项目使用Python3.7获取前程无忧对应关键字的招聘,保存到mongodb,爬取下来的数据,可分析出目前互联网的近况,可统计到每个招聘岗位有多少,每个岗位的薪资分布情况
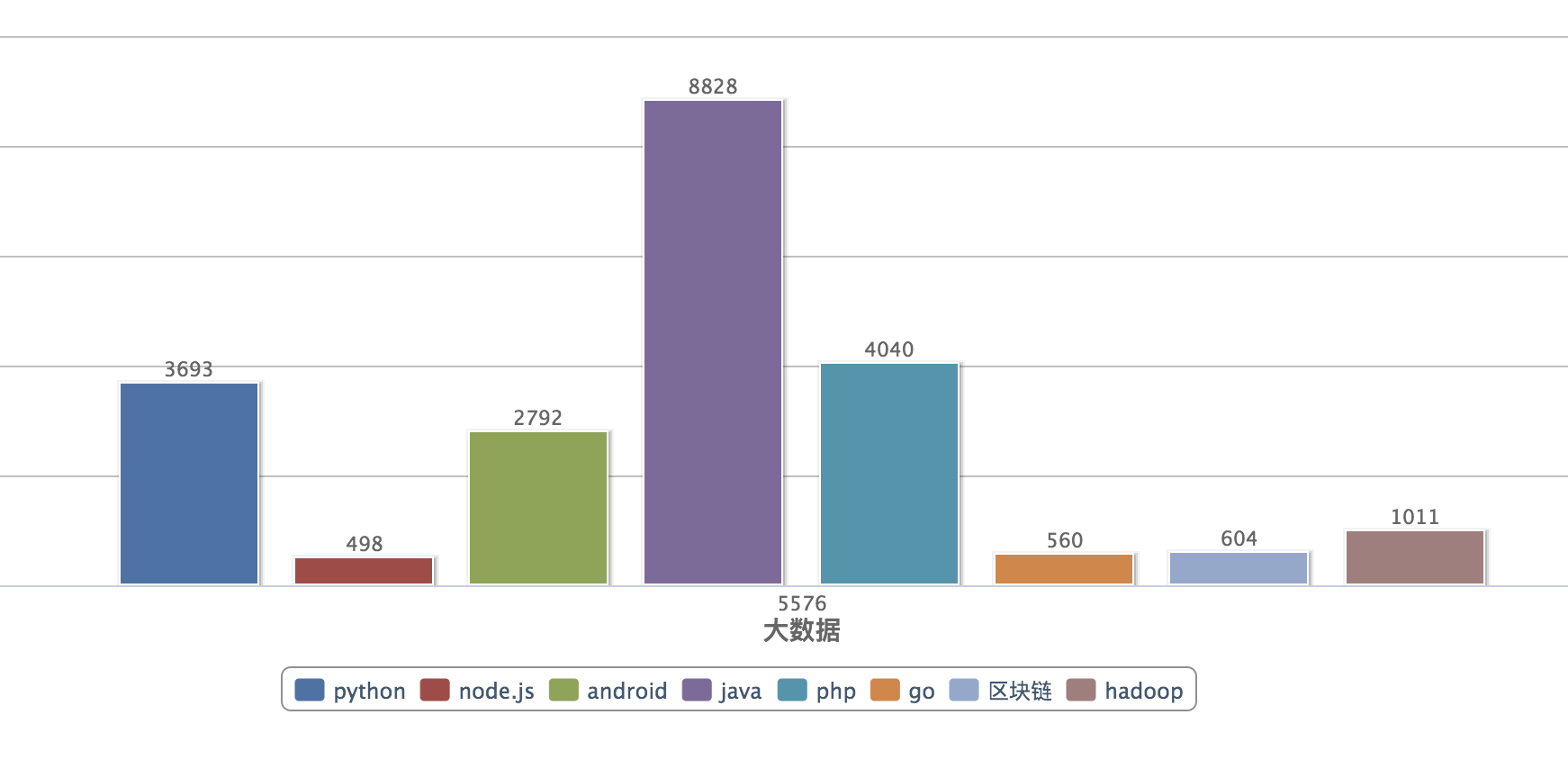
统计结果图,java还是老大哥啊
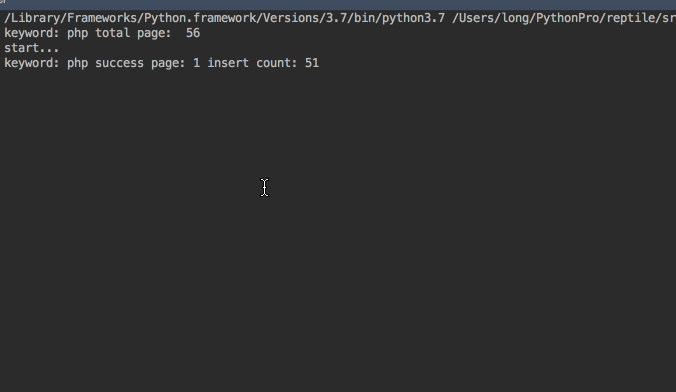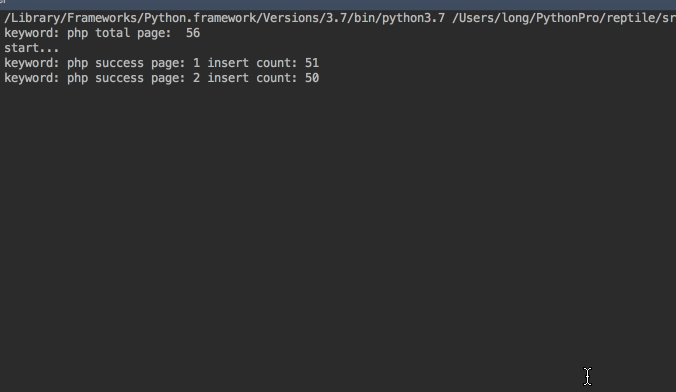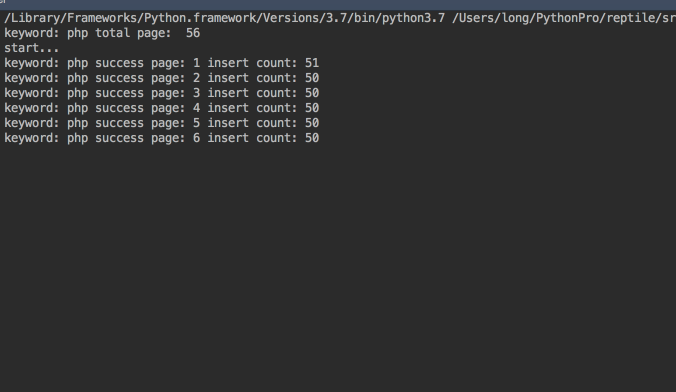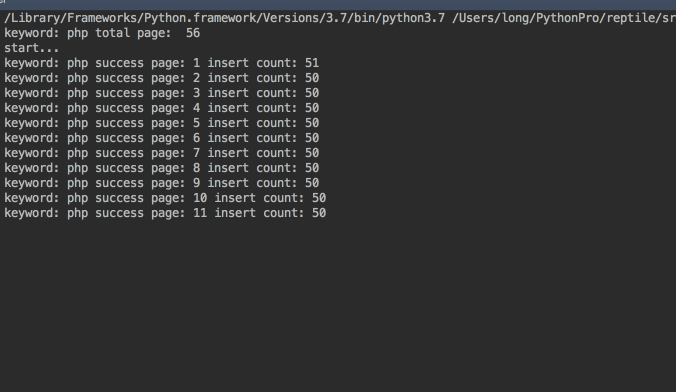
爬取效果图
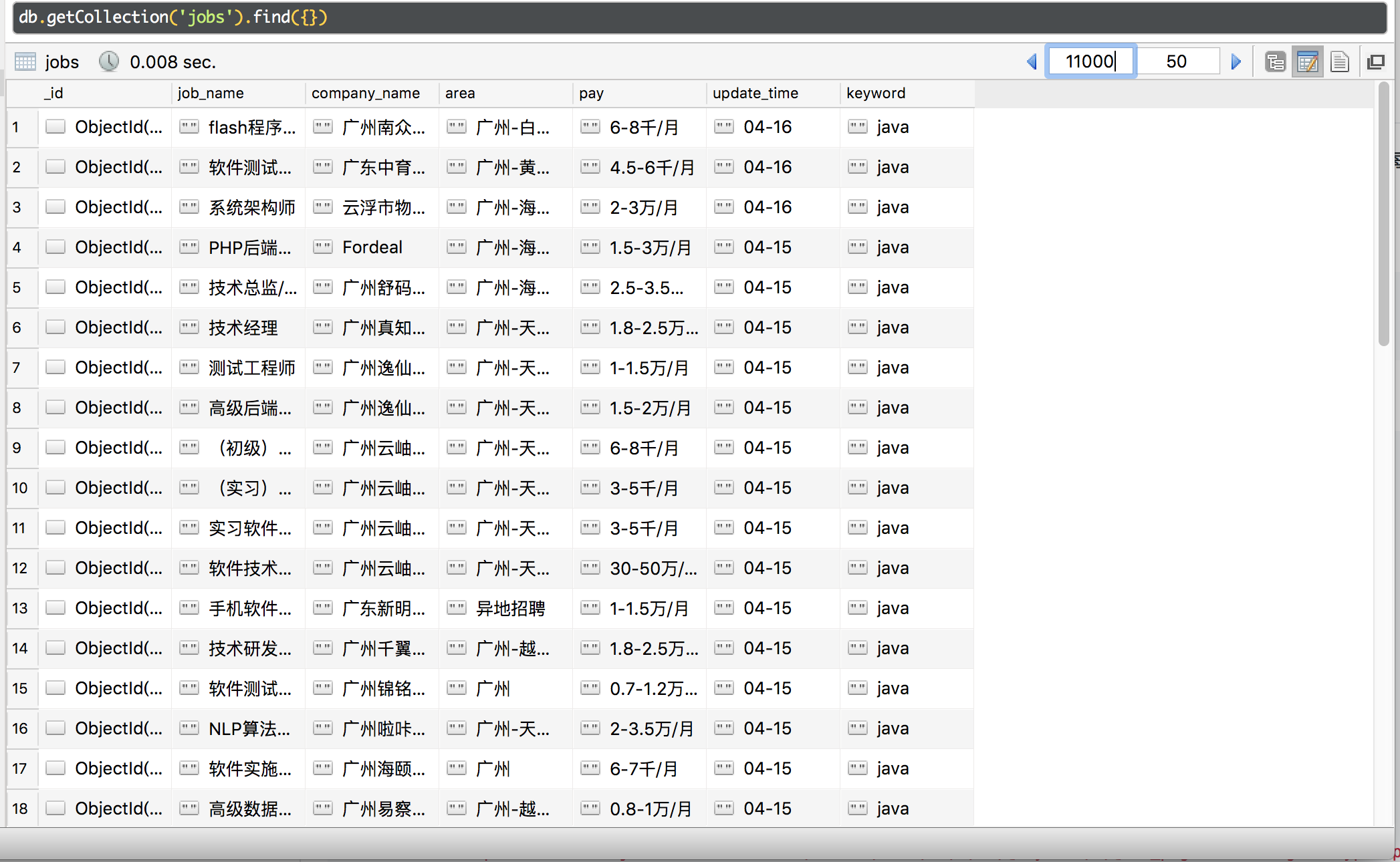
mongodb数据图
使用到的库(第三方库建议使用pip进行安装)
BeautifulSoup4,pymongo,requests,re,time
项目主代码
"""
user:long
"""
import re
import time
from bs4 import BeautifulSoup
from pack.DbUtil import DbUtil
from pack.RequestUtil import RequestUtil
db = DbUtil()
# 要查找的岗位
keywords = ['php', 'java', 'python', 'node.js', 'go', 'hadoop', 'AI', '算法工程师', 'ios', 'android', '区块链', '大数据']
for keyword in keywords:
cur_page = 1
url = 'https://search.51job.com/list/030200,000000,0000,00,9,99,@keyword,2,@cur_page.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=' \
