompt. This can be achieved in three steps:
-
Defining Categories
-
Utilizing Semantic Search LLM or Multi-Model Similarity Search
-
Cosine Similarity to categorize
The first step is to define different categories, which is a crucial step because the entire procedure depend on it. Each category you define must be detailed, containing all the relevant information that truly highlights that category. For example, if someone asks for information on the latest SPIN technique for fine-tuning LLM released in 2024, it must fall under the category of “research_papers”. ****Similarly, if someone ask about the winner of yesterday’s football match between TeamX and TeamY, it should be categorized under “football_match_statistics”, and so forth.
# Dictionary with main category names as keys
categories_data = {
'sports_stats': 'Statistics and performance metrics of professional athletes and sports personalities',
'entertainment_updates': 'Latest developments, news, and highlights about your favorite movies, TV shows, and celebrities',
'current_events': 'Up-to-the-minute coverage of breaking news on global current events',
'research_papers': 'Exploration of research papers and scholarly articles on various topics',
}I have defined 4 important categories where the keys represent their category names, and the values provide detailed, concise information about what each category is about. The more categories you provide, the greater the effort required, but it also enhances your LLM’s awareness of recent events.
Next, we need to convert our defined categories into embedding vectors and apply cosine similarity to map it with closest category. There are various methods to achieve this, such as using pretrained word2vec models or Spacy en_core_web_lg. Through my testing, two of the most satisfactory approaches are either utilizing a semantic search LLM or a multi-model like Gemini.
For semantic search, Hugging Face has a variety of LLMs available. However, our requirement is that the LLM size must be as small as possible while still providing satisfactory results. For this reason, I have tried several LLMs, and among them, I found the **“sentence_similarity_LLM” from **Sakil. Its size is only 265 MB, and it can be easily used for inference within approximately 0.1 seconds.
# Import the SentenceTransformer class from the sentence_transformers library
from sentence_transformers import SentenceTransformer
# Specify the pre-trained model name to be used
model_HF_name = "Sakil/sentence_similarity_semantic_search"
# Create an instance of the SentenceTransformer model using the specified pre-trained model
model_HF = SentenceTransformer(model_HF_name)
# Get the values from the 'categories_data' dictionary and convert them to a list
# Then, encode the list of category values using the SentenceTransformer model and convert the result to a PyTorch tensor
categories_data_embeddings_hf_ = model_HF.encode(list(categories_data.values()), convert_to_tensor=True)The above code will encode our categories data into embedding vectors using an open-source Hugging Face LLM. Similarly, using “Gemini MultiModel”, we can easily encode our data with its free API. Alternatively, the OpenAI API is an option, but it involves a cost, and its embedding vector may not perform as effectively as Gemini MultiModel.
# setting the api key
genai.configure(api_key="YOUR_API_KEY")
# Define a function to calculate the embeddings of the input text
def model_MM(input_text):
categories_data_embeddings_MM_ = genai.embed_content(
model="models/embedding-001",
content=input_text,
task_type="retrieval_document",
title="Embedding of inputs")
return categories_data_embeddings_MM_['embedding']
# calculate embedding of sentence2 and categories_data
categories_data_embeddings_MM_ = model_MM(list(categories_data.values()))Now that we have coded two approaches to calculate the embedding of categories, we need to implement a function for cosine similarity that takes the embedding vectors, models and a user prompt.
def find_best_result(user_prompt, embedding_model_MM, embedding_model_hf, categories_data_embeddings_MM, categories_data_embeddings_hf):
# Convert user prompt to embedding vector
user_prompt_embedding_MM = embedding_model_MM([user_prompt])
user_prompt_embedding_hf = embedding_model_hf.encode([user_prompt], convert_to_tensor=True)
# Calculate cosine similarity with categories data embeddings
similarity_scores_MM = cosine_similarity(user_prompt_embedding_MM, categories_data_embeddings_MM)
similarity_scores_hf = cosine_similarity(user_prompt_embedding_hf, categories_data_embeddings_hf)
# Find the index of the best result with the highest score for both models
best_result_index_MM = np.argmax(similarity_scores_MM)
best_result_index_hf = np.argmax(similarity_scores_hf)
# Get the best first result with the highest score for both models
best_result_MM = list(categories_data.keys())[best_result_index_MM]
best_result_hf = list(categories_data.keys())[best_result_index_hf]
return best_result_MM, best_result_hfWe can use this function to detect the category being assigned to user prompt.
