813 better error handling #936
Conversation
Codecov Report
@@ Coverage Diff @@
## main #936 +/- ##
==========================================
+ Coverage 99.66% 99.87% +0.20%
==========================================
Files 171 171
Lines 8771 8783 +12
==========================================
+ Hits 8742 8772 +30
+ Misses 29 11 -18
Continue to review full report at Codecov.
|

| @@ -72,11 +72,12 @@ def test_search_results(X_y_regression, X_y_binary, X_y_multi, automl_type): | |||
| index=['id', 'pipeline_name', 'score', 'high_variance_cv', 'parameters'])) | |||
|
|
|||
|
|
|||
| @patch('evalml.pipelines.BinaryClassificationPipeline.score') | |||
| @patch('evalml.pipelines.BinaryClassificationPipeline.fit') | |||
| @patch('evalml.pipelines.ClassificationPipeline.score') | |||
There was a problem hiding this comment.
Made this change because both multiclass and binary problems are tested here.
There was a problem hiding this comment.
Hm, looks like we're only using the X_y_binary fixture though, could you update this for the multiclass test (or just move it out / parametrize it)?
| @@ -128,15 +129,9 @@ def test_pipeline_fit_raises(mock_fit, X_y_binary, caplog): | |||
| msg = 'all your model are belong to us' | |||
| mock_fit.side_effect = Exception(msg) | |||
| X, y = X_y_binary | |||
| automl = AutoMLSearch(problem_type='binary', max_pipelines=1) | |||
There was a problem hiding this comment.
Deleted this bit because raise_errors does not exist.
| @@ -157,22 +152,17 @@ def test_pipeline_score_raises(mock_score, X_y_binary, caplog): | |||
| mock_score.side_effect = Exception(msg) | |||
| X, y = X_y_binary | |||
| automl = AutoMLSearch(problem_type='binary', max_pipelines=1) | |||
| with pytest.raises(Exception, match=msg): | |||
There was a problem hiding this comment.
Same here. I deleted this because raise_errors doesn't exist.
| cv_scores_all = pipeline_results[0]["cv_data"][0]["all_objective_scores"] | ||
| objective_scores = {o.name: cv_scores_all[o.name] for o in [automl.objective] + automl.additional_objectives} | ||
|
|
||
| assert np.isnan(list(objective_scores.values())).all() |
There was a problem hiding this comment.
Whenever _compute_cv_scores raises an exception that is not of type PipelineScoreError, alI the scores are set to nan (because the exception happened before scoring). I modified this check to reflect that.
| if predictions.ndim > 1: | ||
| predictions = predictions.iloc[:, 1] | ||
| return ClassificationPipeline._score(X, y, predictions, objective) | ||
| def _compute_predictions(self, X, objectives): |
There was a problem hiding this comment.
See my comment in PipelineBase._score explaining the reasoning behind this change.
evalml/automl/automl_search.py
Outdated
| logger.info(intro_message) | ||
| logger.info(score_message) | ||
| logger.info(filename_message) | ||
| logger.debug(hyperparameter_message) |
There was a problem hiding this comment.
Decided to log the hyperparameters at the debug level to not clutter stdout.
There was a problem hiding this comment.
Nice
I'm having trouble tracking how the declarations match up with the log call order. Can we just do direct logging out for some of these? Like logger.info(f"\t\t\tFold {i}: Please check {logger.handlers[1].baseFilename} for the current hyperparameters and stack trace."), instead of including the intermediate variable
evalml/pipelines/pipeline_base.py
Outdated
| @@ -231,17 +237,36 @@ def score(self, X, y, objectives): | |||
| """ | |||
|
|
|||
| @staticmethod | |||
| def _score(X, y, predictions, objective): | |||
| def _score(X, y, predictions, predicted_probabilities, objectives, is_objective_suitable=None): | |||
There was a problem hiding this comment.
Since Pipelines will no longer suppress errors, the old implementation of _score was no longer doing anything. I decided to repurpose it to store the logic for creating the PipelineScoreError in one place for classification and regression pipelines.