.replace('@keyword', str(keyword)).replace('@cur_page', str(cur_page))
req = RequestUtil()
html_str = req.get(url)
# 从第一页中查找总页数
soup = BeautifulSoup(html_str, 'html.parser') # 推荐使用lxml
the_total_page = soup.select('.p_in .td')[0].string.strip()
the_total_page = int(re.sub(r"\D", "", the_total_page)) # 取数字
print('keyword:', keyword, 'total page: ', the_total_page)
print('start...')
while cur_page <= the_total_page:
"""
循环获取每一页
"""
url = 'https://search.51job.com/list/030200,000000,0000,00,9,99,@keyword,2,@cur_page.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=' \
.replace('@keyword', str(keyword)).replace('@cur_page', str(cur_page))
req = RequestUtil()
html_str = req.get(url)
if html_str:
soup = BeautifulSoup(html_str, 'html.parser')
# print(soup.prettify()) #格式化打印
the_all = soup.select('.dw_table .el')
del the_all[0]
# 读取每一项招聘
dict_data = []
for item in the_all:
job_name = item.find(name='a').string.strip()
company_name = item.select('.t2')[0].find('a').string.strip()
area = item.select('.t3')[0].string.strip()
pay = item.select('.t4')[0].string
update_time = item.select('.t5')[0].string.strip()
dict_data.append(
{'job_name': job_name, 'company_name': company_name, 'area': area, 'pay': pay,
'update_time': update_time, 'keyword': keyword}
)
# 插入mongodb
db.insert(dict_data)
print('keyword:', keyword, 'success page:', cur_page, 'insert count:', len(dict_data))
time.sleep(0.5)
else:
print('keyword:', keyword, 'fail page:', cur_page)
# 页数加1
cur_page += 1
else:
print('keyword:', keyword, 'fetch end...')
else:
print('Mission complete!!!')