Binderverse: integrating Binderhub with Dataverse (using docker+kubernetes) #4714
Comments
|
@aculich For prototyping, |
|
@aculich thanks for opening this issue! @wrathofquan just gave me access to the "Spring 2018 CloudWG: Dataverse + Binderhub" doc at https://docs.google.com/document/d/1ZR9AhhAAqCRmXjFkqAm7UAJlxEUe4ooyOgWOILwOIXw/edit?usp=sharing and I'm having a look around. When you created this issue I shared it at https://groups.google.com/d/msg/dataverse-community/VG6gTMEd_Ps/9walKsGQCQAJ so people could see the mockup of BinderHub operating on a DOI, which is really cool. This is great, exciting stuff. How can the Dataverse team help? You mentioned #4665 and there's been some discussion there. (I mentioned you at #4665 (comment) .) Anything else you need? We could create separate smaller issues about specific tasks such as letting external tools operate at the dataset level. Thanks! |
|
@aculich hi! Any news? I just checked the "Spring 2018 CloudWG: Dataverse + Binderhub" doc above and it looks like there haven't been any changes since my last comment. No pressure, I'm just checking in. At the Dataverse Community Meeting the other week people were definitely still interested in Jupyter notebook integration! |
|
@pdurbin some movement is happening in this form at the moment: whole-tale/whole-tale#35 Please feel free to join in the discussions there, as the work around federation could use movement on several reference implementations to help binderhub evolve in ways that suit multiple repositories, including Dataverse in the mix. See also these two: |
|
@aculich thanks for linking to whole-tale/whole-tale#35 and I'm glad to see @craig-willis created that issue but I don't think I have enough context to contribute to the discussion. That issue links to https://docs.google.com/document/d/16kL6TPMqNgpiZ-H9LLk1bqm3zc3t_lhKRUpGeK-yq8I/edit?usp=sharing and I'm glad to see you added "and Dataverse" as a suggested edit to indicate that the Binder team has expressed interest in integrating with Dataverse. Are you blocked on anything? Do you need anything from the Dataverse team? |
|
@pdurbin we are not blocked and there is not a specific request (yet) from the Dataverse team. Just wanted to reply to you on this issue thread to give you a sense of what's going on. We'll keep you posted and let you know if we have a specific request. |
|
Thanks @aculich for linking -- I wasn't aware of the progress here. @pdurbin I've added a couple of sentences to the document to provide a little more context (maybe). The short is we are trying better align WT with Binder, particularly concerning how to publish and execute these composite research objects (code + data + environment) from remote repositories. WT has been working mainly with DataONE, and it's great to see the effort here. I don't have access yet to the "Spring 2018 CloudWG: Dataverse + Binderhub" document, but I'm curious how Binder repos are published to Dataverse. Do I download a zip of by Github repo and upload to Dataverse? Or is there a better way? |
|
@craig-willis I update the permissions on that document so you should be able to read it and also comment on it, so feel free to comment in the gdoc itself if you have questions or thoughts (and assign the comment to me so I see it). Also mentioning @wrathofquan, our resident Data Lab Librarian at UC Berkeley, to loop him into it since he is the one who spear-headed these efforts along with the two students who did all of the hands-on work. Our focus was primarily on the UX integration, rather than the under-the-hood plumbing for data itself. With a semester-long project where we had only 2hrs/week of the student's time to work on it, we wanted to keep the scope achievable for the time available. The students did a great job helping us advance our thinking in addition to sorting out some concrete implementation details. |
@craig-willis Maybe I'm confused about what a Binder repo even is but my understanding is that @aculich et al. want to add a button called something like "Launch Binder" to the dataset pages in Dataverse. Then the DOI of the dataset is sent to Binder automatically rather than having to enter the DOI manually like in the screenshot above. Below I'm cropping just the part where you enter the DOI in Binder:
