Emerging Technologies - Lecturer: Dr Ian McLoughlin - 4th Year (Hons) Software Development
This repository contains solutions to problem sheet 2 for Emerging Technologies 4th year module. These problems relate to the famous MNIST data set.
Solution can be found above in mnist.py
- Click here to download zip of the repository
- Unzip the repository in a directory e.g. Desktop
- Open up a command terminal
- Enter the following to run each python script:
python mnist.py- Go to clone or download (should be on right side of the repository in green)
- Copy the URL.
- Open up git bash and change into a directory where you want to save the git repository.
- Enter git clone followed by the link:
git clone https://github.com/ianburkeixiv/mnist-reader.gitMNIST is a famous dataset that consists of handwritten digits commonly used for training various image processing systems and also used in machine learning. The dataset contains 60,000 training images and 10,000 testing images. Each image is a 28x28 pixel square (784 pixels in total). It is a popular database for people who want to try learning techniques and pattern recognition methods on real-world data while spending minimal efforts on preprocessing and formatting.
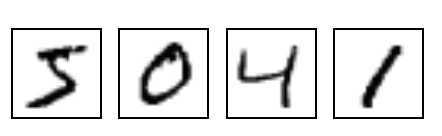
{kind=link}
{kind=link}
{kind=link}
The programming language used for this problem is sheet is Python
Download the image and label files. Have Python decompress and read them byte by byte into appropriate data structures in memory.
Output the third image in the training set to the console. Do this by representing any pixel value less than 128 as a full stop and any other pixel value as a hash symbol.
Use Python to output the image files as PNGs, saving them in a subfolder in your repository. Name the images in the format train-XXXXX-Y.png or test-XXXXX-Y.png where XXXXX is the image number (where it occurs in the data file) and Y is its label. For instance, the five-thousandth training image is labelled 2, so its file name should be train-04999-2.png. Note the images are indexed from 0, so the five-thousandth image is indexed as 4999.