This module processes a single CSV file that contains the MODS metadata, file names for binary data files, and related information required to create Islandora/Fedora object. Each row represents one object.
-Currently the module ingests only objects composed of one binary data file. It does not ingest objects such as two-image postcards, books, and so on.
-All bugs, feature requests and improvement suggestions should be submitted as an Issue on the ICG github repo (https://github.com/Islandora-Collaboration-Group/icg_csv_import).-
This module requires the following:
Tuque is expected to be in one of two paths:
- sites/all/libraries/tuque (libraries directory may need to be created)
- islandora_folder/libraries/tuque
The ICG_Hooks module is optional. However, if you do not provide your own hooks the ICG_Hooks module will provide simple versions of the following functions:
- icg_hooks_validate_csv_data($header, $data)
- icg_hooks_validate_csv_header($xpaths)
- icg_hooks_fetch_OBJ($path, $credentials)
See icg_csv_import.api.php for additional details.
Install this module as any other Islandora Drupal module in sites/all/modules.
There is no Drupal configuration menu for this module.
The input data file, referred to here as a CSV file, may actually employ any reasonable field separator. Commas are most often used, hence the term comma-separated-values or CSV, but other delimiters like tabs or semi-colons may be used.
'Pipe' or vertical bar delimiters are used to separate multiple values within fields, so pipes should NOT be used to delimit the fields themselves. Values should be enclosed in quotation marks (double quotes, not single) when possible.
"Smith, John|Jones, William"
For sample CSV files see the "examples" directory.
The batch process used to import CSV data is file-driven, with most of the necessary input stored directly in the CSV data file. [A separate module is being developed that will provides a GUI to assist with building a suitably structured CSV file.]
As indicated above, this module relies on a suitably structured CSV file to drive its batch processing, but the structure of that file can be relatively flexible. A small sample of CSV data from a fossils collection in the Grinnell College Geology Collection is used, below, to illustrate features of this CSV file structure. The samples here are annotated screen grabs of the data as it appears in Excel, but any means of editing/preparing CSV data may be employed.
A good example of a CSV file can be found in Google Sheets at https://docs.google.com/spreadsheets/d/159ry2KDKYLHssGjPi3ypNtOy6IN6cgvNLg1O2TsFuTI/edit?usp=sharing. This 'template' also includes a bit of documenation describing the process and best practices.
The initial/raw CSV data for our example (before we add the row of MODS XPaths) looks like this in Excel:

In the preceeding image, the row of data highlighted in blue contains CSV 'headers', or descriptions, while all other rows contain data to be imported. Note that some cells are empty and some cells contain commas within. Both empty cells and embedded commas are permitted, but if commas are present in any data field, care should be taken to save the file with tab or other non-comma delimiters. Or, if data is exported in a true CSV file, care should be taken to ensure that all values are enclosed in double quotes.
It's good practice to introduce an additional column into your CSV data containing row numbers as illustrated below to ensure you can restore the original order if necessary. The header, "# Import Index" in this colunn is also significant because it begins with a hashtag (or pound) symbol. It is the sign of a comment.

