Performance
This page provides information on Kundera's performance while performing read/ write operations on different databases supported by it.
Kundera's performance was benchmarked against different native libraries it is based upon. Yahoo!'s YCSB Framework was used for measuring throughput and latency.
Hardware used:
- Processor: MD Athlon(tm) 64 X2 Dual Core Processor 4000+
- OS: CentOS 6.3
- RAM: 4GB
Source code is available at: https://github.com/impetus-opensource/kundera-benchmarks
Below sections summarize performance run results for different databases:
Workload: 1 million
No of threads: 30
Note: Kundera uses connection pool which gives slight benefit over raw thrift APIs with multiple threads (see Image 1).
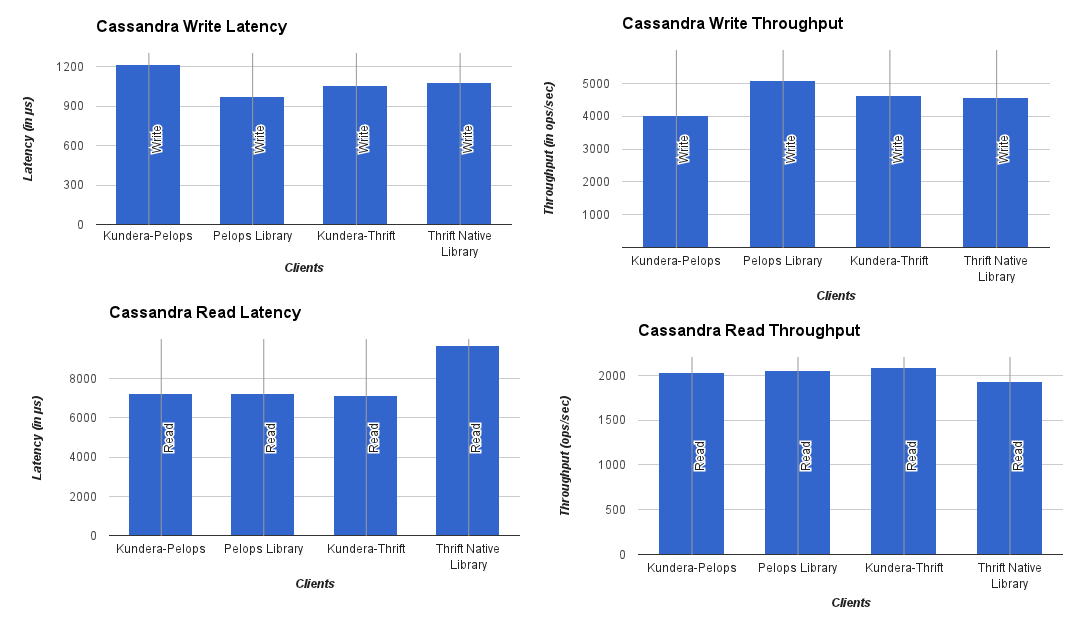
