Merged master branch from apache #1
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…eURI to make the way to get URI simple ### What changes were proposed in this pull request? This PR proposes to replace Hadoop's `Path` with `Utils.resolveURI` to make the way to get URI simple in `SparkContext`. ### Why are the changes needed? Keep the code simple. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32164 from sarutak/followup-SPARK-34225. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? Normal function parameters should not support alias, hive not support too 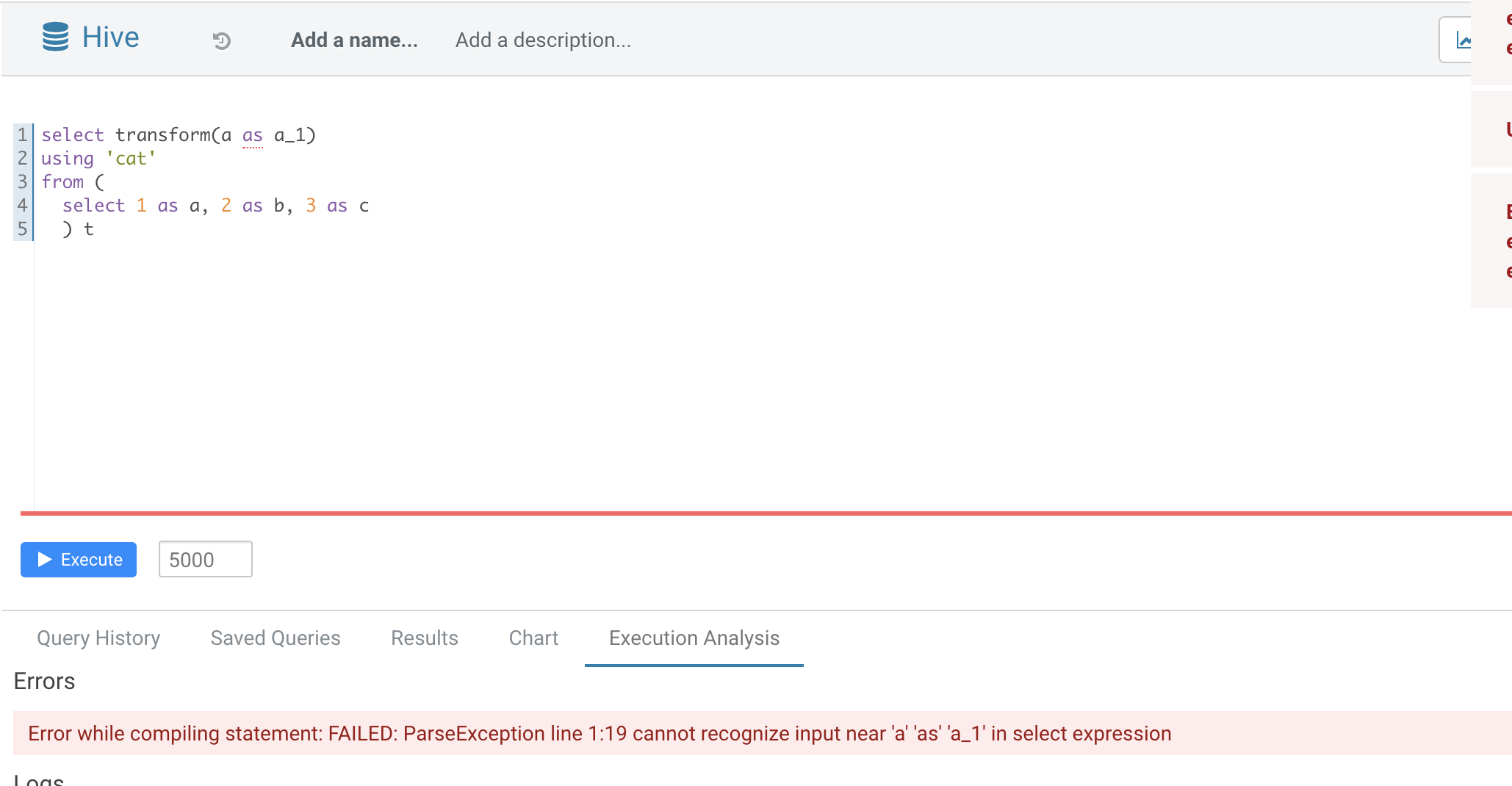 In this pr we forbid use alias in `TRANSFORM`'s inputs ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #32165 from AngersZhuuuu/SPARK-35070. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
### What changes were proposed in this pull request? When counting the number of started fetch requests, we should exclude the deferred requests. ### Why are the changes needed? Fix the wrong number in the log. ### Does this PR introduce _any_ user-facing change? Yes, users see the correct number of started requests in logs. ### How was this patch tested? Manually tested. Closes #32180 from Ngone51/count-deferred-request. Lead-authored-by: yi.wu <yi.wu@databricks.com> Co-authored-by: wuyi <yi.wu@databricks.com> Signed-off-by: attilapiros <piros.attila.zsolt@gmail.com>
### What changes were proposed in this pull request? There are some more changes in Koalas such as [databricks/koalas#2141](databricks/koalas@c8f803d), [databricks/koalas#2143](databricks/koalas@913d688) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`. ### Why are the changes needed? We should port the whole Koalas codes into PySpark and synchronize them. ### Does this PR introduce _any_ user-facing change? Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring. ### How was this patch tested? Manually tested in local. Closes #32154 from itholic/SPARK-34995. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…ark" This reverts commit 9689c44.
…uite ### What changes were proposed in this pull request? This PR fixes a test failure in `OracleIntegrationSuite`. After SPARK-34843 (#31965), the way to divide partitions is changed and `OracleIntegrationSuites` is affected. ``` [info] - SPARK-22814 support date/timestamp types in partitionColumn *** FAILED *** (230 milliseconds) [info] Set(""D" < '2018-07-11' or "D" is null", ""D" >= '2018-07-11' AND "D" < '2018-07-15'", ""D" >= '2018-07-15'") did not equal Set(""D" < '2018-07-10' or "D" is null", ""D" >= '2018-07-10' AND "D" < '2018-07-14'", ""D" >= '2018-07-14'") (OracleIntegrationSuite.scala:448) [info] Analysis: [info] Set(missingInLeft: ["D" < '2018-07-10' or "D" is null, "D" >= '2018-07-10' AND "D" < '2018-07-14', "D" >= '2018-07-14'], missingInRight: ["D" < '2018-07-11' or "D" is null, "D" >= '2018-07-11' AND "D" < '2018-07-15', "D" >= '2018-07-15']) ``` ### Why are the changes needed? To follow the previous change. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? The modified test. Closes #32186 from sarutak/fix-oracle-date-error. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas Index unit tests to PySpark. ### Why are the changes needed? Currently, the pandas-on-Spark modules are not tested fully. We should enable the Index unit tests. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Enable Index unit tests. Closes #32139 from xinrong-databricks/port.indexes_tests. Authored-by: Xinrong Meng <xinrong.meng@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…SI style ### What changes were proposed in this pull request? Handle `YearMonthIntervalType` and `DayTimeIntervalType` in the `sql()` and `toString()` method of `Literal`, and format the ANSI interval in the ANSI style. ### Why are the changes needed? To improve readability and UX with Spark SQL. For example, a test output before the changes: ``` -- !query select timestamp'2011-11-11 11:11:11' - interval '2' day -- !query schema struct<TIMESTAMP '2011-11-11 11:11:11' - 172800000000:timestamp> -- !query output 2011-11-09 11:11:11 ``` ### Does this PR introduce _any_ user-facing change? Should not since the new intervals haven't been released yet. ### How was this patch tested? By running new tests: ``` $ ./build/sbt "test:testOnly *LiteralExpressionSuite" ``` Closes #32196 from MaxGekk/literal-ansi-interval-sql. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request? Use hadoop FileSystem instead of FileInputStream. ### Why are the changes needed? Make `spark.scheduler.allocation.file` suport remote file. When using Spark as a server (e.g. SparkThriftServer), it's hard for user to specify a local path as the scheduler pool. ### Does this PR introduce _any_ user-facing change? Yes, a minor feature. ### How was this patch tested? Pass `core/src/test/scala/org/apache/spark/scheduler/PoolSuite.scala` and manul test After add config `spark.scheduler.allocation.file=hdfs:///tmp/fairscheduler.xml`. We intrudoce the configed pool.  Closes #32184 from ulysses-you/SPARK-35083. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