I ran into two obstacles:
- The old _score implementation for binary classification pipelines had some logic for collapsing the last dim of the predictions. I fixed this issue by moving that logic to _compute_predictions in BinaryClassificationPipeline.
- In regression problems, we check if the objective has
score_needs_probaset to True and if so, raise a ValueError. I replaced this functionality with theis_objective_suitableparameter. But maybe we should just get rid of this check when PR Have automl search raise config errors in init instead of search #933 gets merged?
| @@ -27,13 +26,11 @@ def score(self, X, y, objectives): | |||
| if not isinstance(y, pd.Series): | |||
| y = pd.Series(y) | |||
|
|
|||
| objectives = [get_objective(o) for o in objectives] | |||
| scores = OrderedDict() | |||
| def is_objective_suitable_for_regression(objective): | |||
There was a problem hiding this comment.
See my comment in PipelineBase._score explaining this change.
| y_predicted = self.predict(X) | ||
| for objective in objectives: | ||
| if objective.score_needs_proba: | ||
| raise ValueError("Objective `{}` does not support score_needs_proba".format(objective.name)) |
There was a problem hiding this comment.
Edited this message because I thought it was not clear.
docs/source/changelog.rst
Outdated
| * Pipelines will now raise a `PipelineScoreError` when they encounter an error during scoring :pr:`936` | ||
| * AutoML will now log hyperparameters and stacktraces for pipelines that encounter an error during search :pr:`936` |
There was a problem hiding this comment.
Could we reword these via past tense verbs :D
docs/source/changelog.rst
Outdated
| @@ -27,6 +29,7 @@ Changelog | |||
| * ``list_model_families`` has been moved to ``evalml.model_family.utils`` (previously was under ``evalml.pipelines.utils``) :pr:`903` | |||
| * Static pipeline definitions have been removed, but similar pipelines can still be constructed via creating an instance of PipelineBase :pr:`904` | |||
| * ``all_pipelines()`` and ``get_pipelines()`` utility methods have been removed :pr:`904` | |||
| * Removed the "raise_errors" flag in AutoML search. All errors during pipeline evaluation will be caught and logged. :pr:`936` | |||
| self._add_result(trained_pipeline=baseline, | ||
| parameters=baseline.parameters, | ||
| training_time=baseline_results['training_time'], | ||
| cv_data=baseline_results['cv_data'], | ||
| cv_scores=baseline_results['cv_scores']) | ||
|
|
||
| def _compute_cv_scores(self, pipeline, X, y, raise_errors=True): | ||
| def _compute_cv_scores(self, pipeline, X, y): |
There was a problem hiding this comment.
I'm so glad we're removing the passing around of raise_errors :))))
evalml/automl/automl_search.py
Outdated
| raise e | ||
| score = np.nan | ||
| scores = OrderedDict(zip([n.name for n in self.additional_objectives], [np.nan] * len(self.additional_objectives))) | ||
| filename_message = f"\t\t\tFold {i}: Please check {logger.handlers[1].baseFilename} for the current hyperparameters and stacktrace." |
There was a problem hiding this comment.
stacktrace --> stack trace
| try: | ||
| dummy_regression_pipeline_class(parameters={}).score(X, y, ['precision', 'auc']) | ||
| except PipelineScoreError as e: | ||
| assert "Objective `AUC` is not suited for regression problems." in e.message |
There was a problem hiding this comment.
Curious about this try/except pattern in testing. Is there no way to keep the pytest.raises pattern? My concern is that if we make a change / bug where we accidentally don't raise PipelineScoreError, we won't ever check the assert message and won't catch this issue, even if we should! If there's no way to use the pytest.raises to check for custom fields, it could be worth keeping it in so we know we're raising the correct exception?
There was a problem hiding this comment.