I don't know what happens to the Binder repo after it's done executing. I've been thinking of Binder as an exploration tool for data that has already been deposited and published in Dataverse. Currently, the "Explore" button in Dataverse can be a dropdown that launches either Data Explorer or TwoRavens, and Binder would be a third "external tool": http://guides.dataverse.org/en/4.9.2/installation/external-tools.html . For more discussion on Binder some day being an external tool for Dataverse, please see https://groups.google.com/d/msg/dataverse-community/VG6gTMEd_Ps/Xy7jDhVoBwAJ
This is somewhat beside the point but Dataverse is planning to allow code deposit from GitHub (similar to Zenodo) as part of #2739. Again, I hope it doesn't matter how the data got into Dataverse. It would be great if the "Launch Binder" button could be enabled for datasets that were deposited and published long ago. @aculich thanks for tweaking the permissions on that Google doc. I thought it was a good read! |

|
Thanks @aculich, makes perfect sense. @pdurbin I should probably defer to @aculich on this one, but here's my outsider perspective. If you haven't played with BinderHub, it's quite cool and worth a look. Given a well-structured Git repository, they build and run a Docker image based on supported interactive environments (e.g., Jupyter, Rstudio, etc). They have many examples, including: https://github.com/minrk/ligo-binder Just click "Launch in Binder" and you should be taken to an interactive Jupyter session via Binderhub. The repos typically contain code/notebooks + environment (e.g., installed packages) + sometimes data to facilitate reuse and reproducibility. From my understanding, the original focus was on Git repos but there are now several initiatives to integrate with research repositories. A basic use case would be a researcher with an existing Binder-formatted Git repo with code/notebook + environment + data and wants to publish it to Dataverse. Once published a reader can access the Dataverse entry (via DOI) and "Launch in Binder" or plug the DOI into the above search box to have access to a full interactive environment to reproduce some aspect of the work. In this case, it's important to know how the "binder" repository is published to Dataverse (and can be resolved/executed by BinderHub). I expect #2739 is quite useful in this scenario. No doubt there will be ways to launch some baseline Binder environments on historical entries as well, but publishing these sorts of composite research objects (code + data + environment) intended for re-execution in services like Binder is of interest to me for the WT project right now. |
|
@pdurbin In some sense, Binder is a third "external tool" for Dataverse, but a fundamental difference in the way it works from Data Explorer and TwoRavens is that it both gives you a tool for interacting with the data, as well as a full compute environment separate from your laptop— whereas the other two apps are intended to be run in-browser or as an application on a laptop that talks with the Dataverse data repository. The important thing about Binder is that it enables what we call Mobility of Compute and... we hope in the future... Mobility of Data. What we'd like to see is data repository become aware of the Binder Pattern and provide a way of letting users curate their data and software in a way when they deposit it that the repository can then allow an end user of the repository to browse any data and launch a compute environment wherever that is suitable to do so— so, for example, if the Harvard Dataverse were to partner with Harvard's Research Computing group to provide compute resources, then allow people to run directly their compute environments directly on Harvard's infrastucture— and also provide the ability to use a third party infrastructure to run the same environment. If that option were chosen, then it would launch the compute environment at