… single split file generated by JacksonGenerator when pretty option is true
### What changes were proposed in this pull request?
This issue fixes an issue that indentation of multiple output JSON records in a single split file are broken except for the first record in the split when `pretty` option is `true`.
```
// Run in the Spark Shell.
// Set spark.sql.leafNodeDefaultParallelism to 1 for the current master.
// Or set spark.default.parallelism for the previous releases.
spark.conf.set("spark.sql.leafNodeDefaultParallelism", 1)
val df = Seq("a", "b", "c").toDF
df.write.option("pretty", "true").json("/path/to/output")
# Run in a Shell
$ cat /path/to/output/*.json
{
"value" : "a"
}
{
"value" : "b"
}
{
"value" : "c"
}
```
### Why are the changes needed?
It's not pretty even though `pretty` option is true.
### Does this PR introduce _any_ user-facing change?
I think "No". Indentation style is changed but JSON format is not changed.
### How was this patch tested?
New test.
Closes #32203 from sarutak/fix-ugly-indentation.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request? There are some more changes in Koalas such as [databricks/koalas#2141](databricks/koalas@c8f803d), [databricks/koalas#2143](databricks/koalas@913d688) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`. ### Why are the changes needed? We should port the whole Koalas codes into PySpark and synchronize them. ### Does this PR introduce _any_ user-facing change? Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring. ### How was this patch tested? Manually tested in local. Closes #32197 from itholic/SPARK-34995-fix. Authored-by: itholic <haejoon.lee@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…nt docs only ### What changes were proposed in this pull request? Soften security warning and keep it in cluster management docs only, not in the main doc page, where it's not necessarily relevant. ### Why are the changes needed? The statement is perhaps unnecessarily 'frightening' as the first section in the main docs page. It applies to clusters not local mode, anyhow. ### Does this PR introduce _any_ user-facing change? Just a docs change. ### How was this patch tested? N/A Closes #32206 from srowen/SecurityStatement. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com>
… be displayed as actual value instead of Some(XX) ### What changes were proposed in this pull request? Make the attemptId in the log of historyServer to be more easily to read. ### Why are the changes needed? Option variable in Spark historyServer log should be displayed as actual value instead of Some(XX) ### Does this PR introduce any user-facing change? No ### How was this patch tested? manual test Closes #32189 from kyoty/history-server-print-option-variable. Authored-by: kyoty <echohlne@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? TL;DR: now it shows green yellow read status of tests instead of relying on a comment in a PR, **see HyukjinKwon#41 for an example**. This PR proposes the GitHub status checks instead of a comment that link to the build (from forked repository) in PRs. This is how it works: 1. **forked repo**: "Build and test" workflow is triggered when you create a branch to create a PR which uses your resources in GitHub Actions. 1. **main repo**: "Notify test workflow" (previously created a comment) now creates a in-progress status (yellow status) as a GitHub Actions check to your current PR. 1. **main repo**: "Update build status workflow" regularly (every 15 mins) checks open PRs, and updates the status of GitHub Actions checks at PRs according to the status of workflows in the forked repositories (status sync). **NOTE** that creating/updating statuses in the PRs is only allowed from the main repo. That's why the flow is as above. ### Why are the changes needed? The GitHub status shows a green although the tests are running, which is confusing. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually tested at: - HyukjinKwon#41 - HyukjinKwon#42 - HyukjinKwon#43 - HyukjinKwon#37 **queued**: <img width="861" alt="Screen Shot 2021-04-16 at 10 56 03 AM" src="https://user-images.githubusercontent.com/6477701/114960831-c9a73080-9ea2-11eb-8442-ddf3f6008a45.png"> **in progress**: <img width="871" alt="Screen Shot 2021-04-16 at 12 14 39 PM" src="https://user-images.githubusercontent.com/6477701/114966359-59ea7300-9ead-11eb-98cb-1e63323980ad.png"> **passed**:  **failure**:  Closes #32193 from HyukjinKwon/update-checks-pr-poc. Lead-authored-by: HyukjinKwon <gurwls223@apache.org> Co-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
### What changes were proposed in this pull request? SPARK-10498 added the initial Jira client requirement with 1.0.3 five year ago (2016 January). As of today, it causes `dev/merge_spark_pr.py` failure with `Python 3.9.4` due to this old dependency. This PR aims to upgrade it to the latest version, 2.0.0. The latest version is also a little old (2018 July). - https://pypi.org/project/jira/#history ### Why are the changes needed? `Jira==2.0.0` works well with both Python 3.8/3.9 while `Jira==1.0.3` fails with Python 3.9. **BEFORE** ``` $ pyenv global 3.9.4 $ pip freeze | grep jira jira==1.0.3 $ dev/merge_spark_pr.py Traceback (most recent call last): File "/Users/dongjoon/APACHE/spark-merge/dev/merge_spark_pr.py", line 39, in <module> import jira.client File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/__init__.py", line 5, in <module> from .config import get_jira File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/config.py", line 17, in <module> from .client import JIRA File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/client.py", line 165 validate=False, get_server_info=True, async=False, logging=True, max_retries=3): ^ SyntaxError: invalid syntax ``` **AFTER** ``` $ pip install jira==2.0.0 $ dev/merge_spark_pr.py git rev-parse --abbrev-ref HEAD Which pull request would you like to merge? (e.g. 34): ``` ### Does this PR introduce _any_ user-facing change? No. This is a committer-only script. ### How was this patch tested? Manually. Closes #32215 from dongjoon-hyun/jira. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…yTimeIntervalType in spark ### What changes were proposed in this pull request? The precision of `java.time.Duration` is nanosecond, but when it is used as `DayTimeIntervalType` in Spark, it is microsecond. At present, the `DayTimeIntervalType` data generated in the implementation of `RandomDataGenerator` is accurate to nanosecond, which will cause the `DayTimeIntervalType` to be converted to long, and then back to `DayTimeIntervalType` to lose the accuracy, which will cause the test to fail. For example: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137390/testReport/org.apache.spark.sql.hive.execution/HashAggregationQueryWithControlledFallbackSuite/udaf_with_all_data_types/ ### Why are the changes needed? Improve `RandomDataGenerator` so that the generated data fits the precision of DayTimeIntervalType in spark. ### Does this PR introduce _any_ user-facing change? 'No'. Just change the test class. ### How was this patch tested? Jenkins test. Closes #32212 from beliefer/SPARK-35116. Authored-by: beliefer <beliefer@163.com> Signed-off-by: Max Gekk <max.gekk@gmail.com>
…pressionSuite` ### What changes were proposed in this pull request? In the PR, I propose to add additional checks for ANSI interval types `YearMonthIntervalType` and `DayTimeIntervalType` to `LiteralExpressionSuite`. Also, I replaced some long literal values by `CalendarInterval` to check `CalendarIntervalType` that the tests were supposed to check. ### Why are the changes needed? To improve test coverage and have the same checks for ANSI types as for `CalendarIntervalType`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running the modified test suite: ``` $ build/sbt "test:testOnly *LiteralExpressionSuite" ``` Closes #32213 from MaxGekk/interval-literal-tests. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com>