A pipe, the vertical bar character (|), is used to separate multiple values within a single field. For example, the following sample of MODS metadata contains multiple "alternative" titles, and this kind of construct is easy to import.
<mods>
<titleInfo type='alternative'>
<title>Grinnell College</title>
<title>Rand Gymnasium</title>
<title>women's gymnasium</title>
<title>men's gymnasium</title>
</titleInfo>
</mods>
The XPath and corresponding data, with pipes, used to import this is shown below.
XPath -> /mods/titleInfo[@type='alternative']/title
Data -> Grinnell College|Rand Gymnasium|women's gymnasium|men's gymnasium
You can include an unlimited number of pipes in any single field.
The hashtag (#) can be used to specify a comment, and two rules govern them:
- A hashtag as the first character in any value/cell identifies that value as a comment. A hashtag ion any other character position is simply interpreted as part of the data.
- A hashtag as the first character of the first cell in a row identifies the entire row as a comment.
Comments in the CSV data are read and recorded in an output file during processing, but they are otherwise ignored.
In our example, the introduction of the "# Import Index" column, and the hashtag as the first character in the first cell of the headers row effectively renders all of the header cells as comments. This is as it should be, because we don't want the system to import the headers!
- Use Single Quotes Around Attributes and NO Slashes - Attributes within XPaths, like the "provenance" clause in /mods/note[@type='provenance'] should generally be enclosed in single quotes as shown, not double. Attribute values with embedded punctuation characters, especially slashes, like "/mods/note[@type='citation/reference']", should be avoided whenever possible.
You may add XML attributes to the values if those attributes are allowed in the MODS schema. Add the attribute after the value in this way:
If you declare an attribute in the column header, that attribute applies to all values in the column and you don't have to declare it in each cell value.
| /mods/genre[@authority='marcgenre'] |
|---|
| correspondence |
| photograph |
If you want to override that default attribute you may do so if the attribute is attached to the last element in the XPath:
| /mods/genre[@authority='marcgenre'] |
|---|
| correspondence[@authority='aat'] |
| photograph |
If the attribute you are putting in the column header is not an attribute of the last element, you cannot override it.
| /mods/name[@type='personal']/namePart |
|---|
| Smith, John |
Attributes introduced in the data (values) may have multiple attributes but they must be separated by 'and' operators. For example:
| /mods/name[@type='personal']/namePart[@type='given'] |
|---|
| Mark[@type='given' and @displayLabel='First Name'] |
- Multiple values separated by a pipe may also include attributes. For example:
| /mods/name[@type='personal']/namePart[@typee='family'] |
|---|
| Mark[@type='given'] and @displayLabel='First Name'] | McFate[@displayLabel='Family Name'] |
The import process performed by this module is driven by simple XPath 1.0 statements and Keys or reserved keywords. These XPath statements and Keys must appear in the first row of the CSV file as shown in the image below.