Originally I kept pytest.raises but the problem is that if you have something like
with pytest.raises(PipelineScoreError) as e:
_ = clf.score(X, y, objective_names)
assert e.scored_successfully == {"Precision Micro": 1.0}
assert 'finna kabooom 💣' in e.message
assert "F1 Micro" in e.exceptions
Pytest won't run anything after the method that raises the expected error (in this case clf.score).
One thing I tried was something like:
with pytest.raises(PipelineScoreError) as e:
_ = clf.score(X, y, objective_names)
assert e.scored_successfully == {"Precision Micro": 1.0}
assert 'finna kabooom 💣' in e.message
assert "F1 Micro" in e.exceptions
But the problem is that pytest changes the type of e from PipelineScoreError to something pytest specific so it makes making the checks harder and more confusing.
I take your point that if we no longer raise PipelineScoreError, we wouldn't know if the test failed. I see two solutions:
- Combine
pytest.raiseswithtry/except
with pytest.raises(PipelineScoreError) as e:
_ = clf.score(X, y, objective_names)
try:
_ = clf.score(X, y, objective_names)
except PipelineScoreError as e:
assert e.scored_successfully == {"Precision Micro": 1.0}
assert 'finna kabooom 💣' in e.message
assert "F1 Micro" in e.exceptions
- Assert that we do not continue after the line that should raise an exception:
try:
_ = clf.score(X, y, objective_names)
assert False, "Score should raise a PipelineScoreError!"
except PipelineScoreError as e:
assert e.scored_successfully == {"Precision Micro": 1.0}
assert 'finna kabooom 💣' in e.message
assert "F1 Micro" in e.exceptions
Happy to do either - what are your thoughts?
There was a problem hiding this comment.
Ah, thanks for the explanation! I don't have a clear preference for either solution and think they're both pretty clear. Perhaps the second solution seems cleaner / more efficient since we only have to call score once? But ultimately both look great :D
There was a problem hiding this comment.
Great, I'll go for the second!
There was a problem hiding this comment.
Nice discussion!! 🚀
I like option 2 as well.
One addition to make: use pytest.fail
try:
_ = clf.score(X, y, objective_names)
pytest.fail("Score should raise a PipelineScoreError!")
except PipelineScoreError as e:
assert e.scored_successfully == {"Precision Micro": 1.0}
assert 'finna kabooom 💣' in e.message
assert "F1 Micro" in e.exceptionsThere was a problem hiding this comment.
Actually, I'll use the first option since it is easier to make circleci pass since the assert False or pytest.fail lines would not run right now.
evalml/pipelines/pipeline_base.py
Outdated
| def _score(X, y, predictions, predicted_probabilities, objectives, is_objective_suitable=None): | ||
| """Given data, model predictions or predicted probabilities computed on the data, and an objective, evaluate and return the objective score. | ||
|
|
||
| Will return `np.nan` if the objective errors. | ||
| Will raise a PipelineScoreError if any objectives fail. | ||
| Arguments: | ||
| X (pd.DataFrame): The feature matrix. | ||
| y (pd.Series): The labels. | ||
| predictions (pd.Series): The pipeline predictions. | ||
| predicted_probabilities (pd.Dataframe, pd.Series, None): The predicted probabilities for classification problems. | ||
| Will be a DataFrame for multiclass problems and Series otherwise. Will be None for regression problems. | ||
| objectives (list): List of objectives to score. | ||
| is_objective_suitable (callable): Function to check whether the objective function is suitable for the problem. | ||
| For example, AUC is not suitable for regression problems. | ||
| """ | ||
| score = np.nan | ||
| try: | ||
| score = objective.score(y, predictions, X) | ||
| except Exception as e: | ||
| logger.error('Error in PipelineBase.score while scoring objective {}: {}'.format(objective.name, str(e))) | ||
| return score | ||
| scored_successfully = OrderedDict() | ||
| exceptions = OrderedDict() | ||
| for objective in objectives: | ||
| try: | ||
| is_objective_suitable(objective) | ||
| score = objective.score(y, predicted_probabilities if objective.score_needs_proba else predictions, X) | ||
| scored_successfully.update({objective.name: score}) | ||
| except Exception as e: | ||
| tb = traceback.format_tb(sys.exc_info()[2]) | ||
| exceptions[objective.name] = (e, tb) | ||
| if exceptions: | ||
| # If any objective failed, throw an PipelineScoreError | ||
| raise PipelineScoreError(exceptions, scored_successfully) | ||
| else: | ||
| # No objectives failed, return the scores | ||
| return scored_successfully |
There was a problem hiding this comment.