…on `sum` ### What changes were proposed in this pull request? Extend the `Sum` expression to to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614. Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals. ### Why are the changes needed? Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Sum` to support `DayTimeIntervalType` and `YearMonthIntervalType`. ### Does this PR introduce _any_ user-facing change? 'No'. Should not since new types have not been released yet. ### How was this patch tested? Jenkins test Closes #32107 from beliefer/SPARK-34716. Lead-authored-by: gengjiaan <gengjiaan@360.cn> Co-authored-by: beliefer <beliefer@163.com> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com>
…uite` ### What changes were proposed in this pull request? Add checks for `YearMonthIntervalType` and `DayTimeIntervalType` to `MutableProjectionSuite`. ### Why are the changes needed? To improve test coverage, and the same checks as for `CalendarIntervalType`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running the modified test suite: ``` $ build/sbt "test:testOnly *MutableProjectionSuite" ``` Closes #32225 from MaxGekk/test-ansi-intervals-in-MutableProjectionSuite. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
…ould be truncated if it is too long ### What changes were proposed in this pull request? the auto-generated rdd's name in the storage tab should be truncated as a single line if it is too long. ### Why are the changes needed? to make the ui shows more friendly. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? just a simple modifition in css, manual test works well like below: before modified:  after modified: Tht titile needs just one line:  Closes #32191 from kyoty/storage-rdd-titile-display-improve. Authored-by: kyoty <echohlne@gmail.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
{kind=link}
{kind=link}
… HashJoin ### What changes were proposed in this pull request? It seems that we miss classifying one `SparkOutOfMemoryError` in `HashedRelation`. Add the error classification for it. In addition, clean up two errors definition of `HashJoin` as they are not used. ### Why are the changes needed? Better error classification. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32211 from c21/error-message. Authored-by: Cheng Su <chengsu@fb.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
…gate expressions without aggregate function ### What changes were proposed in this pull request? This PR: - Adds a new expression `GroupingExprRef` that can be used in aggregate expressions of `Aggregate` nodes to refer grouping expressions by index. These expressions capture the data type and nullability of the referred grouping expression. - Adds a new rule `EnforceGroupingReferencesInAggregates` that inserts the references in the beginning of the optimization phase. - Adds a new rule `UpdateGroupingExprRefNullability` to update nullability of `GroupingExprRef` expressions as nullability of referred grouping expression can change during optimization. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [NOT groupingexprref(0) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #31913 from peter-toth/SPARK-34581-keep-grouping-expressions. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…mand ### What changes were proposed in this pull request? Now that `AnalysisOnlyCommand` in introduced in #32032, `CacheTable` and `UncacheTable` can extend `AnalysisOnlyCommand` to simplify the code base. For example, the logic to handle these commands such that the tables are only analyzed is scattered across different places. ### Why are the changes needed? To simplify the code base to handle these two commands. ### Does this PR introduce _any_ user-facing change? No, just internal refactoring. ### How was this patch tested? The existing tests (e.g., `CachedTableSuite`) cover the changes in this PR. For example, if I make `CacheTable`/`UncacheTable` extend `LeafCommand`, there are few failures in `CachedTableSuite`. Closes #32220 from imback82/cache_cmd_analysis_only. Authored-by: Terry Kim <yuminkim@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…ta using no-serde mode script transform ### What changes were proposed in this pull request? Support no-serde mode script transform use ArrayType/MapType/StructStpe data. ### Why are the changes needed? Make user can process array/map/struct data ### Does this PR introduce _any_ user-facing change? Yes, user can process array/map/struct data in script transform `no-serde` mode ### How was this patch tested? Added UT Closes #30957 from AngersZhuuuu/SPARK-31937. Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com> Co-authored-by: angerszhu <angers.zhu@gmail.com> Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…r size ### What changes were proposed in this pull request? This PR makes the input buffer configurable (as an internal configuration). This is mainly to work around the regression in uniVocity/univocity-parsers#449. This is particularly useful for SQL workloads that requires to rewrite the `CREATE TABLE` with options. ### Why are the changes needed? To work around uniVocity/univocity-parsers#449. ### Does this PR introduce _any_ user-facing change? No, it's only internal option. ### How was this patch tested? Manually tested by modifying the unittest added in #31858 as below: ```diff diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala index fd25a79619d..705f38dbfbd 100644 --- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala +++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala -2456,6 +2456,7 abstract class CSVSuite test("SPARK-34768: counting a long record with ignoreTrailingWhiteSpace set to true") { val bufSize = 128 val line = "X" * (bufSize - 1) + "| |" + spark.conf.set("spark.sql.csv.parser.inputBufferSize", 128) withTempPath { path => Seq(line).toDF.write.text(path.getAbsolutePath) assert(spark.read.format("csv") ``` Closes #32231 from HyukjinKwon/SPARK-35045-followup. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…on `avg` ### What changes were proposed in this pull request? Extend the `Average` expression to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614. Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals. ### Why are the changes needed? Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Average` to support `DayTimeIntervalType` and `YearMonthIntervalType`. ### Does this PR introduce _any_ user-facing change? 'No'. Should not since new types have not been released yet. ### How was this patch tested? Jenkins test Closes #32229 from beliefer/SPARK-34837. Authored-by: gengjiaan <gengjiaan@360.cn> Signed-off-by: Max Gekk <max.gekk@gmail.com>
…vals ### What changes were proposed in this pull request? Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports: - DAY TO HOUR - DAY TO MINUTE - DAY TO SECOND - HOUR TO MINUTE - HOUR TO SECOND - MINUTE TO SECOND All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units. **Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values. Closes #32176 ### Why are the changes needed? To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`. ### Does this PR introduce _any_ user-facing change? Yes. Before: ```sql spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND; 1 days 1 hours 2 minutes 3.123 seconds spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND); interval ``` After: ```sql spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND; 1 01:02:03.123000000 spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND); day-time interval ``` ### How was this patch tested? 1. By running the affected test suites: ``` $ ./build/sbt "test:testOnly *.ExpressionParserSuite" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql" ``` 2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output: ```sql > SELECT interval '999' second; 0 years 0 mons 0 days 0 hours 16 mins 39.00 secs ``` Closes #32209 from MaxGekk/parse-ansi-interval-literals. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com>