The first row, highlighted in blue in the above image, contains a set of XPath statments and one Key, or keyword.
In the first column, the header has the XPath "/mods/note[@displayLabel='Import Index']". This XPath statement directs the module to take the data from the column below it and put it in a MODS XML file with the following structure.
<mods>
<note displayLabel='Import Index'>1</note>
</mods>
The second column in this example contains the Key or keyword "OBJ". Keys are discussed in the next section of this document.
Each of the remaining columns in our example spreadsheet contains an XPath statement and each row represents one MODS file. The first row of data in the example spreadsheet produces the following MODS structure:
<mods>
<note displayLabel='Import Index'>1</note>
<identifier type='local'>EM-07-01</identifier>
<titleInfo><title>Neuropteris hirsuta</title></titleInfo>
<subject>
<temporal>Pensylvanian, Upper Carboniferous Francis Creek Shale</temporal>
<geographic>Mazon Creek, Grundy Co., Ill., Coal Measures</geographic>
</subject>
</mods>
The XPath 1.0 specification includes many useful tools, but the CSV Import module is restricted to using very simple XPath statements as outlined in the following rules.
-
Multiple static attributes using 'and' syntax - Attributes, like type='local' in the identifier column of our example, may be concatenated using [@first='one' and @second='two' and @third='three'] syntax. Under this rule the following XPaths are valid:
- /mods/titleInfo/title
- /mods/name/namePart[@type='given']
- /mods/name[@type='personal']/namePart[@type='given']
- /mods/name[@type='personal' and @displayLabel='Main author']
-
Elements can have Predicates, or Indicies - It is not uncommon in MODS files to use the same element more than once. When this happens, as when there are, say, three <name> elements in one MODS file, we can keep them separate by referencing them by "predicates" consisting of the element name and a number called its "index": name[1] and name[2].
<mods> <name type='personal'> <namePart>Doe, John</namePart> <role> <roleTerm type='text'>Gentleman</roleTerm> </role> </name> <name type='personal'> <namePart>Doe, Jane</namePart> <role> <roleTerm type='text'>Lady</roleTerm> </role> </name> <name type='corporate'> <namePart>Widget Corp.</namePart> <role> <roleTerm type='text'>Sponsor</roleTerm> </role> </name> </mods>The XPaths and corresponding data (after the arrow -->) look like this:
/mods/name[1][@type='personal'] /mods/name[1]/namePart --> Doe, John /mods/name[1]/role/roleTerm[@type='text'] --> Gentleman /mods/name[2][@type='personal'] /mods/name[2]/namePart --> Doe, Jane /mods/name[2]/role/roleTerm[@type='text'] --> Lady /mods/name[3][@type='corporate'] /mods/name[3]/namePart --> Widget Corp. /mods/name[3]/role/roleTerm[@type='text'] --> SponsorIn this example, the predicates/indices [1], [2], and [3] are needed because there are three distinct name elements here, and the indices ensure that the corresponding role elements are assigned to the correct name. Predicates always begin with the numeral [1], never [0]. A predicate should always preceed the attribute (if one is present) attached to an element. A predicate is declared when it is first encountered on an element, and predicates must always be 'declared' in proper numeric order, but may be referenced in any order. For example, the following is a valid set of elements with predicates:
/mods/name[1], /mods/name[2], /mods/name[3], /mods/name[2]/role, /mods/name[1]/roleThis is a valid sequnce of XPaths because name[1] is declared before name[2], which is declared before name[3]. /mods/name[2]/role appears before /mods/name[1]/role but this is permitted since these are not declarations of the predicates, they are referenes to predicates which have already been declared.
An invalid sequence of XPaths might look like this:
/mods/name[1], /mods/name[3]/role, /mods/name[2]/roleNote that in the line above the declaration of name[3] appears before the declaration of name[2] and this may create errors in the imported data.
-
Complex XPaths are NOT Permitted - As mentioned earlier, the XPath specification, even in version 1.0, provides numerous functions and constructs to perform complex node selection. But CSV Import uses XPaths to build data, not to select it, so things like XPath functions and complex structures are not supported.
Keys, or keywords, like OBJ in the second column of our example, are always expressed in uppercase. Each Key triggers specific behaviors in the CSV Import module. For example, the OBJ keyword informs the system to read a filename from the corresponding data, cell to download the file and saved it with a datastream ID of OBJ.
These are the Keys used and their corresponding behaviors.
- OBJ - The filename, or complete network path, to an object's OBJ (content) datastream.
- OBJ_PREFIX - A prefix, typically the network path to a directory containing the files named in an OBJ column.
- CMODEL - The Islandora content model of the imported object. Examples may include "islandora:sp_basic_image", "islandora:compoundCModel", etc.
- LABEL - The object label or title.
- MIME - The MIME-type of the object (OBJ). The default is 'image/jpeg'.
This section provides additional screen grabs from our sample data set. Each image depicts the same data, but with different highlighted features.
The following figure shows the use of OBJ_PREFIX and CMODEL keys. The values in the OBJ_PREFIX field need to be valid network directory paths.

The next figure shows XPaths with predicates, highlighted in blue.

The data highlighted below are 'constants'; the same value appears in every row within a particular column.

This data was not part of the original data set, it was added by the cataloger using a special 'constants' CSV file. That file, depicted in the image below, contains only an XPaths/Keys header row, and a single row of data.