Hmmm, I think I understand your comment but at least for this change, this refactor seems pretty large but not necessary for the better error handling? Perhaps for this PR we could just keep _score as it was, removing the try/except wrapper if we don't need that anymore, and then tackle this in a separate PR? I like the consolidation of evalml/pipelines/binary_classification_pipeline.py but would love to discuss this bit more and don't want it to block the rest of this PR's changes.
There was a problem hiding this comment.
Let's get on a call to discuss this!
There was a problem hiding this comment.
For those following, we decided to keep _score's old implementation (without the try except) to not introduce a breaking change and rename the method I call _score to _score_objectives.
| @@ -72,11 +72,12 @@ def test_search_results(X_y_regression, X_y_binary, X_y_multi, automl_type): | |||
| index=['id', 'pipeline_name', 'score', 'high_variance_cv', 'parameters'])) | |||
|
|
|||
|
|
|||
| @patch('evalml.pipelines.BinaryClassificationPipeline.score') | |||
| @patch('evalml.pipelines.BinaryClassificationPipeline.fit') | |||
| @patch('evalml.pipelines.ClassificationPipeline.score') | |||
There was a problem hiding this comment.
Hm, looks like we're only using the X_y_binary fixture though, could you update this for the multiclass test (or just move it out / parametrize it)?
4e216fb
to
3268bc6
Compare
There was a problem hiding this comment.
@freddyaboulton this looks really great!
My only blocking comment on the impl was about _score_all_objectives" I think we can delete/replace is_objective_suitable by checking the pipeline and objective problem_type matches. Will approve once we resolve that discussion!
docs/source/release_notes.rst
Outdated
| @@ -41,6 +43,7 @@ Release Notes | |||
| * ``list_model_families`` has been moved to ``evalml.model_family.utils`` (previously was under ``evalml.pipelines.utils``) :pr:`903` | |||
| * Static pipeline definitions have been removed, but similar pipelines can still be constructed via creating an instance of PipelineBase :pr:`904` | |||
| * ``all_pipelines()`` and ``get_pipelines()`` utility methods have been removed :pr:`904` | |||
| * Removed the "raise_errors" flag in AutoML search. All errors during pipeline evaluation will be caught and logged. :pr:`936` | |||
evalml/automl/automl_search.py
Outdated
| def search(self, X, y, data_checks="auto", feature_types=None, raise_errors=True, show_iteration_plot=True): | ||
| """Find the best pipeline for the data set. | ||
| def search(self, X, y, data_checks="auto", feature_types=None, show_iteration_plot=True): | ||
| """Find best classifier |
There was a problem hiding this comment.
@freddyaboulton let's not make this change. We're not just building classifiers :)
evalml/automl/automl_search.py
Outdated
| logger.info(intro_message) | ||
| logger.info(score_message) | ||
| logger.info(filename_message) | ||
| logger.debug(hyperparameter_message) |
There was a problem hiding this comment.
Nice
I'm having trouble tracking how the declarations match up with the log call order. Can we just do direct logging out for some of these? Like logger.info(f"\t\t\tFold {i}: Please check {logger.handlers[1].baseFilename} for the current hyperparameters and stack trace."), instead of including the intermediate variable
| exception_list = [] | ||
| for objective, (exception, tb) in exceptions.items(): | ||
| tb = [f"{objective} encountered {str(exception.__class__.__name__)} with message ({str(exception)}):\n"] + tb | ||
| exception_list.extend(tb) |
There was a problem hiding this comment.
exception_list.append(f"{objective} encountered {str(exception.__class__.__name__)} with message ({str(exception)}):\n")
exception_list.extend(tb)?