the other third-party location... and then all the data from that collection would be copied to the remote compute environment (e.g. via Globus). So that would allow people to work with much larger datasets than is possible on their laptops. And then another step, which @craig-willis points to in the example above, is that in addition to being able to "launch binder" directly from a data repo like Dataverse itself, we'd also like to be able to drop a DOI into any compute environment that supports the Binder Pattern and it would figure out where the data lives and let the user choose where to run the compute environment— whether that's on the data repo itself if that capability is provided there, or to transfer the data to a third party hosting the compute environment. As far as historical entries— yes, it would be possible to launch a Binder for existing data/code.... however when the code runs, it may not run correctly if the software requirements are not captured.... however, for some environments that use a common set of software packages it could be solved trivially, and for more complex situations we could work something out on a case-by-case basis (especially if the person who wants the data is willing to do some of the sweat & tears labor to get it working and contribute an "software requirements" update back to the repository owner). |
|
@aculich thanks! I'm chatting with @craig-willis at https://gitter.im/jupyterhub/binder?at=5b7ae5fccda86f5fb28091fb if you're interested. I jumped in there to ask if "Binder Pattern" was a thing and it sounds like the idea is to follow https://mybinder.readthedocs.io/en/latest/using.html#preparing-a-repository-for-binder (which @craig-willis linked to already above as a "well-structured Git repository"). @craig-willis and I will talk more at https://wholetale.org/2018/06/26/working-group-workshop.html I'm sure. If others reading this will be there (September 13-14 in Chicago), please let me know! |
|
@aculich Your comments about having Binder figure out where data files are currently available makes me thing that the locality APIs will need to be user facing (at least the read portions). Do you have pointers to what Binder expects those APIs to look like, and what protocols it supports for storage and transfer? |
|
@pdurbin @craig-willis @choldgraf there is (as far as I am aware) no official "Binder Pattern", however what I meant by using that term generically is two things: 1) that people (researchers in particular) with code & data should explicitly declare their dependencies according to the Using Binder docs: https://mybinder.readthedocs.io/en/latest/using.html#preparing-a-repository-for-binder I will continue the conversation with ya'll over on Gitter, but wanted to leave a note here that "Binder Pattern" is just a term that I made up and isn't (yet?) in official usage. |
|
@pameyer at the moment there is no expectation from Binder, in fact, it is entirely ignorant of it! So here we have a chance to define what that ought to be to make Binder aware of the universe of DOIs and related repositories, as well as how to make repositories aware of Binder. |
|
@aculich I would love to setup a meeting to talk more about this. we have a new funded Sloan project to develop a journal replication environment and we should coordinate the interaction with Dataverse. This is something the new Global Dataverse Community Consortium would be interested in too |
|
@aculich in case you aren't aware @jonc1438 is a great person to know because he's been running Dataverse for almost as long as Harvard at UNC ( https://dataverse.unc.edu ), has been a strong advocate for Dataverse for many years, is the primary contact for the Global Dataverse Community Consortium ( https://dataverse.org/blog/global-dataverse-community-consortium-announcement ), and is an awesome guy. @jonc1438 I'd love to hear more about your new project! |
|