# User prompt
user_prompt = "what is self play fine tuning in LLM"
# Find the best result with the highest score for both models
best_result_MM, best_result_hf = find_best_result(user_prompt, model_MM, model_HF, categories_data_embeddings_MM_, categories_data_embeddings_hf_)
# Print the results
print("Best result from MM model:", best_result_MM)
print("Best result from HF model:", best_result_hf)
######## OUTPUT ########
Best result from MM model: research_papers
Best result from HF model: research_papers
######## OUTPUT ########Both models categorized the input under the correct category, “research_papers” and the computation time was below 1 second. Let’s test it with a number of prompts and see if one lags compared to the other.
<iframe src="https://medium.com/media/a0c76adb3c1444f9bdf83d7a231ebb36" frameborder=0></iframe>I used 100 different user prompts to determine the accuracy (code is available here). Multi-Model (MM) proved to be more accurate in categorizing user prompts for different categories compared to the Hugging Face (HF) model. This accuracy can be further increased by providing more detailed information for each category.

We will be using the Gemini Multi-Model for classification due to its accuracy. Based on the identified category, it must trigger the correct API. For example, if the user prompt is “What is self-play fine-tuning in LLM” after Gemini Multi-Model identifies it lies in the “research_papers” category, **ArXiv API (Licencse) **will get triggered. Alternatively, you can use any other API of your choice, as long as it correctly fetches the data based on the prompt. I chose ArXiv because it contains more than 2.3 million papers and includes the latest information. Let’s implement it in code.
# Define a function named 'query_arxiv' that takes a search query, start position, and maximum results as parameters.
def query_arxiv(search_query, start=0, max_results=2):
# Define the base URL for the ArXiv API.
base_url = "http://export.arxiv.org/api/query?"
# Create a dictionary 'query_params' with the specified parameters for the API query.
query_params = {
'search_query': f'all:{search_query}', # Construct the search query parameter.
'start': start, # Set the start position parameter.
'max_results': max_results # Set the maximum results parameter.
}
# Make an HTTP GET request to the ArXiv API using the 'requests.get' function with the constructed URL and parameters.
response = requests.get(base_url, params=query_params)
# Use regular expression (regex) to extract content between '<summary>' tags in the API response.
summaries = re.findall('<summary>(.*?)</summary>', response.text, re.DOTALL)
# Replace newline and tab characters with spaces, and trim leading/trailing spaces for each summary.
# Join the modified summaries into a single string separated by spaces.
merged_summary = ' '.join(summary.replace('\n', ' ').replace('\t', ' ').strip() for summary in summaries)
# Return the merged and cleaned summary.
return merged_summaryI have set the default “max_result” value to 1, meaning it fetches only one relevant paper. You can set it according to your preference. Once it fetches the information, it will combine the abstracts of all the relevant papers. I have chosen to fetch the abstracts. You can fetch the entire paper using their guide. However, using complete papers would be irrelevant. This is because feeding the entire paper to our Base LLM would exceed its context length and may result in an error.
In a similar scenario, what if the user prompt is related to the current events category, such as “Where is Cyclone Anggrek heading?” This cyclone is currently active and is expected to lose its intensity in the upcoming days, concluding by this Wednesday (31–1–2024). Fetching the latest information from a news API can be costly, as most free tiers offer only 100 requests per day. However, the Bing News API’s free tier provides 1000 requests per month, which is sufficient for exploration and testing to determine if it fetches relevant information. Even for deployment purposes, their paid plan is reasonably priced. Moreover, Bing News is considered more reliable as they have their own news platform instead of relying on external sources. This ensures a diverse range of news for each searched query.