There was a problem hiding this comment.
The trace back (tb) is stored as a list of strings. I'm adding a "header" describing and the exception and the objective that raised it and then using extend to aggregate all the trace backs into a list of strings.
There was a problem hiding this comment.
Ah ok. My suggestion didn't do a good job of this but I was wondering why you need two lines instead of just one, calling append directly with the content
There was a problem hiding this comment.
Ah I see! Yes, I think that works.
evalml/pipelines/pipeline_base.py
Outdated
| exceptions = OrderedDict() | ||
| for objective in objectives: | ||
| try: | ||
| is_objective_suitable(objective) |
There was a problem hiding this comment.
@freddyaboulton what if instead of using is_objective_suitable, we had problem_type as input, and then added validation logic to this method _score_all_objectives:
if self.problem_type != objective.problem_type:
raise PipelineScoreError(f'Invalid objective {objective.name} specified for problem type {self.problem_type}')I think this covers all the cases your current code covers. The only objectives which can accept predicted probabilities are binary/multiclass problems. Therefore, if an objective's problem type doesn't match the pipelines' problem type, something is wrong. What do you think?
There was a problem hiding this comment.
Great idea! Much simpler than what I had in mind 👍 I'll implement this now.
| try: | ||
| dummy_regression_pipeline_class(parameters={}).score(X, y, ['precision', 'auc']) | ||
| except PipelineScoreError as e: | ||
| assert "Objective `AUC` is not suited for regression problems." in e.message |
There was a problem hiding this comment.
Nice discussion!! 🚀
I like option 2 as well.
One addition to make: use pytest.fail
try:
_ = clf.score(X, y, objective_names)
pytest.fail("Score should raise a PipelineScoreError!")
except PipelineScoreError as e:
assert e.scored_successfully == {"Precision Micro": 1.0}
assert 'finna kabooom 💣' in e.message
assert "F1 Micro" in e.exceptions…cit logging in AutoMLSearch._compute_cv_scores.
81851b1
to
9f1c75b
Compare
evalml/pipelines/pipeline_base.py
Outdated
| @@ -232,16 +238,39 @@ def score(self, X, y, objectives): | |||
|
|
|||
| @staticmethod | |||
| def _score(X, y, predictions, objective): | |||
| return objective.score(y, predictions, X) | |||
|
|
|||
| def _score_all_objectives(self, X, y, predictions, predicted_probabilities, objectives): | |||
There was a problem hiding this comment.
For naming consistency with the rest of the codebase, can we say y_pred and y_pred_proba / similar here?
evalml/pipelines/pipeline_base.py
Outdated
| predicted_probabilities (pd.Dataframe, pd.Series, None): The predicted probabilities for classification problems. | ||
| Will be a DataFrame for multiclass problems and Series otherwise. Will be None for regression problems. | ||
| objectives (list): List of objectives to score. | ||
| is_objective_suitable (callable): Function to check whether the objective function is suitable for the problem. |
There was a problem hiding this comment.
Can delete this from docstring
There was a problem hiding this comment.
Great to have this docstring though thanks for adding
evalml/pipelines/pipeline_base.py
Outdated
| if exceptions: | ||
| # If any objective failed, throw an PipelineScoreError | ||
| raise PipelineScoreError(exceptions, scored_successfully) | ||
| else: |
There was a problem hiding this comment.
Nit pick, no need for the else if the if raises
| scored_successfully.update({objective.name: score}) | ||
| except Exception as e: | ||
| tb = traceback.format_tb(sys.exc_info()[2]) | ||
| exceptions[objective.name] = (e, tb) |
There was a problem hiding this comment.
This is great! Easy to follow. Great that we generate the traceback too
| with pytest.raises(PipelineScoreError): | ||
| _ = clf.score(X, y, objective_names) | ||
| try: | ||
| _ = clf.score(X, y, objective_names) |
There was a problem hiding this comment.