…nd duration <-> micros ### What changes were proposed in this pull request? Similarly to the test from the PR #31799, add tests: 1. Months -> Period -> Months 2. Period -> Months -> Period 3. Duration -> micros -> Duration ### Why are the changes needed? Add round trip tests for period <-> month and duration <-> micros ### Does this PR introduce _any_ user-facing change? 'No'. Just test cases. ### How was this patch tested? Jenkins test Closes #32234 from beliefer/SPARK-34715. Authored-by: gengjiaan <gengjiaan@360.cn> Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request? Although AS-IS master branch already works with K8s 1.20, this PR aims to upgrade K8s client to 5.3.0 to support K8s 1.20 officially. - https://github.com/fabric8io/kubernetes-client#compatibility-matrix The following are the notable breaking API changes. 1. Remove Doneable (5.0+): - fabric8io/kubernetes-client#2571 2. Change Watcher.onClose signature (5.0+): - fabric8io/kubernetes-client#2616 3. Change Readiness (5.1+) - fabric8io/kubernetes-client#2796 ### Why are the changes needed? According to the compatibility matrix, this makes Apache Spark and its external cluster manager extension support all K8s 1.20 features officially for Apache Spark 3.2.0. ### Does this PR introduce _any_ user-facing change? Yes, this is a dev dependency change which affects K8s cluster extension users. ### How was this patch tested? Pass the CIs. This is manually tested with K8s IT. ``` KubernetesSuite: - Run SparkPi with no resources - Run SparkPi with a very long application name. - Use SparkLauncher.NO_RESOURCE - Run SparkPi with a master URL without a scheme. - Run SparkPi with an argument. - Run SparkPi with custom labels, annotations, and environment variables. - All pods have the same service account by default - Run extraJVMOptions check on driver - Run SparkRemoteFileTest using a remote data file - Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties - Run SparkPi with env and mount secrets. - Run PySpark on simple pi.py example - Run PySpark to test a pyfiles example - Run PySpark with memory customization - Run in client mode. - Start pod creation from template - PVs with local storage - Launcher client dependencies - SPARK-33615: Launcher client archives - SPARK-33748: Launcher python client respecting PYSPARK_PYTHON - SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python - Launcher python client dependencies using a zip file - Test basic decommissioning - Test basic decommissioning with shuffle cleanup - Test decommissioning with dynamic allocation & shuffle cleanups - Test decommissioning timeouts - Run SparkR on simple dataframe.R example Run completed in 17 minutes, 44 seconds. Total number of tests run: 27 Suites: completed 2, aborted 0 Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes #32221 from dongjoon-hyun/SPARK-K8S-530. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…ted and meaningful
### What changes were proposed in this pull request?
Firstly let's take a look at the definition and comment.
```
// A fake config which is only here for backward compatibility reasons. This config has no effect
// to Spark, just for reporting the builtin Hive version of Spark to existing applications that
// already rely on this config.
val FAKE_HIVE_VERSION = buildConf("spark.sql.hive.version")
.doc(s"deprecated, please use ${HIVE_METASTORE_VERSION.key} to get the Hive version in Spark.")
.version("1.1.1")
.fallbackConf(HIVE_METASTORE_VERSION)
```
It is used for reporting the built-in Hive version but the current status is unsatisfactory, as it is could be changed in many ways e.g. --conf/SET syntax.
It is marked as deprecated but kept a long way until now. I guess it is hard for us to remove it and not even necessary.
On second thought, it's actually good for us to keep it to work with the `spark.sql.hive.metastore.version`. As when `spark.sql.hive.metastore.version` is changed, it could be used to report the compiled hive version statically, it's useful when an error occurs in this case. So this parameter should be fixed to compiled hive version.
### Why are the changes needed?
`spark.sql.hive.version` is useful in certain cases and should be read-only
### Does this PR introduce _any_ user-facing change?
`spark.sql.hive.version` now is read-only
### How was this patch tested?
new test cases
Closes #32200 from yaooqinn/SPARK-35102.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? This proposes to document the available metrics for ExecutorAllocationManager in the Spark monitoring documentation. ### Why are the changes needed? The ExecutorAllocationManager is instrumented with metrics using the Spark metrics system. The relevant work is in SPARK-7007 and SPARK-33763 ExecutorAllocationManager metrics are currently undocumented. ### Does this PR introduce _any_ user-facing change? This PR adds documentation only. ### How was this patch tested? na Closes #32500 from LucaCanali/followupMetricsDocSPARK33763. Authored-by: Luca Canali <luca.canali@cern.ch> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
… tests ### What changes were proposed in this pull request? This PR proposes to skip the "q6", "q34", "q64", "q74", "q75", "q78" queries in the TPCDS-related tests because the TPCDS v2.7 queries have almost the same ones; the only differences in these queries are ORDER BY columns. ### Why are the changes needed? To improve test performance. ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Existing tests. Closes #32520 from maropu/SkipDupQueries. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request? This PR allows the PR source branch to include slashes. ### Why are the changes needed? There are PRs whose source branches include slashes, like `issues/SPARK-35119/gha` here or #32523. Before the fix, the PR build fails in `Sync the current branch with the latest in Apache Spark` phase. For example, at #32523, the source branch is `issues/SPARK-35382/nested_higher_order_functions`: ``` ... fatal: couldn't find remote ref nested_higher_order_functions Error: Process completed with exit code 128. ``` (https://github.com/ueshin/apache-spark/runs/2569356241) ### Does this PR introduce _any_ user-facing change? No, this is a dev-only change. ### How was this patch tested? This PR source branch includes slashes and #32525 doesn't. Closes #32524 from ueshin/issues/SPARK-35119/gha. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request? Change `map` in `InvokeLike.invoke` to a while loop to improve performance, following Spark [style guide](https://github.com/databricks/scala-style-guide#traversal-and-zipwithindex). ### Why are the changes needed? `InvokeLike.invoke`, which is used in non-codegen path for `Invoke` and `StaticInvoke`, currently uses `map` to evaluate arguments: ```scala val args = arguments.map(e => e.eval(input).asInstanceOf[Object]) if (needNullCheck && args.exists(_ == null)) { // return null if one of arguments is null null } else { ... ``` which is pretty expensive if the method itself is trivial. We can change it to a plain while loop. <img width="871" alt="Screen Shot 2021-05-12 at 12 19 59 AM" src="https://user-images.githubusercontent.com/506679/118055719-7f985a00-b33d-11eb-943b-cf85eab35f44.png"> Benchmark results show this can improve as much as 3x from `V2FunctionBenchmark`: Before ``` OpenJDK 64-Bit Server VM 1.8.0_292-b10 on Linux 5.4.0-1046-azure Intel(R) Xeon(R) CPU E5-2673 v3 2.40GHz scalar function (long + long) -> long, result_nullable = false codegen = false: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative -------------------------------------------------------------------------------------------------------------------------------------------------------------- native_long_add 36506 36656 251 13.7 73.0 1.0X java_long_add_default 47151 47540 370 10.6 94.3 0.8X java_long_add_magic 178691 182457 1327 2.8 357.4 0.2X java_long_add_static_magic 177151 178258 1151 2.8 354.3 0.2X ``` After ``` OpenJDK 64-Bit Server VM 1.8.0_292-b10 on Linux 5.4.0-1046-azure Intel(R) Xeon(R) CPU E5-2673 v3 2.40GHz scalar function (long + long) -> long, result_nullable = false codegen = false: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative -------------------------------------------------------------------------------------------------------------------------------------------------------------- native_long_add 29897 30342 568 16.7 59.8 1.0X java_long_add_default 40628 41075 664 12.3 81.3 0.7X java_long_add_magic 54553 54755 182 9.2 109.1 0.5X java_long_add_static_magic 55410 55532 127 9.0 110.8 0.5X ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #32527 from sunchao/SPARK-35384. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
…rame functions in Python APIs ### What changes were proposed in this pull request? This PR fixes the same issue as #32424. ```py from pyspark.sql.functions import flatten, struct, transform df = spark.sql("SELECT array(1, 2, 3) as numbers, array('a', 'b', 'c') as letters") df.select(flatten( transform( "numbers", lambda number: transform( "letters", lambda letter: struct(number.alias("n"), letter.alias("l")) ) ) ).alias("zipped")).show(truncate=False) ``` **Before:** ``` +------------------------------------------------------------------------+ |zipped | +------------------------------------------------------------------------+ |[{a, a}, {b, b}, {c, c}, {a, a}, {b, b}, {c, c}, {a, a}, {b, b}, {c, c}]| +------------------------------------------------------------------------+ ``` **After:** ``` +------------------------------------------------------------------------+ |zipped | +------------------------------------------------------------------------+ |[{1, a}, {1, b}, {1, c}, {2, a}, {2, b}, {2, c}, {3, a}, {3, b}, {3, c}]| +------------------------------------------------------------------------+ ``` ### Why are the changes needed? To produce the correct results. ### Does this PR introduce _any_ user-facing change? Yes, it fixes the results to be correct as mentioned above. ### How was this patch tested? Added a unit test as well as manually. Closes #32523 from ueshin/issues/SPARK-35382/nested_higher_order_functions. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
…file ### What changes were proposed in this pull request? This PR aims to unify two K8s version variables in two `pom.xml`s into one. `kubernetes-client.version` is correct because the artifact ID is `kubernetes-client`. ``` kubernetes.client.version (kubernetes/core module) kubernetes-client.version (kubernetes/integration-test module) ``` ### Why are the changes needed? Having two variables for the same value is confusing and inconvenient when we upgrade K8s versions. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the CIs. (The compilation test passes are enough.) Closes #32531 from dongjoon-hyun/SPARK-35394. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? In yaooqinn/itachi#8, we had a discussion about the current extension injection for the spark session. We've agreed that the current way is not that convenient for both third-party developers and end-users. It's much simple if third-party developers can provide a resource file that contains default extensions for Spark to load ahead ### Why are the changes needed? better use experience ### Does this PR introduce _any_ user-facing change? no, dev change ### How was this patch tested? new tests Closes #32515 from yaooqinn/SPARK-35380. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
As title. This PR is to add code-gen support for LEFT SEMI sort merge join. The main change is to add `semiJoin` code path in `SortMergeJoinExec.doProduce()` and introduce `onlyBufferFirstMatchedRow` in `SortMergeJoinExec.genScanner()`. The latter is for left semi sort merge join without condition. For this kind of query, we don't need to buffer all matched rows, but only the first one (this is same as non-code-gen code path).
Example query:
```
val df1 = spark.range(10).select($"id".as("k1"))
val df2 = spark.range(4).select($"id".as("k2"))
val oneJoinDF = df1.join(df2.hint("SHUFFLE_MERGE"), $"k1" === $"k2", "left_semi")
```
Example of generated code for the query:
```
== Subtree 5 / 5 (maxMethodCodeSize:302; maxConstantPoolSize:156(0.24% used); numInnerClasses:0) ==
*(5) Project [id#0L AS k1#2L]
+- *(5) SortMergeJoin [id#0L], [k2#6L], LeftSemi
:- *(2) Sort [id#0L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(id#0L, 5), ENSURE_REQUIREMENTS, [id=#27]
: +- *(1) Range (0, 10, step=1, splits=2)
+- *(4) Sort [k2#6L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(k2#6L, 5), ENSURE_REQUIREMENTS, [id=#33]
+- *(3) Project [id#4L AS k2#6L]
+- *(3) Range (0, 4, step=1, splits=2)
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage5(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=5
/* 006 */ final class GeneratedIteratorForCodegenStage5 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private scala.collection.Iterator smj_streamedInput_0;
/* 010 */ private scala.collection.Iterator smj_bufferedInput_0;
/* 011 */ private InternalRow smj_streamedRow_0;
/* 012 */ private InternalRow smj_bufferedRow_0;
/* 013 */ private long smj_value_2;
/* 014 */ private org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArray smj_matches_0;
/* 015 */ private long smj_value_3;
/* 016 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] smj_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[2];
/* 017 */
/* 018 */ public GeneratedIteratorForCodegenStage5(Object[] references) {
/* 019 */ this.references = references;
/* 020 */ }
/* 021 */
/* 022 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 023 */ partitionIndex = index;
/* 024 */ this.inputs = inputs;
/* 025 */ smj_streamedInput_0 = inputs[0];
/* 026 */ smj_bufferedInput_0 = inputs[1];
/* 027 */
/* 028 */ smj_matches_0 = new org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArray(1, 2147483647);
/* 029 */ smj_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 030 */ smj_mutableStateArray_0[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 031 */
/* 032 */ }
/* 033 */
/* 034 */ private boolean findNextJoinRows(
/* 035 */ scala.collection.Iterator streamedIter,
/* 036 */ scala.collection.Iterator bufferedIter) {
/* 037 */ smj_streamedRow_0 = null;
/* 038 */ int comp = 0;
/* 039 */ while (smj_streamedRow_0 == null) {
/* 040 */ if (!streamedIter.hasNext()) return false;
/* 041 */ smj_streamedRow_0 = (InternalRow) streamedIter.next();
/* 042 */ long smj_value_0 = smj_streamedRow_0.getLong(0);
/* 043 */ if (false) {
/* 044 */ smj_streamedRow_0 = null;
/* 045 */ continue;
/* 046 */
/* 047 */ }
/* 048 */ if (!smj_matches_0.isEmpty()) {
/* 049 */ comp = 0;
/* 050 */ if (comp == 0) {
/* 051 */ comp = (smj_value_0 > smj_value_3 ? 1 : smj_value_0 < smj_value_3 ? -1 : 0);