Although, similar to the ArXiv API where we passed the entire user prompt, this approach won’t work with the “current_events” category. We need to extract important entities from the user prompt to pass them in the API. otherwise, the search results won’t be accurate. For this purpose, we can use either NLTK or SpaCy to extract entities.
def extract_keywords(text):
# Tokenize, remove stopwords, and merge into a string
merged_words = ' '.join([word for word in word_tokenize(text) if word.lower() not in set(stopwords.words('english'))])
# Remove ? ! , . from the string
# strip the string
merged_words = merged_words.strip()
# Print the remaining keywords
return merged_words
# Example usage
prompt = "when will apple be releasing their electric vehicles?"
extract_keywords(prompt)
######## OUTPUT ########
Apple releasing electric vehicles
######## OUTPUT ########The provided code is a quick and effective approach to extract entities from a user prompt. I passed a sample prompt to it, and it extracted only the relevant entities, making it easy for our Bing API to recognize relevant news. Now, let’s code how the Bing API will fetch information based on the extracted entities.
def get_current_information(query):
# Hardcoded values for the URL and subscription key
search_url = "https://api.bing.microsoft.com/v7.0/news/search" # actual search URL
subscription_key = "YOUR_BING_NEWS_API_KEY" # Replace with the actual subscription key
# Make the API request
response = requests.get(search_url, headers={"Ocp-Apim-Subscription-Key": subscription_key},
params={"q": query, "textDecorations": True, "textFormat": "HTML"})
response.raise_for_status()
# Extract descriptions from the response
descriptions = [item.get('description', '') for item in json.loads(json.dumps(response.json())).get('value', [])]
# Clean and format the descriptions
cleaned_description = re.sub('<.*?>', '', '\n'.join(descriptions))
cleaned_description = re.sub('\.\.\.', '', cleaned_description)
cleaned_description = re.sub(''', "'", cleaned_description)
return cleaned_descriptionThere are many parameters such as how many results you want, or how latest the information must be, you can pass such params in bing search api from the given guide. I have set it to default, a bit text cleaning is required on the fetched output.
Now that we have coded two important categories, it provides insight into how the latest information can be extracted using APIs. Similarly, suppose you want your LLM to extract the current stock price. In that case, it must extract entities from the prompt, and then those entities should be passed to your stock API, such as the Polygon API. It will return the current price of that stock.

Up until now, we have implemented each component into functions, making it easier for us to code the final part of our architecture by simply calling those functions. Let’s examine how the structure of our code in this section looks like:
-
User prompt will be classified based on given categories using Gemini Multi-Model. We chose this option for better accuracy.
-
Based on the classified category, it will trigger the right API. For certain categories like “current_events,” we have to extract entities from the user prompt. Based on those entities, it will fetch relevant information.
-
The fetched information will then be passed, along with the user prompt, into our base LLM, which will generate an answer based on the provided information.
def find_best_result_MM(user_prompt, embedding_model_MM, categories_data_embeddings_MM):
# Convert user prompt to embedding vector
user_prompt_embedding_MM = embedding_model_MM([user_prompt])
# Calculate cosine similarity with categories data embeddings
similarity_scores_MM = cosine_similarity(user_prompt_embedding_MM, categories_data_embeddings_MM)
# Find the index of the best result with the highest score for both models
best_result_index_MM = np.argmax(similarity_scores_MM)
# Get the best first result with the highest score for both models
best_result_MM = list(categories_data.keys())[best_result_index_MM]
return best_result_MMSince we are exclusively relying on Gemini MultiModel for classifying user prompts, I have updated the function accordingly.
# Define the sample user prompt
user_prompt = "what is the spin technique for fine-tuning a language model?"
# Determine the category using the multimodal model
category_result = find_best_result_MM(user_prompt, model_MM, categories_data_embeddings_MM_)
# Retrieve information based on the determined category
if category_result == 'research_papers':
information = query_arxiv(user_prompt)
elif category_result == 'current_events':
information = get_current_information(extract_keywords(user_prompt))
# Create a prompt template with the obtained information
prompt_template = f'''
{information}
answer the following question in a detailed manner based on the above information
{user_prompt}
'''
# Generate a response from the base language model using the provided prompt
output = base_LLM.generate(inputs=model_inputs, do_sample=True, max_new_tokens=2048)
# Decode and print the generated response
decoded_response = tokenizer.decode(output[0])
print(decoded_response)
######## OUTPUT ########
The Self-Play Fine-tuNing (SPIN) technique ... preference data.
######## OUTPUT ########We have implemented the entire architecture for just two categories, and you can extend it for as many categories as needed. Although keep in mind that manual efforts will be required for each category. I passed a user prompt related to a new SPIN technique invented in 2024. Gemini classified it in the “research_papers” category, triggering the ArXiv API to fetch relevant information. This information is then passed to our base LLM, which generates a response based on the provided information and the user prompt. The entire process took 5 seconds to generate the response.