Workload: 1 million
No of threads: 30
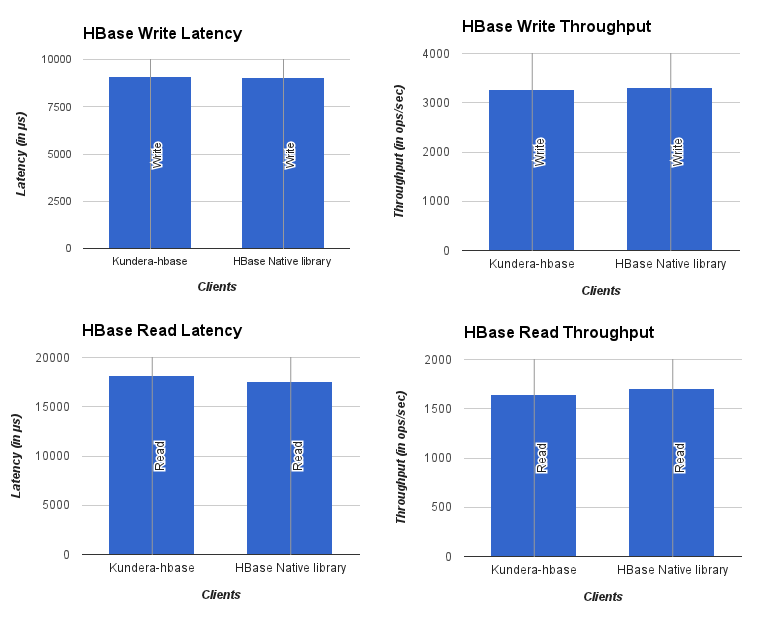
Workload: 1 million
No of threads: 5
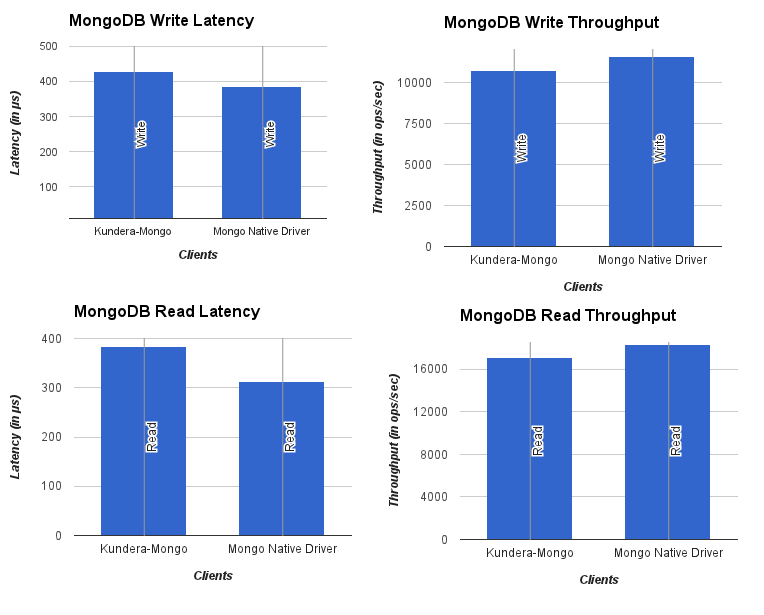
Workload: 1 million
No of threads: 20
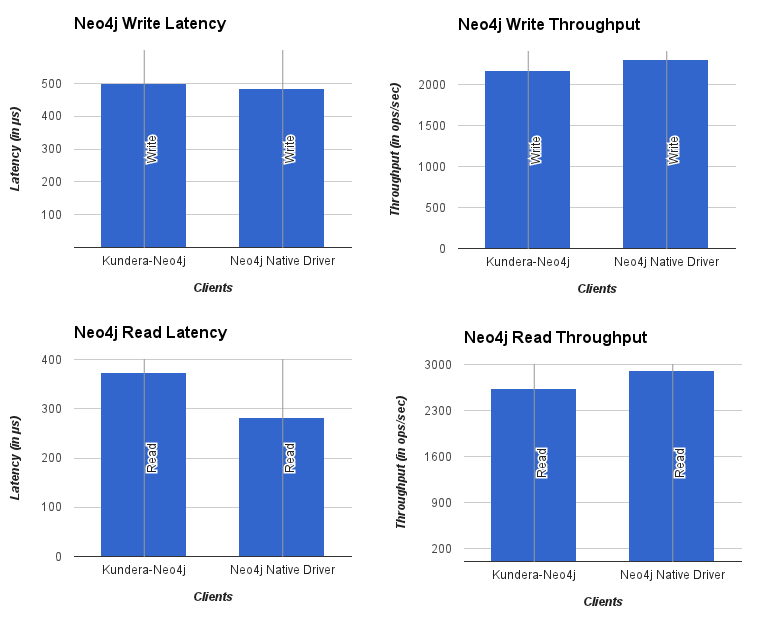
Workload: 1 million
No of threads: 5
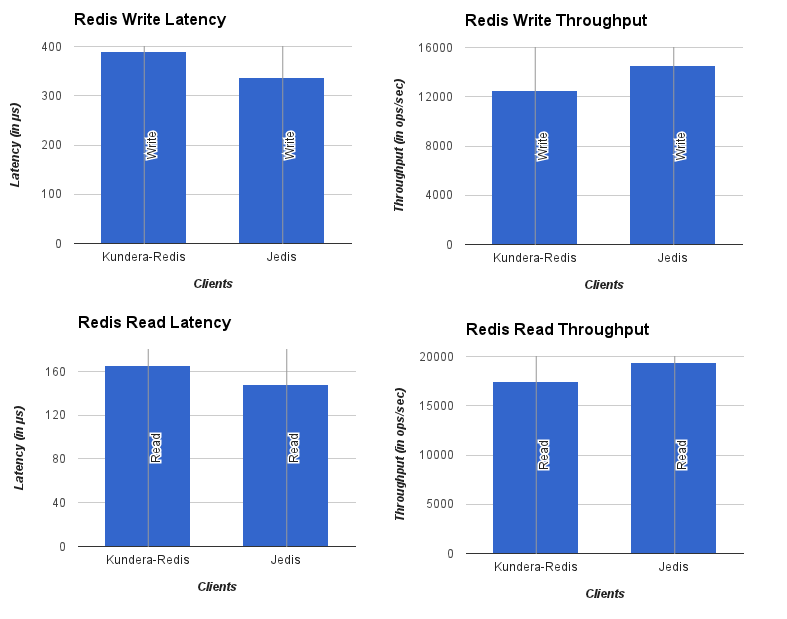
Kundera puts a slight overhead against native libraries it uses. A quick glance at charts shown above would reveal that Kundera adds more latency to operations, and results in lower throughput as compared to its native library counterpart. These overheads are small and a good tradeoff if we look at kind of key services it provides, namely: Ease of use, persistence cache management, transaction handling, secondary indexes, polyglot persistence among others.