/* 052 */ }
/* 053 */
/* 054 */ if (comp == 0) {
/* 055 */ return true;
/* 056 */ }
/* 057 */ smj_matches_0.clear();
/* 058 */ }
/* 059 */
/* 060 */ do {
/* 061 */ if (smj_bufferedRow_0 == null) {
/* 062 */ if (!bufferedIter.hasNext()) {
/* 063 */ smj_value_3 = smj_value_0;
/* 064 */ return !smj_matches_0.isEmpty();
/* 065 */ }
/* 066 */ smj_bufferedRow_0 = (InternalRow) bufferedIter.next();
/* 067 */ long smj_value_1 = smj_bufferedRow_0.getLong(0);
/* 068 */ if (false) {
/* 069 */ smj_bufferedRow_0 = null;
/* 070 */ continue;
/* 071 */ }
/* 072 */ smj_value_2 = smj_value_1;
/* 073 */ }
/* 074 */
/* 075 */ comp = 0;
/* 076 */ if (comp == 0) {
/* 077 */ comp = (smj_value_0 > smj_value_2 ? 1 : smj_value_0 < smj_value_2 ? -1 : 0);
/* 078 */ }
/* 079 */
/* 080 */ if (comp > 0) {
/* 081 */ smj_bufferedRow_0 = null;
/* 082 */ } else if (comp < 0) {
/* 083 */ if (!smj_matches_0.isEmpty()) {
/* 084 */ smj_value_3 = smj_value_0;
/* 085 */ return true;
/* 086 */ } else {
/* 087 */ smj_streamedRow_0 = null;
/* 088 */ }
/* 089 */ } else {
/* 090 */ if (smj_matches_0.isEmpty()) {
/* 091 */ smj_matches_0.add((UnsafeRow) smj_bufferedRow_0);
/* 092 */ }
/* 093 */
/* 094 */ smj_bufferedRow_0 = null;
/* 095 */ }
/* 096 */ } while (smj_streamedRow_0 != null);
/* 097 */ }
/* 098 */ return false; // unreachable
/* 099 */ }
/* 100 */
/* 101 */ protected void processNext() throws java.io.IOException {
/* 102 */ while (findNextJoinRows(smj_streamedInput_0, smj_bufferedInput_0)) {
/* 103 */ long smj_value_4 = -1L;
/* 104 */ smj_value_4 = smj_streamedRow_0.getLong(0);
/* 105 */ scala.collection.Iterator<UnsafeRow> smj_iterator_0 = smj_matches_0.generateIterator();
/* 106 */ boolean smj_hasOutputRow_0 = false;
/* 107 */
/* 108 */ while (!smj_hasOutputRow_0 && smj_iterator_0.hasNext()) {
/* 109 */ InternalRow smj_bufferedRow_1 = (InternalRow) smj_iterator_0.next();
/* 110 */
/* 111 */ smj_hasOutputRow_0 = true;
/* 112 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
/* 113 */
/* 114 */ // common sub-expressions
/* 115 */
/* 116 */ smj_mutableStateArray_0[1].reset();
/* 117 */
/* 118 */ smj_mutableStateArray_0[1].write(0, smj_value_4);
/* 119 */ append((smj_mutableStateArray_0[1].getRow()).copy());
/* 120 */
/* 121 */ }
/* 122 */ if (shouldStop()) return;
/* 123 */ }
/* 124 */ ((org.apache.spark.sql.execution.joins.SortMergeJoinExec) references[1] /* plan */).cleanupResources();
/* 125 */ }
/* 126 */
/* 127 */ }
```
### Why are the changes needed?
Improve query CPU performance. Test with one query:
```
def sortMergeJoin(): Unit = {
val N = 2 << 20
codegenBenchmark("left semi sort merge join", N) {
val df1 = spark.range(N).selectExpr(s"id * 2 as k1")
val df2 = spark.range(N).selectExpr(s"id * 3 as k2")
val df = df1.join(df2, col("k1") === col("k2"), "left_semi")
assert(df.queryExecution.sparkPlan.find(_.isInstanceOf[SortMergeJoinExec]).isDefined)
df.noop()
}
}
```
Seeing 30% of run-time improvement:
```
Running benchmark: left semi sort merge join
Running case: left semi sort merge join code-gen off
Stopped after 2 iterations, 1369 ms
Running case: left semi sort merge join code-gen on
Stopped after 5 iterations, 2743 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.16
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
left semi sort merge join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
left semi sort merge join code-gen off 676 685 13 3.1 322.2 1.0X
left semi sort merge join code-gen on 524 549 32 4.0 249.7 1.3X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `WholeStageCodegenSuite.scala` and `ExistenceJoinSuite.scala`.
Closes #32528 from c21/smj-left-semi.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…tion ### What changes were proposed in this pull request? In Spark, we have an extension in the MERGE syntax: INSERT/UPDATE *. This is not from ANSI standard or any other mainstream databases, so we need to define the behaviors by our own. The behavior today is very weird: assume the source table has `n1` columns, target table has `n2` columns. We generate the assignments by taking the first `min(n1, n2)` columns from source & target tables and pairing them by ordinal. This PR proposes a more reasonable behavior: take all the columns from target table as keys, and find the corresponding columns from source table by name as values. ### Why are the changes needed? Fix the MEREG INSERT/UPDATE * to be more user-friendly and easy to do schema evolution. ### Does this PR introduce _any_ user-facing change? Yes, but MERGE is only supported by very few data sources. ### How was this patch tested? new tests Closes #32192 from cloud-fan/merge. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…be reused ### What changes were proposed in this pull request? We have supported DPP in AQE when the join is Broadcast hash join before applying the AQE rules in [SPARK-34168](https://issues.apache.org/jira/browse/SPARK-34168), which has some limitations. It only apply DPP when the small table side executed firstly and then the big table side can reuse the broadcast exchange in small table side. This PR is to address the above limitations and can apply the DPP when the broadcast exchange can be reused. ### Why are the changes needed? Resolve the limitations when both enabling DPP and AQE ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Adding new ut Closes #31756 from JkSelf/supportDPP2. Authored-by: jiake <ke.a.jia@intel.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…feature.py ### What changes were proposed in this pull request? This PR removes the check of `summary.logLikelihood` in ml/clustering.py - this GMM test is quite flaky. It fails easily e.g., if: - change number of partitions; - just change the way to compute the sum of weights; - change the underlying BLAS impl Also uses more permissive precision on `Word2Vec` test case. ### Why are the changes needed? To recover the build and tests. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing test cases. Closes #32533 from zhengruifeng/SPARK_35392_disable_flaky_gmm_test. Lead-authored-by: Ruifeng Zheng <ruifengz@foxmail.com> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request? `./build/mvn` now downloads the .sha512 checksum of Maven artifacts it downloads, and checks the checksum after download. ### Why are the changes needed? This ensures the integrity of the Maven artifact during a user's build, which may come from several non-ASF mirrors. ### Does this PR introduce _any_ user-facing change? Should not affect anything about Spark per se, just the build. ### How was this patch tested? Manual testing wherein I forced Maven/Scala download, verified checksums are downloaded and checked, and verified it fails on error with a corrupted checksum. Closes #32505 from srowen/SPARK-35373. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request? Add New SQL functions: * TRY_ADD * TRY_DIVIDE These expressions are identical to the following expression under ANSI mode except that it returns null if error occurs: * ADD * DIVIDE Note: it is easy to add other expressions like `TRY_SUBTRACT`/`TRY_MULTIPLY` but let's control the number of these new expressions and just add `TRY_ADD` and `TRY_DIVIDE` for now. ### Why are the changes needed? 1. Users can manage to finish queries without interruptions in ANSI mode. 2. Users can get NULLs instead of unreasonable results if overflow occurs when ANSI mode is off. For example, the behavior of the following SQL operations is unreasonable: ``` 2147483647 + 2 => -2147483647 ``` With the new safe version SQL functions: ``` TRY_ADD(2147483647, 2) => null ``` Note: **We should only add new expressions to important operators, instead of adding new safe expressions for all the expressions that can throw errors.