Now that we have coded the entire architecture, let’s build a simple chatbot using Streamlit to provide a better visual representation and avoid rerunning the code. Each example took 4 seconds inference time.
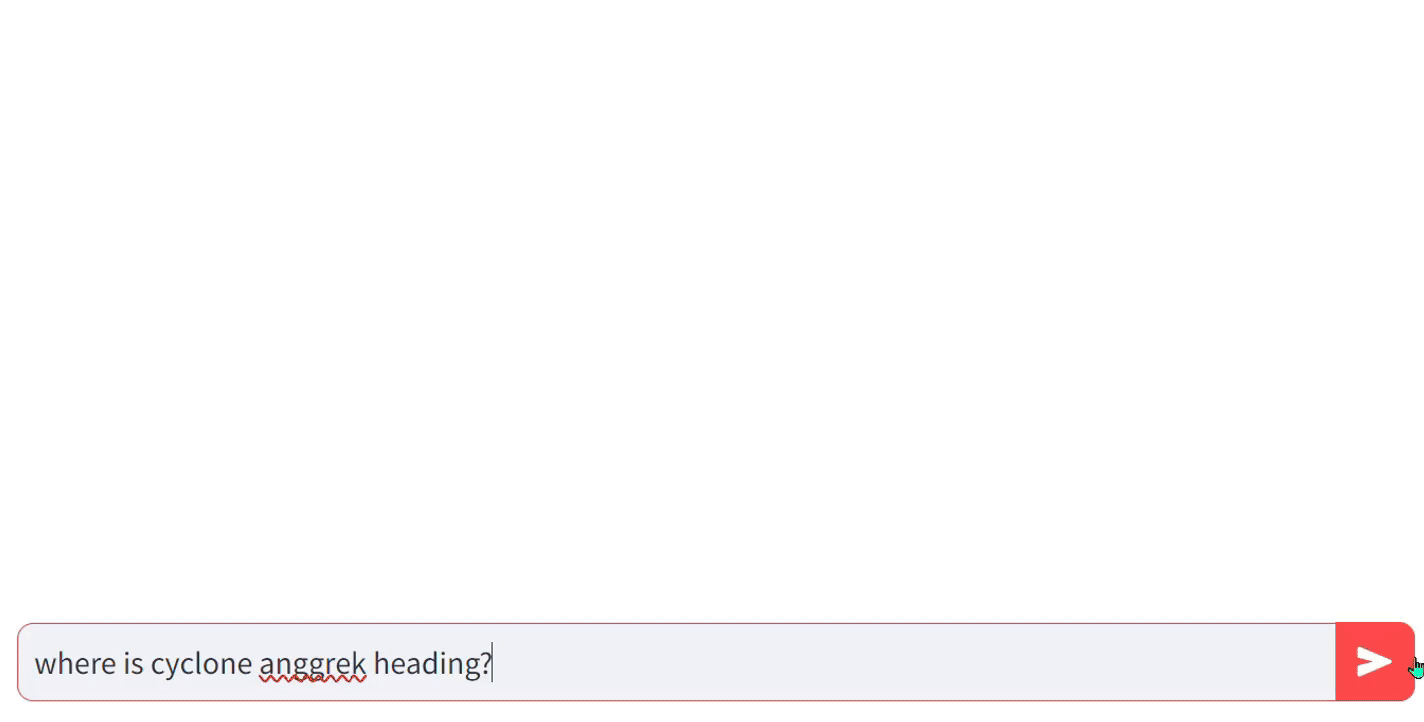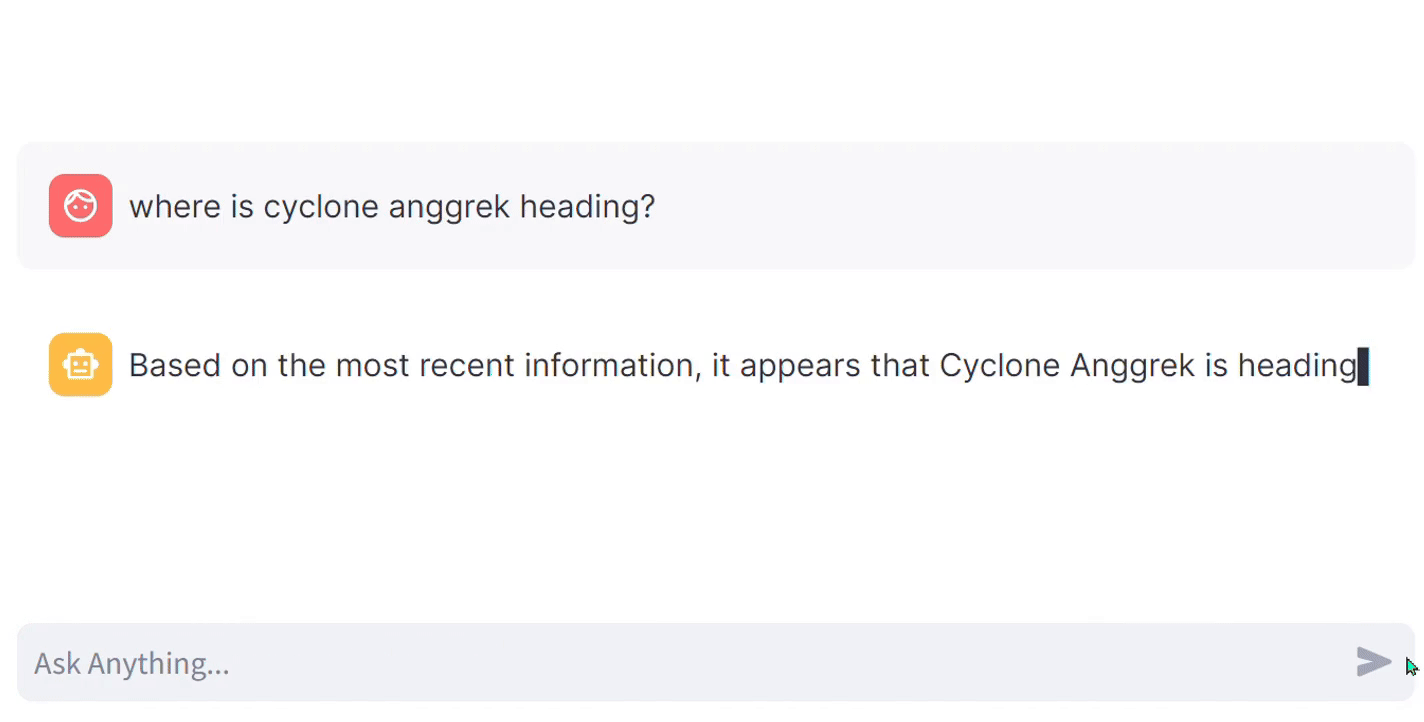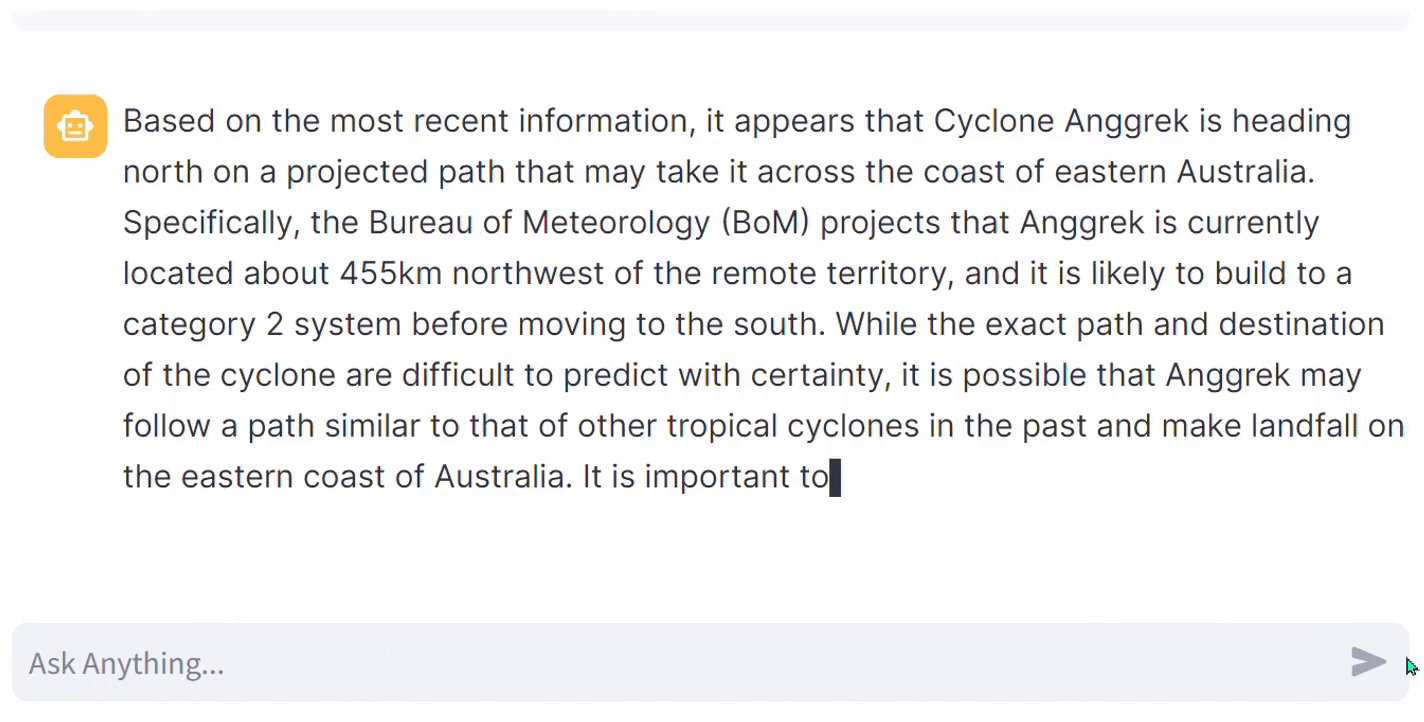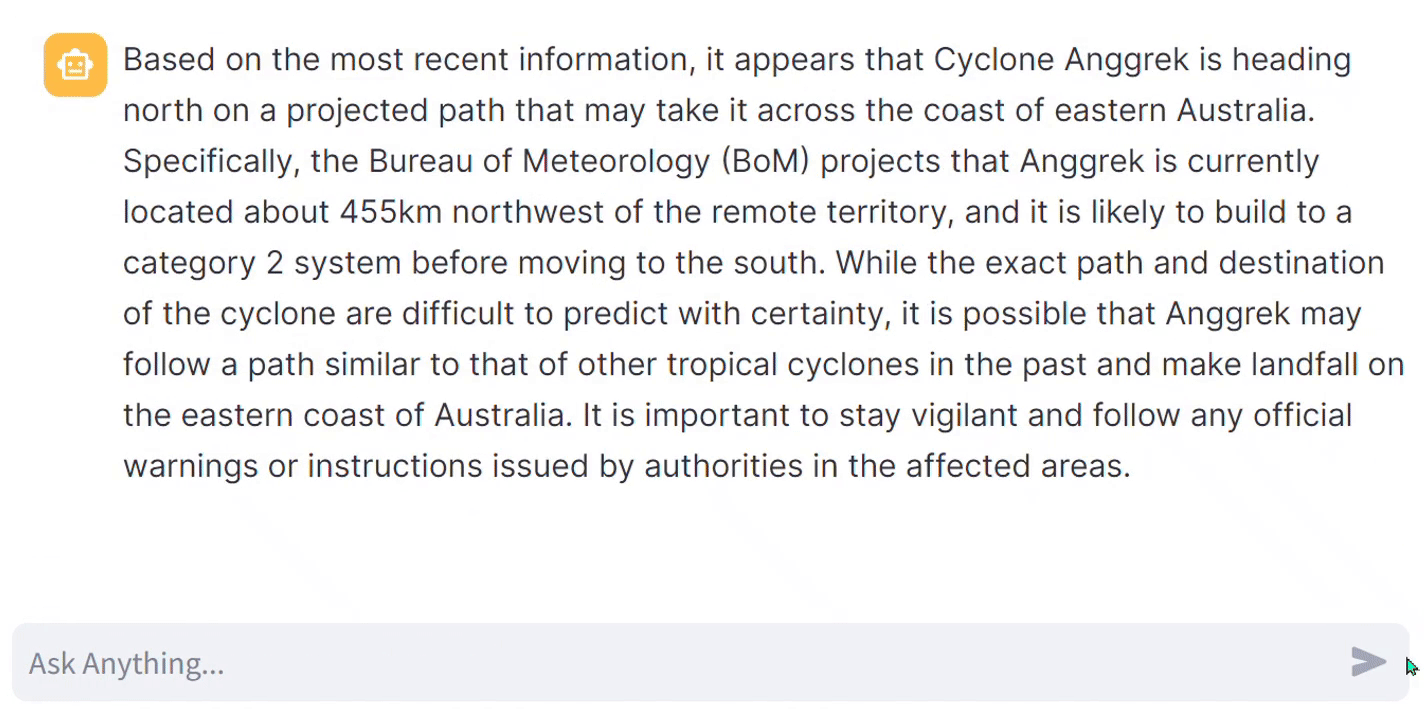

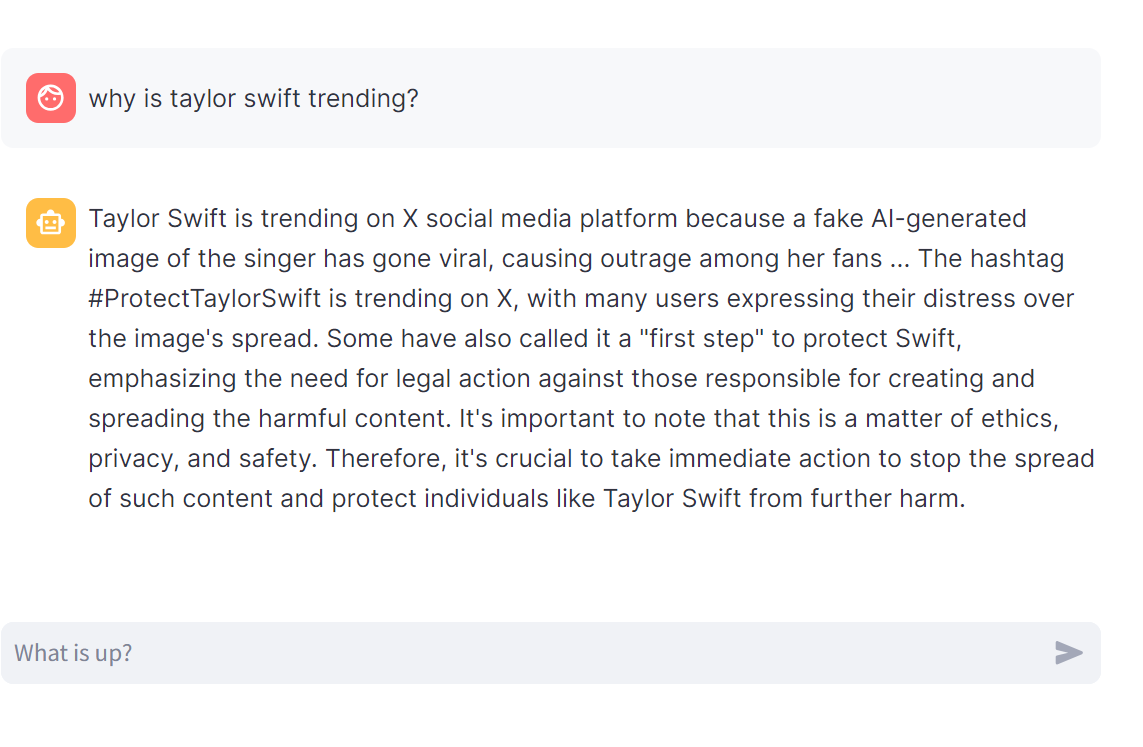
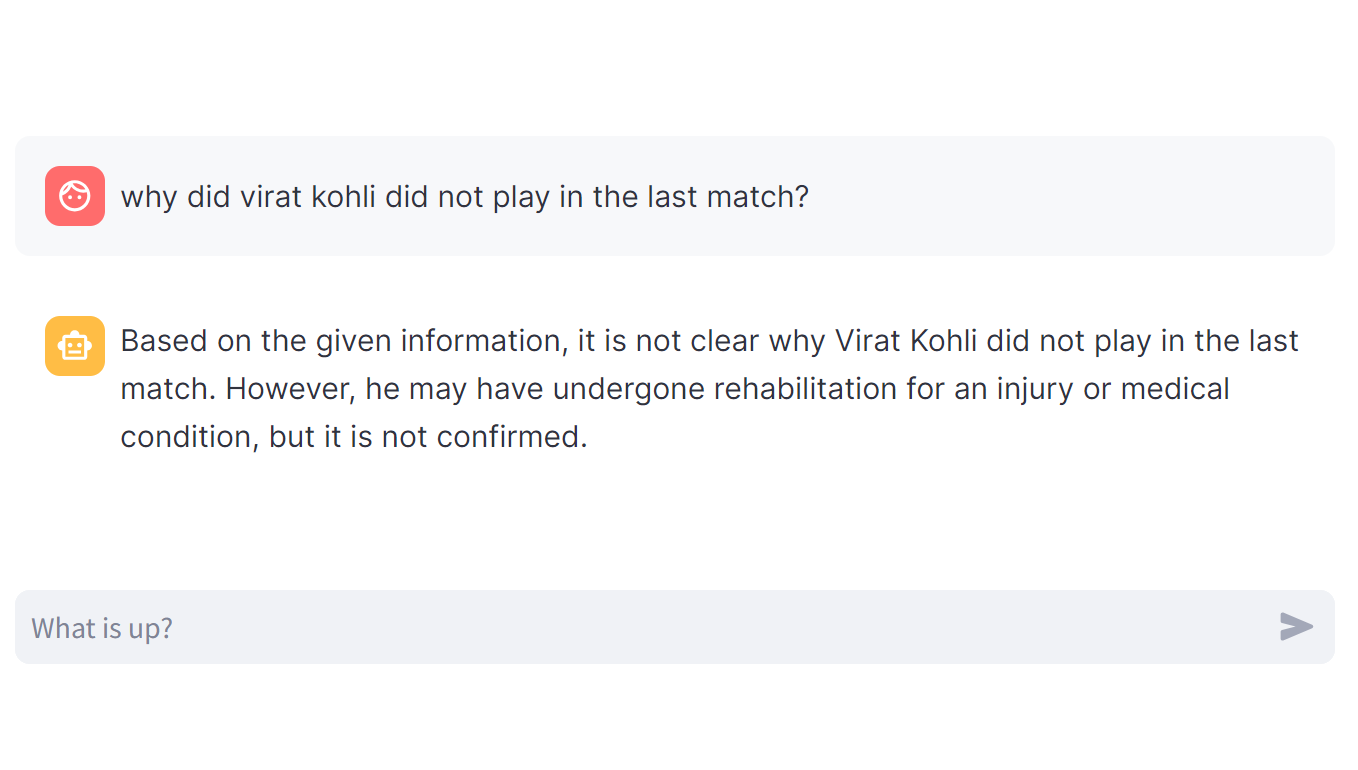