During batch processing, the module appends the constant file's XPath/Key cells to the CSV file's XPath/Key headers, and subsequently appends a copy of the single line of constants to each line of CSV data during processing.
As mentioned earlier in this document, CSV Import provides the ability to download one content file per imported object. The content can be an image, a PDF document, an audio recording, or any other content form supported by an accompanying Islandora content model. Specification of the file's path and file name can be provided in OBJ_PREFIX and OBJ key columns, respectively. The corresponding specification of an object's content model can be provided in a CMODEL key column.
OBJ content files are imported using a Drupal 'hook' function named hook_fetch_OBJ as documented in this module's icg_csv_import.api.php file.
Your hook_fetch_OBJ function will only be called if all three of the following input parameters (see the CSV Import User Interface section of this document) are provided:
- a complete and valid path to the content file,
- a valid username with permissions to read the content file, and
- a corresponding, valid password to permit read access to the content path and file name.
The module will concatenate the OBJ_PREFIX and OBJ key fields together, with NO additional separator, and pass the concatenated result to your hook_fetch_OBJ function.
Once an object has been successfully created, or updated, from a single line of CSV data, the module will perform the usual sequence of post-ingest actions:
- The islandora_add_object function is invoked. At a minimum, this will generate a new, or updated, DC daastream from the object's MODS datastream.
- The module will regenerate all derivative datastreams as specified by the object's content model (CMODEL) with a call to the islandora_run_derivatives function.
- The module invokes any hook_create_object_post_ops defined by the user. See icg_csv_import.api.php for details.
The CSV Import process is primarily intended to ingest new objects into existing Islandora collections, but it also produces an output file to document your import history, and to provide a mechanism for easily updating your imported objects.
The following shows a portion of the output from import of our example data.

The CSV Import module adds a column at the beginning of each row. The first cell in this column is a time-stamp recording the date and time when the import was initiated. The values in the cells below are the PIDs of the objects generated during the import process. The hashtags in this column render each line in this output file as a comment.
The output file keeps the same field separator found in the input file, so if the input file was a true CSV file, with comma field delimiters and quotation marks around values, then a true CSV file is output. If a tab-delimited file is specified as input, a corresponding tab-delimited file is created as output.
The output file retains all comments, including comment lines (where the first character in the first column is a hashtag), from the input file without modification.
The output file also reatins the input CSV headers and data, as well as the constants headers and data.
It is possible to edit a CSV output file and easily re-import the data with subtle or even sweeping changes. When data is re-imported there must be a valid time-stamp at the top of the first column, and each subsequent cell in that column must contain one of the following:
- a comment (first character in the cell is a hashtag),
- a valid object PID, or
- nothing - the cell must be completely empty.
When a comment is encountered in the first column, the entire line is treated as a comment (remember our comment/hashtag rules!).
When a valid object PID is encountered in the first column, the corresponding line of data replaces the MODS, and possibly the OBJ, datastream(s) of the identified object.
When an empty cell is encountered in the first column, the corresponding line of data is processed to define a new object.
The image below, with modified cells in yellow, illustrates a case for re-import that you might encounter.

In our fossils sample we discovered, after an initial import, that some objects should have been ingested as compound parents with no content OBJ of their own. In our example, objects grinnell:17037 and grinnell:17061 were intended to be one object illustrating two similar fossils. These objects were imported without a corresponding 'parent' compound object to attach themselves to, so we performed the following series of edits in the output CSV file to introduce necessary changes.
- We first duplicated the row of data that created grinnell:17037, and working in that duplicate row, we removed the '# grinnell:17037' comment in the first column, and changed the row's CMODEL from islandora:sp_basic_image to islandora:compoundCModel.
These changes will effectively introduce a new object into the collection (since the first column here is empty), and that new object will have an islandora:compoundCModel content model. This new object will eventually become the 'parent' of grinnell:17037 and grinnell:17061.
- In the rows immediately below the duplicate, we removed the hashtag/comment marker from each of the PIDs, grinnell:17037 and grinnell:17061; changed the Import Index values in the second column from 2 and 3, to 2.01 and 2.02; and blanked out the values in the last two columns of data.
These changes will cause the system to replace (since there are valid PIDS in the first column) the MODS data of the two existing objects with new MODS records having new Import Index values, and no named contributor.
- In the XPath/Key header row we added hashtags to both the OBJ and OBJ_PREFIX keys.
This change effectively removes the OBJ and OBJ_PREFIX keys from the import. Since these keys no longer exist (they have been turned into comments) there is no way for the system to identify a corresponding content object file, so no download of content is initiated. Consequently, the new compound object will have NO OBJ datastream, and the two updated objects will have new MODS datastreams, but their existing OBJ datastreams will remain unchanged.
The output from our re-import operation will be another complete CSV file, with an updated time-stamp, and comment PID entries in place of the three cells in column one that were updated. If additional updates are needed this output CSV file can be edited and re-imported.
Rinse and repeat, as often as you like. The possibilities are endless. Powerful stuff indeed!
CSV import processing is driven by a set of ten (10) Drupal variables. The variables and their default values are:
| Variable Name | Required? | Default Value |
|---|---|---|
| icg_csv_import_parent_pid | Yes | None |
| icg_csv_import_csv_file_uri | Yes | None |
| icg_csv_import_constants_file_uri | No | None |
| icg_csv_import_username | No | None |
| icg_csv_import_password | No | None |
| icg_csv_import_namespace | Yes | islandora |
| icg_csv_import_delimiter | Yes | tab |
| icg_csv_import_mods-to-dc | No | path/to/icg_csv_import/mods-to-dc.xsl |
| icg_csv_import_inactive | Yes | TRUE |
| icg_csv_import_label_xpath | Yes | /mods/titleInfo/title |
Note that there are two "Required" variables that have NO default. You must provide values for these variables!
A simple sequence of Drush commands, like the following, can be used to define necessary variables before launching an import.
| Sample Commands |
|---|
| cd /var/www/drupal/sites/default |
| drush vset icg_csv_import_csv_file_uri '/vagrant/shared/AttributeTest01 - Data.tsv' |
| drush vset icg_csv_import_constants_file_uri '/vagrant/shared/AttributeTest01 - Constants.tsv' |
| drush vset icg_csv_import_parent_pid 'islandora:sp_large_image_collection' |
| drush vset icg_csv_import_username 'ICG' |
| drush vset icg_csv_import_password 'anything' |
| drush vset icg_csv_import_namespace 'islandora' |
| drush vset icg_csv_import_delimiter 'tab' |
| drush vset icg_csv_import_mods-to-dc 'sites/all/modules/icg_csv_import/mods-to-dc.xsl' |
| drush vset icg_csv_import_inactive TRUE |
| drush vset icg_csv_import_label_xpath '/mods/titleInfo/title' |
Once the module is installed and the command variables have been defined, with administration rights and a suitably structured CSV file you can launch an import by navigating to the target collection that will contain the imported, or updated, objects, and click the Manage tab like the one shown in our Geology Collection example below.
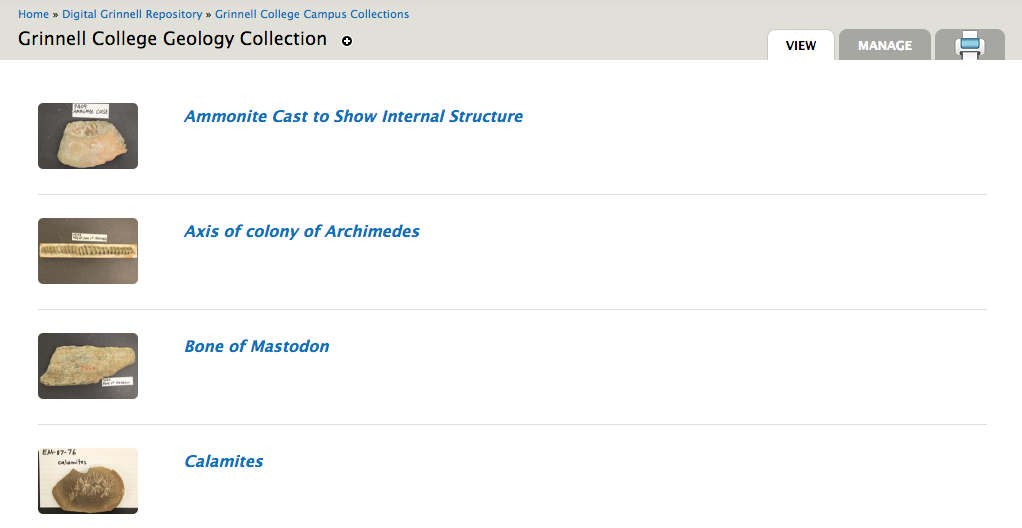
A Manage screen similar to the one shown below should open. The path to this screen is generally of the form: http://your.server.here/islandora/object/collection:pid/manage.

In the Manage screen you should find a CSV Import tab or button. Click that tab, or button, to begin the import process by opening the CSV Import user interface.
When invoked, the CSV Import module should present you with a simple 'review' form like the one shown below.
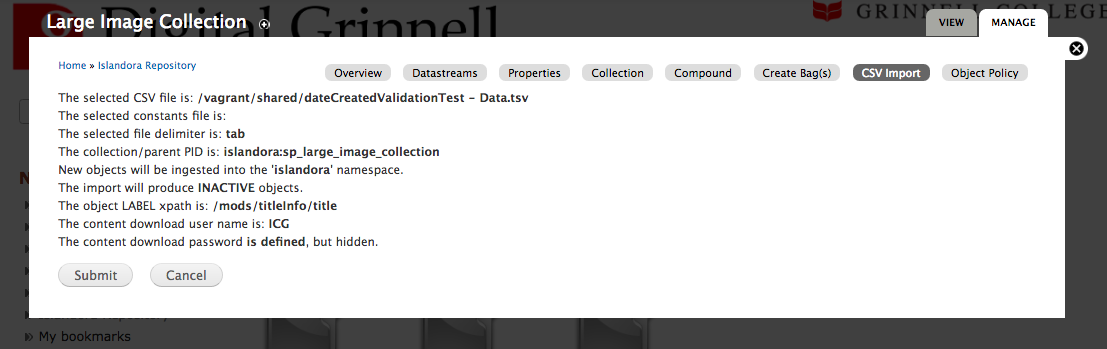
Select 'Submit' to accept the input variable values and proceed, or select 'Cancel' to return to the previous page.
The user interface consists of two, or in some cases three, input data forms or pages.
The first form/page prompts the user for a number of required and optional parameters. Becuase the input form is rather large, the example below is presented in two parts. The user may have to scroll to see the entire form.


This first page CSV Import form prompts for:
- The file to import (the CSV file),
- An optional CSV constants file to import (another CSV file),
- A checkbox to indicate if the CSV file already contains XPaths or not, or
- The destination content model (all items need to use the same content model), and
- An Islandora XML input form corresponding to the selected destination content model.
The first form/page also solicits input for:
- The namespace that new objects will be imported into (all items need to use the same namespace),
- The CSV's field delimiter character (leave this blank to accept the default of tab-delimited fields),
- A checkbox option to ingest new objects with a status of 'Inactive', and
- Content file download credentials in the form of a username and corresponding password.
The second CSV Import form/page changes based on the status of the first checkbox control.
- If XPaths are already present in the specified CSV file, the second screen will simply ask for confirmation to proceed.
- If XPaths are not in the CSV file, the second screen will provide for field-by-field mapping of the CSV file headers to MODS elements, as determined by the destination content model and selected Islandora XML input form.
Having problems or solved a problem? Check out the Islandora google groups for a solution.
Current maintainers:
If you would like to contribute to this module, please check out CONTRIBUTING.md. In addition, we have helpful Documentation for Developers info, as well as our Developers section on the Islandora.ca site.