@pdurbin indeed, I do know him (We originally met at the 2017 Binder workshop at UC Davis last October) and I absolutely agree that @jonc1438 is an awesome guy... in fact, as you were writing here on github your ears must have been burning, since he and I were on a Zoom call saying the same thing about you! :) Among other things we were discussing Confirmable Reproducible Research (CoRe2) Environment: Linking Tools to Promote Computational Reproducibility (congrats, @jonc1438 !) and how we may continue to align with efforts in the Jupyter/Binderhub ecosystem, with @craig-willis and WholeTale, etc. Looking forward to coordinating with you all to help these tools co-evolve. |
|
I see that @jonc1438 already weighted in on whole-tale/whole-tale#43 but heads up to @aculich and others interested in reproducible research publishing and interoperability that @whole-tale is hosting a meeting on Wednesday October 24th, organized by @craig-willis (thanks!). Details are in that issue. |
|
We had a second meeting today (I'm not sure what to call the group but see whole-tale/whole-tale#50 ... from my perspective these are "computation" meetings but "reproducibility infrastructure" was suggested) and @craig-willis demo'ed https://github.com/craig-willis/dataverse-binder where if you click a link you're taken to https://mybinder.org/v2/gh/craig-willis/dataverse-binder/master?urlpath=%2Fnotebooks%2Fdataverse.ipynb%3FfileId%3D2865473%26siteUrl%3Dhttps%3A%2F%2Fdataverse.harvard.edu to spin up a Jupyter notebook based on data in Harvard Dataverse. Neat! |
|
Thanks, @pdurbin. We can also use this toy example to highlight two different general use cases reflected in the discussion in this issue. The first is the ability to do ad-hoc/exploratory analysis on any data stored in Dataverse. This external tool/Binder example or the similar external tool/WT example gets at that -- they provide a generic Jupyter/Rstudio environment that could be used to do ad-hoc analysis on any dataset stored in Dataverse. The second is the ability to re-run a specific analysis published in Dataverse, such as one of the AJPS exemplars listed in whole-tale/whole-tale#49. From my understanding, one vision of the CoRe2 implementation is to put a Dockerfile in the replication study dataset at the end of the verification process. In this case, something like Binder/WT or related systems could build and run the specific environment created by the researcher to reproduce the study. The initial WT dataverse integration (whole-tale/girder_wholetale#180) addresses the first case. Our next step will be to support the second. If the dataset contains a Dockerfile or other Binder/repo2docker-compatible configuration, we'll not only mount the dataset, but also build the environment to allow you to re-run the analysis. Ideally, the work done in both WT and CoRe2 will contribute to this broader "Binderverse" vision. p.s. -- this also relates to your question to @davclark in the meeting notes about how Gigantum integrates with Dataverse. If I'm understanding, they publish a zipfile of a Github repo. This could easily be done with Binder repos or WT tales as well, but doesn't seem like the ideal approach from the repository perspective. Curious do you hear your thoughts about the approach of publishing a zip that contains code/data/environment description. |
@craig-willis I don't know enough about CoRe2 to comment on what technologies will be used but I'd be remiss if I didn't point out that Code Ocean is highly oriented toward producing a Dockerfile for datasets via their graphical interface. As I mentioned in my brain dump at #5028 (comment) I was able to try this myself during a Code Ocean workshop and I was very pleased that at then end, I was able to download a Dockerfile from Code Ocean rather than an image. That is to say, I'm much more interested in the ability to reproduce the image from a Dockerfile than the image itself. It's smaller and you get the recipe. I guess this relates to your p.s. in the sense that I think small is beautiful. It's seems a bit wasteful of disk space for data repositories to store Ubuntu over and over in the form of Docker images. I don't know. I'll defer to the Dataverse community on what they want. The software is for them, not me. 😄 |
|