Since I have implemented API code for just two categories, most of the questions I have asked here are related to only those two categories. However, you can extend it to a larger-scale project. Extending it to a larger scale will require cost calculation along with a more comprehensive methodology for our implemented architecture, which is what our next section is about.
When scaling this architecture, how you define categories becomes crucial. The more detailed the category, the higher the chances of correctly classifying the user prompt. You can use “ChatGPT” or “Gemini” to write a comprehensive description of your category. I used the Gemini embedding model to convert the text to embeddings. For larger-scale implementation, Gemini is still a better choice compared to other open-source LLMs.
The function I used to find the closeness (cosine similarity) remains effective and quick even when dealing with large-scale data. The key consideration after defining categories is the total cost. For a small scale (single category LLM), you won’t encounter issues as many API free tiers offer suitable subscriptions, especially if you have a low number of requests per hour or day. Some APIs provide more flexibility even when scaling your project to a larger scale, such as the Bing News API we discussed earlier.
I cannot provide an exact cost estimate as it depends on the scalability of your architecture. However, if you work with 10 categories, the minimum cost you might incur is approximately $20 per month, excluding the cost of hosting your base LLM.
Try implementing this architecture with a smaller base LLM and measure its accuracy. Often, you may deploy an LLM for a specific task, like retrieving information based on tweets, where the cost is significantly lower, or in some cases, you might not incur any costs at all. Another option is to use Ansyscale API, which provides $10 in free credits, allowing you to test various LLMs with this architecture quickly without depending on Colab or Kaggle. Thank you for reading this comprehensive post!