** ### Does this PR introduce _any_ user-facing change? Yes, new SQL functions: TRY_ADD/TRY_DIVIDE ### How was this patch tested? Unit test Closes #32292 from gengliangwang/try_add. Authored-by: Gengliang Wang <ltnwgl@gmail.com> Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request? Add a new config to make cache plan disable configs configurable. ### Why are the changes needed? The disable configs of cache plan if to avoid the perfermance regression, but not all the query will slow than before due to AQE or bucket scan enabled. It's useful to make a new config so that user can decide if some configs should be disabled during cache plan. ### Does this PR introduce _any_ user-facing change? Yes, a new config. ### How was this patch tested? Add test. Closes #32482 from ulysses-you/SPARK-35332. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? This PR group exception messages in `sql/core/src/main/scala/org/apache/spark/sql/streaming`. ### Why are the changes needed? It will largely help with standardization of error messages and its maintenance. ### Does this PR introduce _any_ user-facing change? No. Error messages remain unchanged. ### How was this patch tested? No new tests - pass all original tests to make sure it doesn't break any existing behavior. Closes #32464 from beliefer/SPARK-35062. Lead-authored-by: gengjiaan <gengjiaan@360.cn> Co-authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…orStreaming` ### What changes were proposed in this pull request? Currently, in DSv2, we are still using the deprecated `buildForBatch` and `buildForStreaming`. This PR implements the `build`, `toBatch`, `toStreaming` interfaces to replace the deprecated ones. ### Why are the changes needed? Code refactor ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? exsting UT Closes #32497 from linhongliu-db/dsv2-writer. Lead-authored-by: Linhong Liu <linhong.liu@databricks.com> Co-authored-by: Linhong Liu <67896261+linhongliu-db@users.noreply.github.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…hub Actions ### What changes were proposed in this pull request? Currently pip packaging test is being skipped: ``` ======================================================================== Running PySpark packaging tests ======================================================================== Constructing virtual env for testing Missing virtualenv & conda, skipping pip installability tests Cleaning up temporary directory - /tmp/tmp.iILYWISPXW ``` See https://github.com/apache/spark/runs/2568923639?check_suite_focus=true GitHub Actions's image has its default Conda installed at `/usr/share/miniconda` but seems like the image we're using for PySpark does not have it (which is legitimate). This PR proposes to install Conda to use in pip packaging tests in GitHub Actions. ### Why are the changes needed? To recover the test coverage. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? It was tested in my fork: https://github.com/HyukjinKwon/spark/runs/2575126882?check_suite_focus=true ``` ======================================================================== Running PySpark packaging tests ======================================================================== Constructing virtual env for testing Using conda virtual environments Testing pip installation with python 3.6 Using /tmp/tmp.qPjTenqfGn for virtualenv Collecting package metadata (current_repodata.json): ...working... done Solving environment: ...working... failed with repodata from current_repodata.json, will retry with next repodata source. Collecting package metadata (repodata.json): ...working... done Solving environment: ...working... done ## Package Plan ## environment location: /tmp/tmp.qPjTenqfGn/3.6 added / updated specs: - numpy - pandas - pip - python=3.6 - setuptools ... Successfully ran pip sanity check ``` Closes #32537 from HyukjinKwon/SPARK-35393. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? This patch replaces `sys.err` usages with explicit exception types. ### Why are the changes needed? Motivated by the previous comment #32519 (comment), it sounds better to replace `sys.err` usages with explicit exception type. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32535 from viirya/replace-sys-err. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? Adds the exec loss reason to the Spark web UI & in doing so also fix the Kube integration to pass exec loss reason into core. UI change:  ### Why are the changes needed? Debugging Spark jobs is *hard*, making it clearer why executors have exited could help. ### Does this PR introduce _any_ user-facing change? Yes a new column on the executor page. ### How was this patch tested? K8s unit test updated to validate exec loss reasons are passed through regardless of exec alive state, manual testing to validate the UI. Closes #32436 from holdenk/SPARK-34764-propegate-reason-for-exec-loss. Lead-authored-by: Holden Karau <hkarau@apple.com> Co-authored-by: Holden Karau <holden@pigscanfly.ca> Signed-off-by: Holden Karau <hkarau@apple.com>
{kind=link}
### What changes were proposed in this pull request?
This PR intends to split generated switch code into smaller ones in `ExpandExec`. In the current master, even a simple query like the one below generates a large method whose size (`maxMethodCodeSize:7448`) is close to `8000` (`CodeGenerator.DEFAULT_JVM_HUGE_METHOD_LIMIT`);
```
scala> val df = Seq(("2016-03-27 19:39:34", 1, "a"), ("2016-03-27 19:39:56", 2, "a"), ("2016-03-27 19:39:27", 4, "b")).toDF("time", "value", "id")
scala> val rdf = df.select(window($"time", "10 seconds", "3 seconds", "0 second"), $"value").orderBy($"window.start".asc, $"value".desc).select("value")
scala> sql("SET spark.sql.adaptive.enabled=false")
scala> import org.apache.spark.sql.execution.debug._
scala> rdf.debugCodegen
Found 2 WholeStageCodegen subtrees.
== Subtree 1 / 2 (maxMethodCodeSize:7448; maxConstantPoolSize:189(0.29% used); numInnerClasses:0) ==
^^^^
*(1) Project [window#34.start AS _gen_alias_39#39, value#11]
+- *(1) Filter ((isnotnull(window#34) AND (cast(time#10 as timestamp) >= window#34.start)) AND (cast(time#10 as timestamp) < window#34.end))
+- *(1) Expand [List(named_struct(start, precisetimestampcon...
/* 028 */ private void expand_doConsume_0(InternalRow localtablescan_row_0, UTF8String expand_expr_0_0, boolean expand_exprIsNull_0_0, int expand_expr_1_0) throws java.io.IOException {
/* 029 */ boolean expand_isNull_0 = true;
/* 030 */ InternalRow expand_value_0 =
/* 031 */ null;
/* 032 */ for (int expand_i_0 = 0; expand_i_0 < 4; expand_i_0 ++) {
/* 033 */ switch (expand_i_0) {
/* 034 */ case 0:
(too many code lines)
/* 517 */ break;
/* 518 */
/* 519 */ case 1:
(too many code lines)
/* 1002 */ break;
/* 1003 */
/* 1004 */ case 2:
(too many code lines)
/* 1487 */ break;
/* 1488 */
/* 1489 */ case 3:
(too many code lines)
/* 1972 */ break;
/* 1973 */ }
/* 1974 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[33] /* numOutputRows */).add(1);
/* 1975 */
/* 1976 */ do {
/* 1977 */ boolean filter_value_2 = !expand_isNull_0;
/* 1978 */ if (!filter_value_2) continue;
```
The fix in this PR can make the method smaller as follows;
```
Found 2 WholeStageCodegen subtrees.
== Subtree 1 / 2 (maxMethodCodeSize:1713; maxConstantPoolSize:210(0.32% used); numInnerClasses:0) ==
^^^^
*(1) Project [window#17.start AS _gen_alias_32#32, value#11]
+- *(1) Filter ((isnotnull(window#17) AND (cast(time#10 as timestamp) >= window#17.start)) AND (cast(time#10 as timestamp) < window#17.end))
+- *(1) Expand [List(named_struct(start, precisetimestampcon...
/* 032 */ private void expand_doConsume_0(InternalRow localtablescan_row_0, UTF8String expand_expr_0_0, boolean expand_exprIsNull_0_0, int expand_expr_1_0) throws java.io.IOException {
/* 033 */ for (int expand_i_0 = 0; expand_i_0 < 4; expand_i_0 ++) {
/* 034 */ switch (expand_i_0) {
/* 035 */ case 0:
/* 036 */ expand_switchCaseCode_0(expand_exprIsNull_0_0, expand_expr_0_0);
/* 037 */ break;
/* 038 */
/* 039 */ case 1:
/* 040 */ expand_switchCaseCode_1(expand_exprIsNull_0_0, expand_expr_0_0);
/* 041 */ break;
/* 042 */
/* 043 */ case 2:
/* 044 */ expand_switchCaseCode_2(expand_exprIsNull_0_0, expand_expr_0_0);
/* 045 */ break;
/* 046 */
/* 047 */ case 3:
/* 048 */ expand_switchCaseCode_3(expand_exprIsNull_0_0, expand_expr_0_0);
/* 049 */ break;
/* 050 */ }
/* 051 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[33] /* numOutputRows */).add(1);
/* 052 */
/* 053 */ do {
/* 054 */ boolean filter_value_2 = !expand_resultIsNull_0;
/* 055 */ if (!filter_value_2) continue;
/* 056 */
...
```
### Why are the changes needed?
For better generated code.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
GA passed.
Closes #32457 from maropu/splitSwitchCode.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
…tion documentation ### What changes were proposed in this pull request? In this PR I'm adding Structured Streaming Web UI state information documentation. ### Why are the changes needed? Missing documentation. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? ``` cd docs/ SKIP_API=1 bundle exec jekyll build ``` Manual webpage check. Closes #32433 from gaborgsomogyi/SPARK-35311. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
…r JavaScript linter ### What changes were proposed in this pull request? This PR is a followup of #32436 which broke JavaScript linter. There was a logical conflict - the linter was added after the last successful test run in that PR. ``` added 118 packages in 1.482s /__w/spark/spark/core/src/main/resources/org/apache/spark/ui/static/executorspage.js 34:41 error 'type' is defined but never used. Allowed unused args must match /^_ignored_.*/u no-unused-vars 34:47 error 'row' is defined but never used. Allowed unused args must match /^_ignored_.*/u no-unused-vars 35:1 error Expected indentation of 2 spaces but found 4 indent 36:1 error Expected indentation of 4 spaces but found 7 indent 37:1 error Expected indentation of 2 spaces but found 4 indent 38:1 error Expected indentation of 4 spaces but found 7 indent 39:1 error Expected indentation of 2 spaces but found 4 indent 556:1 error Expected indentation of 14 spaces but found 16 indent 557:1 error Expected indentation of 14 spaces but found 16 indent ``` ### Why are the changes needed? To recover the build ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually tested: ```bash ./dev/lint-js lint-js checks passed. ``` Closes #32541 from HyukjinKwon/SPARK-34764-followup. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
…o (floating point types)
### What changes were proposed in this pull request?
Generally, we would expect that x = y => hash( x ) = hash( y ). However +-0 hash to different values for floating point types.
```
scala> spark.sql("select hash(cast('0.0' as double)), hash(cast('-0.0' as double))").show
+-------------------------+--------------------------+
|hash(CAST(0.0 AS DOUBLE))|hash(CAST(-0.0 AS DOUBLE))|
+-------------------------+--------------------------+
| -1670924195| -853646085|
+-------------------------+--------------------------+
scala> spark.sql("select cast('0.0' as double) == cast('-0.0' as double)").show
+--------------------------------------------+
|(CAST(0.0 AS DOUBLE) = CAST(-0.0 AS DOUBLE))|
+--------------------------------------------+
| true|
+--------------------------------------------+
```
Here is an extract from IEEE 754:
> The two zeros are distinguishable arithmetically only by either division-byzero ( producing appropriately signed infinities ) or else by the CopySign function recommended by IEEE 754 /854. Infinities, SNaNs, NaNs and Subnormal numbers necessitate four more special cases
From this, I deduce that the hash function must produce the same result for 0 and -0.
### Why are the changes needed?
It is a correctness issue
### Does this PR introduce _any_ user-facing change?
This changes only affect to the hash function applied to -0 value in float and double types
### How was this patch tested?
Unit testing and manual testing
Closes #32496 from planga82/feature/spark35207_hashnegativezero.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? Add toc tag on monitoring.md ### Why are the changes needed? fix doc ### Does this PR introduce _any_ user-facing change? yes, the table of content of the monitoring page will be shown on the official doc site. ### How was this patch tested? pass GA doc build Closes #32545 from yaooqinn/minor. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request? Refine comment in `CacheManager`. ### Why are the changes needed? Avoid misleading developer. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Not needed. Closes #32543 from ulysses-you/SPARK-35332-FOLLOWUP. Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request? make these threads easier to identify in thread dumps ### Why are the changes needed? make these threads easier to identify in thread dumps ### Does this PR introduce _any_ user-facing change? yes. Driver thread dumps will show the timers with pretty names ### How was this patch tested? verified locally Closes #32549 from yaooqinn/SPARK-35404. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
… function in SparkFunctionSuite ### What changes were proposed in this pull request? Add a common functions `getWorkspaceFilePath` (which prefixed with spark home) to `SparkFunctionSuite`, and applies these the function to where they're extracted from. ### Why are the changes needed? Spark sql has test suites to read resources when running tests. The way of getting the path of resources is commonly used in different suites. We can extract them into a function to ease the code maintenance. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass existing tests. Closes #32315 from Ngone51/extract-common-file-path. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… information about K8s client mode support ### What changes were proposed in this pull request? [Submitting Applications doc](https://spark.apache.org/docs/latest/submitting-applications.html#master-urls) has outdated information about K8s client mode support. It still says "Client mode is currently unsupported and will be supported in future releases".  Whereas it's already supported and [Running Spark on Kubernetes doc](https://spark.apache.org/docs/latest/running-on-kubernetes.html#client-mode) says that it's supported started from 2.4.0 and has all needed information.  Changes:  JIRA: https://issues.apache.org/jira/browse/SPARK-35405 ### Why are the changes needed? Outdated information in the doc is misleading ### Does this PR introduce _any_ user-facing change? Documentation changes ### How was this patch tested? Documentation changes Closes #32551 from o-shevchenko/SPARK-35405. Authored-by: Oleksandr Shevchenko <oleksandr.shevchenko@datarobot.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
{kind=link}
{kind=link}
…voke` ### What changes were proposed in this pull request? Move hash map lookup operation out of `InvokeLike.invoke` since it doesn't depend on the input. ### Why are the changes needed? We shouldn't need to look up the hash map for every input row evaluated by `InvokeLike.invoke` since it doesn't depend on input. This could speed up the performance a bit. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #32532 from sunchao/SPARK-35384-follow-up. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
Why are the changes needed?
Does this PR introduce any user-facing change?
How was this patch tested?