@choldgraf did you see jupyterhub/repo2docker#739 by @Xarthisius ?!?! 🎉 🎉 🎉 This the backend support we need on the repo2docker/binder side to eventually add a "Launch Binder" button on datasets in Dataverse, right? I'd love to chat with you about how best to write up Binder as a "external tool" to be listed on a future version of http://guides.dataverse.org/en/4.15.1/installation/external-tools.html#inventory-of-external-tools . Maybe we can chat in https://gitter.im/jupyterhub/binder or http://chat.dataverse.org sometime? Please let me know! Thanks! |
|
very cool! I hadn't seen that (away at SciPy right now so haven't been checking issues etc closely). Know if anybody from the dataverse world is here? |
|
@choldgraf well, from looking at https://www.scipy2019.scipy.org/speaker-directory
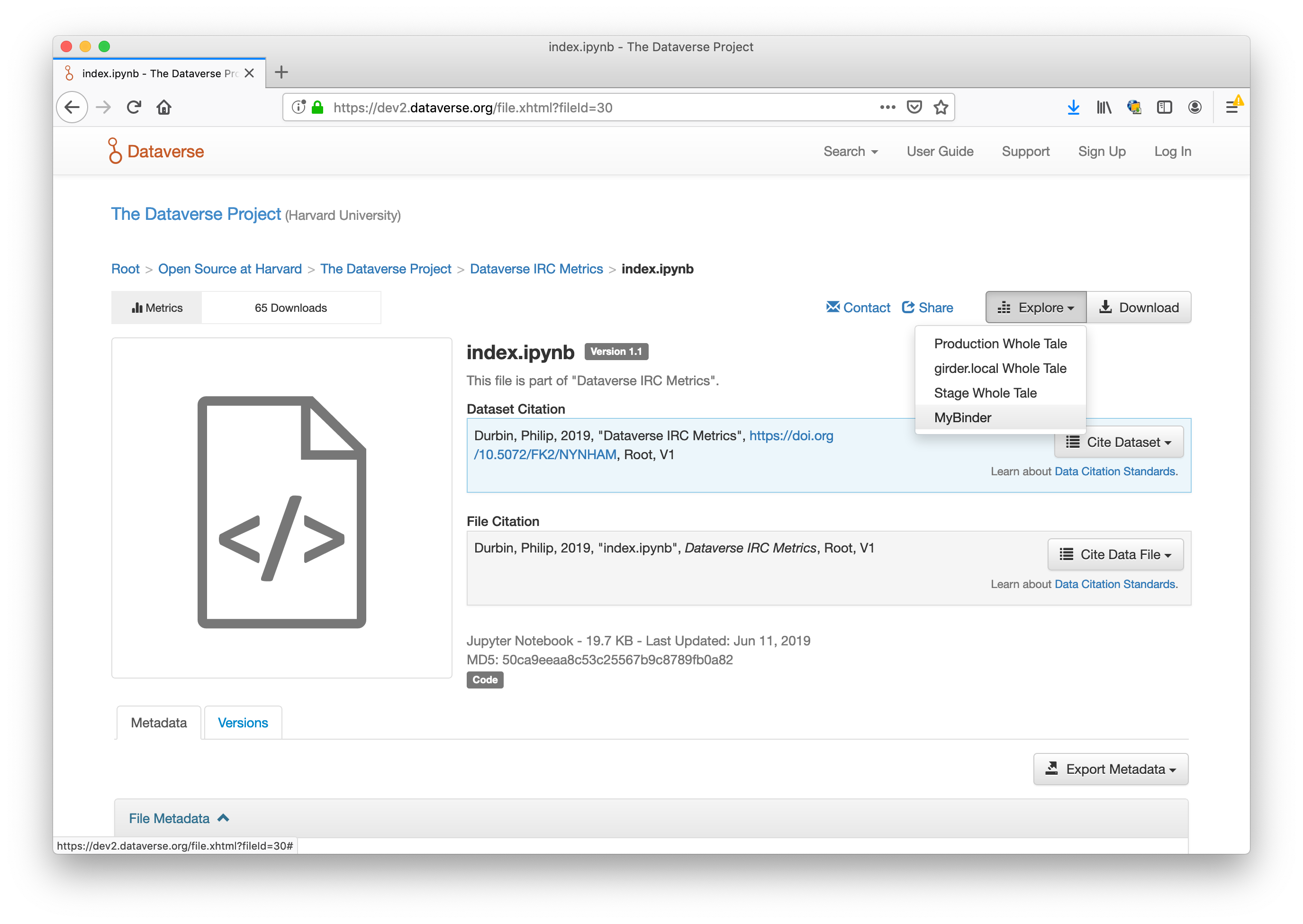
That was a quick scroll through so I may have missed some. While I'm writing I'm going to ask you to help me figure out the best repo to have this conversation about mybinder URLs. Originally I was going to post this at jupyterhub/repo2docker#739 but I'll just throw it in here for now. @Xarthisius thank you so much for kicking off this effort!! 🎉 🎉 🌮 I'd love to chat with the Binder developers about how best to allow users to launch Binder from a Dataverse dataset. Dataverse supports the concept of an "external tool" so that from a file, you can click "Explore" and then the name of the tool to launch that tool. For example, a few weeks ago at the 5th annual Dataverse meeting people were very excited to see me click "Explore" and then "Whole Tale", which launched me into Whole Tale with the Jupyter Notebook and data from the dataset in Dataverse. I transcribed my talk and added screenshots of this demo here: https://scholar.harvard.edu/pdurbin/blog/2019/jupyter-notebooks-and-crazy-ideas-for-dataverse An installation of Dataverse can add a similar button under "Explore" for Binder today like in the screenshot below from a test server:
In this case, Dataverse will open a new tab and send the user to this URL: https://mybinder.org/v2/dataverse/?siteUrl=https://dev2.dataverse.org&datasetId=18&fileId=30 Below I'm including the definition of the external tool that I'm using. It's in JSON format and we call it a "manifest". My questions:
Here's how I loaded the external tool for Binder in my installation of Dataverse:
Here's the contents of Over at http://irclog.iq.harvard.edu/dataverse/2019-07-11#i_100587 @Xarthisius and I seem to be converging on https://github.com/jupyterhub/binderhub being the right place for the conversation above about mybinder.org URLs but I'm also conscious that at https://blog.jupyter.org/binder-with-zenodo-af68ed6648a6 you are directing people to open issues in https://github.com/jupyter/repo2docker . Please advise. 😄 |
|
For URLs we should discuss that in an issue on https://github.com/jupyterhub/binderhub (or even better a PR in that repo that adds a My initial reaction is that we should keep URLs as uniform and "createable by a human" as possible. So something like |
|
@pdurbin I think that tracking conversation about Binder integration would be best-done in the repo2docker repository just because more folks might have a chance to see it there. You can probably copy/paste a bunch of your questions from here and add them there (also fine to open up another issue there if the conversation will be more general than that PR specifically) :-) |
This is potentially something that @whole-tale could help with. We have an endpoint that takes doi and returns you a basic info about it: Pending our addition of Zenodo as a provider, it could serve as a DOI -> ContentProvider translator. |
|
jupyterhub/repo2docker#739 was merged a few hours ago! Thanks, @betatim for merging !!! 🎉 🎉 🎉 Thank you to @Xarthisius for creating the pull request and continuing to iterate on it and to @nuest for helping!!! 🎉 🎉 🎉 For adding Dataverse to the Binder UI, I created jupyterhub/binderhub#900 |
|
wahooo! that's fantastic! |
|
This just in!! The indefatigable @Xarthisius just created a pull request called "Add Dataverse to UI" over at jupyterhub/binderhub#969 🎉 🎉 🎉 |
|