@freddyaboulton I see you resolved the old comment about this, but why do we have both with raises ... and try/except? Can't we just use one or the other, and add pytest.fail(msg) here after the call to score?
There was a problem hiding this comment.
I think right now the pytest.fail(msg) line would not run so I would fail the circleci quality gate but with this implementation every line runs.
There was a problem hiding this comment.
Oh you mean codecov? Damn 🤦 makes sense.
… Also changing logging levels to what they were before.
docs/source/release_notes.rst
Outdated
| @@ -25,6 +25,8 @@ Release Notes | |||
| * Added text processing and featurization component `TextFeaturizer` :pr:`913`, :pr:`924` | |||
| * Added additional checks to InvalidTargetDataCheck to handle invalid target data types :pr:`929` | |||
| * AutoMLSearch will now handle KeyboardInterrupt and prompt user for confirmation :pr:`915` | |||
| * Modified Pipelines to raise `PipelineScoreError` when they encounter an error during scoring :pr:`936` | |||
There was a problem hiding this comment.
We should move these to Future Release!
| @@ -496,6 +494,7 @@ def _add_baseline_pipelines(self, X, y, raise_errors=True): | |||
| bool - If the user ends the search early, will return True and searching will immediately finish. Else, | |||
| will return False and more pipelines will be searched. | |||
| """ | |||
|
|
|||
There was a problem hiding this comment.
Should we remove raise_errors from def _add_baseline_pipelines(self, X, y, raise_errors=True)?
There was a problem hiding this comment.
(Docstring too if we do!)
Pull Request Description
Fixes #813 by
raise_errorsin AutoMLSearch and replacing it with more detailed logging of errors in_compute_cv_scores. We will explore adding logic to stop the search, e.g. all pipelines in a batch fail on the primary objective, in future PRs. See (Raise an error if all pipelines produce nan scores in automl #922)PipelineScoreErrorexception.Demo:
What the user sees
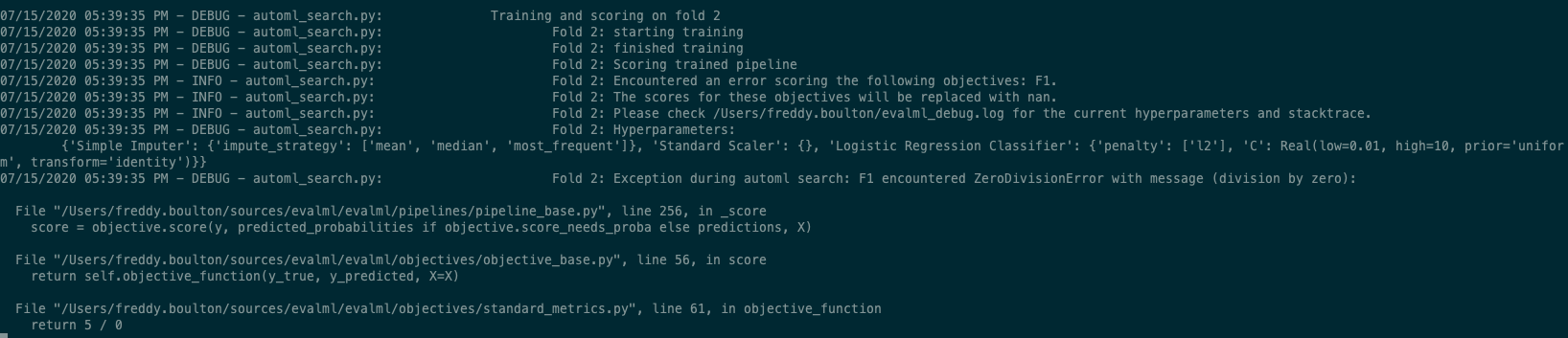
What the logs look like
Note that the hyperparameters and stacktrace are being logged.
After creating the pull request: in order to pass the changelog_updated check you will need to update the "Future Release" section of
docs/source/changelog.rstto include this pull request by adding :pr:123.