XADD Chunked Array Queue #230
Conversation
|
@nitsanw It is a just a lil' more then a POC but I will continue to improve it if the logic seems reasonable and sound to you, so please take a look to the logic 👍
The first benchmarks shows a better scaling then the other multi-producer queues and the code/logic/layout is not optimized at all 👍 |
|
@eolivelli |
59519c0
to
714a8fc
Compare
|
I'm working on an idea to recycle the consumed buffers and make it GC-free in the same way MpscChunkedArrayQueue is 👍 |
41dfa8e
to
a27ecf0
Compare
|
@eolivelli @nitsanw I've played a lil' more with this on the weekend, making possible to recycle chunks, adding tests and paddings + refine the implementation in order to use Unsafe. |
1ee2c31
to
c72f06b
Compare
|
I think that both poll/peek and fill could be improved a lot; single threaded fill benchs are not good as I was expecting! |
jctools-core/src/main/java/org/jctools/queues/MpscProgressiveChunkedQueue.java
Outdated
Show resolved
Hide resolved
| consumerBuffer = next; | ||
| this.consumerBuffer = consumerBuffer; | ||
| } | ||
| E e = consumerBuffer.lvElement(consumerOffset); |
There was a problem hiding this comment.
The following code can be re-arranged as elsewhere for single consumer code
There was a problem hiding this comment.
Do you mean by grouping everything under a single method or just by grouping the "slow" path?
assert !firstElementOfNewChunk;
if (lvProducerIndex() == consumerIndex)
{
return null;
}
e = spinForElement(consumerBuffer, consumerOffset);
consumerBuffer.spElement(consumerOffset, null);
soConsumerIndex(consumerIndex + 1);
return e;
jctools-core/src/main/java/org/jctools/queues/MpscProgressiveChunkedQueue.java
Outdated
Show resolved
Hide resolved
jctools-core/src/main/java/org/jctools/queues/MpscProgressiveChunkedQueue.java
Outdated
Show resolved
Hide resolved
|
Great stuff! This makes for an interesting tradeoff, though the progress is still blocked if the new buffer allocator is interrupted (so this is still blocking producers on new buffer). The progress guarantees are the same overall, so this is not more "progressive" IMO. You can make it more progressive if the first to discover a missing chunk allocates it, rather than the first in chunk, but this is not simple... |
Eheh, smart observation: that's why I've added the recycling of the buffer; to speedup the process to publish a new chunk to be used by the other producers awaiting it
You're right, but I wasn't able to find a better name for this :P
Nope, but it is an interesting idea! Not sure I will be able to get it into this PR |
|
@nitsanw I've addressed the most of the changes I've understood: let me know if it seems better and...probably will need some help to improve fill/drain bud 👍 |
2564497
to
abec981
Compare
|
@nitsanw I've added some significant changes to the producerBuffer publication/initialization logic due to the complication of recycling instances, but I think to have addressed any weird corner cases due to long stalls of producer threads. Please let me know if the comments are clear enough: I wasn't expecting recycling logic to affect the offer logic that much! |
e29c6e1
to
f4b7931
Compare
|
I'm just too curious to see how it performs on a machine with many cores: @nitsanw there is any chance to test this one on such hw? |
|
@nitsanw I've addressed in a separate commit the challenge:
Now it should be more progressive: any offer that found any missing chunk (including previous ones) will try to fill the gap, but given that producer buffer publication (partial) ordering should be preserved I've used a CAS on a separate From perf pov I can't see any evident benefit in this new solution, but maybe I'm not benchmarking it properly or the implementation is just not enough "progressive". |
fbfafb0
to
c6a4da9
Compare
|
@eolivelli @felixbarny did you have chances to try it or check the logic guys? |
|
Sorry, but I didn't try it out yet. For my use case, it's important that the size of the queue is limited. This one seems to be unlimited? Ideally, I'd also need a XADD-based MPMC queue.
|
|
I have already implemented a bounded mpsc xadd queue but is prone to be blocked forever in very special cases ie is in the experimental branch of JCTools for that reason and is inspired by the Aeron log buffer algorithm. This q could be "easily" turn into mpmc (but without using XADD on consumer side obviously) and I could provide a weakOffer method that could just weakly back-pressure a producer by looking the current distance of consumers, reducing the chance to allocate a new chunks. |
|
@kay I have always referenced Nitsan for the review of this PR, but please, feel free to validate the code as well eh 👍 |
|
@nitsanw I've pushed a squashed commit addressing a null check, but the logic should be the same. |
|
I've decided to squash the commits into one, given that the "more progressive" version is preferreable to the original one,@nitsanw let me know if I'm missing other parts to clean-up or any improvement you see on the algorithm/implementation. |
|
@nitsanw I've tried a scaling benchmark with increasing numbers of producers, but I'm not getting what I was expecting: It is clear that the Universal Scalability Law is clearly an extension of Amdahl Law, but Amdhal himself is a personified extension of it as well; and he seems to go beyond that too (!!!). |

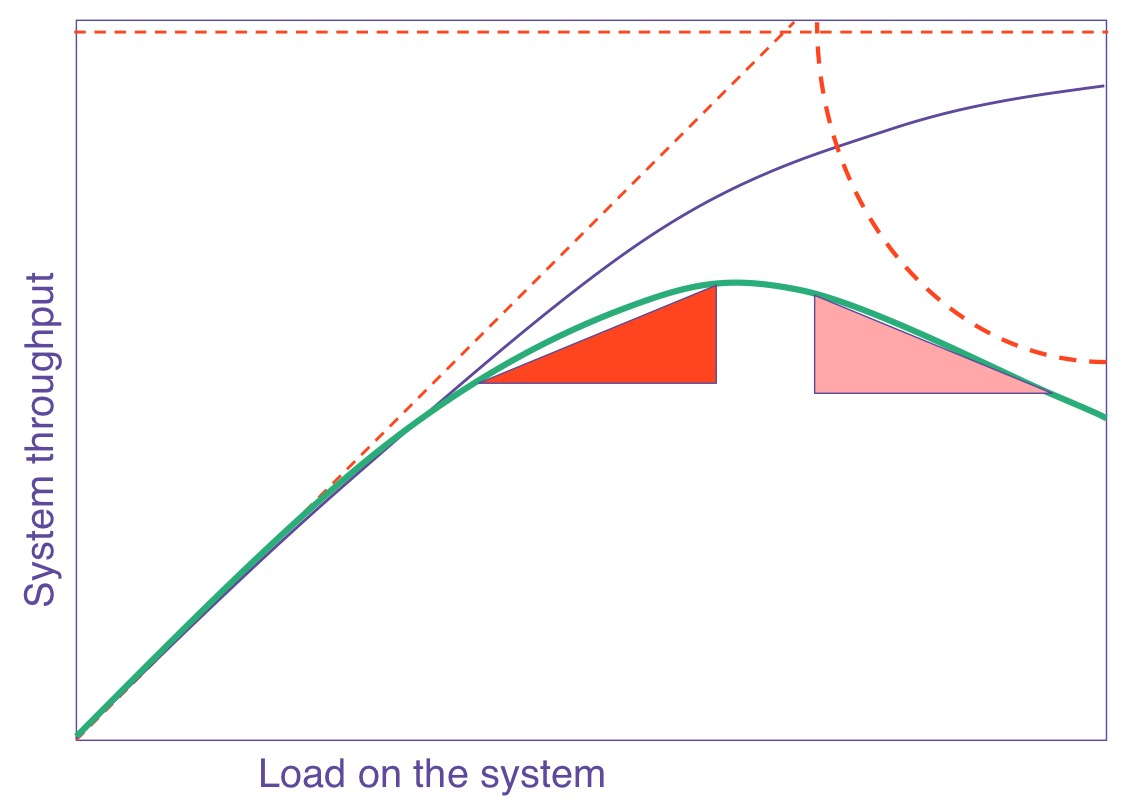


|
I'll review further before next release, but generally it looks good :-) |
It is a chunked array q designed to scale with the number of producers.