Don't look now but it's actually possible to launch a Binder from a Dataverse DOI if you use the "Zenodo" DOI provider. Lots of screenshots over at jupyterhub/binderhub#969 (comment) 🎉 🚀 @atrisovic is my witness. 😄 In other news, this incredible article just hit my radar: Make code accessible with these cloud services: Container platforms let researchers run each other’s software — and check the results: https://www.nature.com/articles/d41586-019-03366-x Tools mentioned in the article include
|
|
@atrisovic and I had a great chat with the Binder team today. Notes at https://hackmd.io/u2ghJJUCRWK-zRidCFid_Q?view I believe the video will be available at https://www.youtube.com/user/ipythondev/videos |
|
Unfortunately, the video won't be available. See jupyterhub/team-compass#241 . Oh well. The big news is that one can now use https://mybinder.org with Dataverse DOIs! That's because jupyterhub/binderhub#969 was merged yesterday!! 🎉 Lots of likes and retweets at https://twitter.com/philipdurbin/status/1204472858413371392
I just opened pull request #6453 to add Binder to the list of integrations in the Admin Guide. But when is this issue finished? What is the definition of done? Originally @aculich seemed to want an external tool, a button called "Binder" that you can click from a dataset in Dataverse. As we discussed in tech hours yesterday, the Dataverse external tool framework doesn't current support the URLs required by Binder. That is to say, Dataverse always wants to send DOIs in query parameters and Binder wants DOIs (not Handles, by the way) in the path like this: https://mybinder.org/v2/dataverse/10.7910/DVN/TJCLKP/ So maybe the next step is to make the Dataverse external tool framework more flexible about the URLs it can create so that datasets can have a Binder button. |

Binder now supports Dataverse DOIs #4714
@atrisovic just opened #6807 to track improvements to Dataverse's external tool framework to allow for an Explore button for Binder. I'm closing this issue. Thanks, everyone! 🎉 Great feedback on the Binder/Dataverse integration, the Bindervese, continues to come in. Here's a recent tweet from https://twitter.com/Duhem_/status/1245682563617820672
|

Issue #4665 would help us in our work to integrate Dataverse with Binderhub.
Our goal with the integration is to allow anyone browsing datasets in Dataverse to instantly launch a Binderhub-based reproducible compute environment. The Binder technology is a Jupyter project that allows researchers to easily specify software requirements which get automatically built as docker containers spawned into a Kubernetes-based Jupyterhub environment.
Our exploration during Spring 2018 of this new feature/integration included two undergraduate students installing and modifying Dataverse; see this example repo: https://github.com/sean-dooher/binderverse
We would like to be able to either launch Binder from an existing Dataverse instance by adding a button in the Dataverse UI itself. The first iteration hacked the Dataverse code directly to add the button in, and then further discussion on the Dataverse forum about the External Tools Dataset Extension resulted in this final proof-of-concept at the end of the semester.
button in the Dataverse UI itself. The first iteration hacked the Dataverse code directly to add the button in, and then further discussion on the Dataverse forum about the External Tools Dataset Extension resulted in this final proof-of-concept at the end of the semester.
We would also like to enable mybinder.org to accept a DOI as input (instead of a github url) to automatically find a valid Dataverse instance that contains the data and a requirements.txt (and other related binder files):
for this latter DOI functionality we've also explored an integration of Binderhub+Dataverse+OSF (Open Science Framework).
If we resume this work it would be helpful to have an easy to deploy dockerized version of Dataverse to simplify rapid-prototyping initially— and in the long run we'd also like to run it in production on top of Kubernetes.
The text was updated successfully, but these errors were encountered: