
Cognition is an open source database processing pipeline. Its purpose is to convert common binary documents such as PDF and Word documents in a relational database into a common representation such as XHTML, and optionally modify them in a customisable manner (For example, applying pseudonymisation/anonymisation algorithms on them). Its primary use case is to facilitate electronic health record (EHR) informatics research by converting documents into a common format, and masking strong patient identifiers according to a customisable, approximate string matching & regular expression based algorithm. It can also be used solely for converting binary documents in a database to text, and storing the text in any other (or the same) database. Check out the Wiki pages for step by step instructions.
Informatics research into EHRs is a rapidly growing discipline across the globe, driven by the expanding expectations of technology to drive down the costs of patient care and increase research output. One of the key challenges is enabling researchers, informaticians and data scientists access to large, rich datasets of clinical records, without compromising the information governance policies of care organisations, and ethical guidelines protecting patient confidentiality. Many existing research clinical datasets are unable to provide access to free text, as the potential risks of accidentally or maliciously identifying patients from their notes is too great. In areas such as mental health, this is highly problematic for researchers, as most of the variables of interest are contained within the clinical free-text.
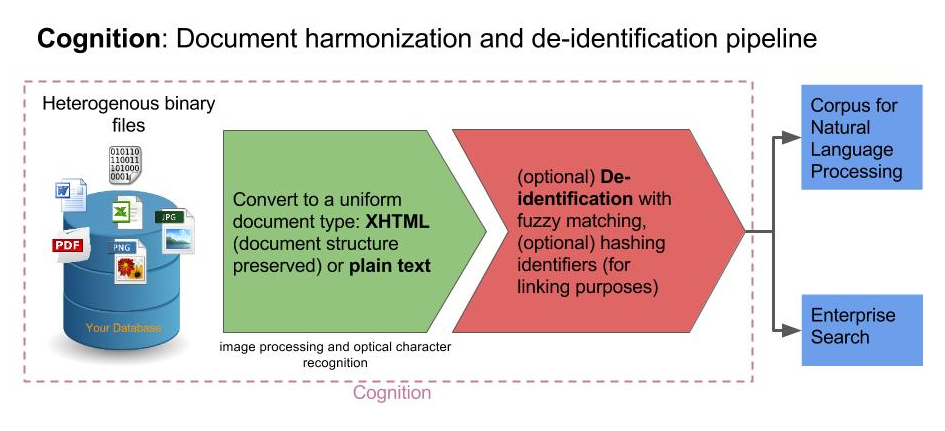
As part of other information governance controls, we propose the Cognition pipeline as a means to mask strong patient identifiers in the clinical text, while retaining as much structure as possible of the original document. The basic components of the pipeline proceed as follows:
- Cognition receives input in the form of a JSON array or from a database table/view. This array contains details of ‘co-ordinates’ from a source database - unique references to binary and character (free text) datatypes that need to be processed.
- Character data types are passed directly to the anonymisation process
- Binary objects such as MS Word documents are converted to XHTML with the Apache Tika library. PDFs undergo OCR with Tesseract (if installed)
- The XHTML files are passed through an anonymisation algorithm (based on regular expressions), to mask strong patient identifiers
- The results are passed back into a database, with co-ordinate references to allow the processed document to be queried in place of the original document
Cognition is designed to be used in conjuction with structured data from a source EHR system. For example, one potential use case is to make available EHR records to researchers while protecting patient anonymity. In order to do this, identifiable patient information needs to be concealed from both the structured and unstructured parts of the database. One system of doing this is for an Information Governance body to 'whitelist' structured parts of the database, and for Cognition to transform the unstructured parts into an acceptable form. Both processes can then be combined to present an anonymised database to epidemiologists and informatics researchers.

###Supported commands:
Process coordinates from file: java -jar DNCPipeline.jar --createMode --file=coordinates.json
Process coordinates from a DB table/view: java -jar DNCPipeline.jar --createMode --coordinatesFromDB
Run a coordinator web server for horizontal scaling: java -jar DNCPipeline.jar --coordinator --chunkSize=1000
Run a client that requests coordinates from server: java -jar DNCPipeline.jar --client --server=http://url_to_server --cognitionName=Computer01
Please see the Wiki pages for details.
###Build Instructions: You can download the latest binary distribution from the release page. To use it, unzip the downloaded distribution, and apply the configurations as described in what follows.
To build from source, ensure Maven is installed and navigate to the Cognition-DNC directory:
mvn clean package
This will produce a .jar executable file in the following directory
pipeline/target
####Configuration:
The following directory contains all of the files needed to configure Cognition:
pipeline/target/config
#####Database Connection
Edit
pipeline/target/config/config.properties
so that the source database settings point to the source database where the data is, and the target database settings point to database where you would like the results to be stored.
# SOURCE DATABASE SETTINGS
sourceJdbcPath = jdbc:jtds:sqlserver://127.0.0.1;databaseName=dbName
sourceJdbcDriver = net.sourceforge.jtds.jdbc.Driver
sourceDbUsername = username
sourceDbPassword = password
# TARGET DATABASE SETTINGS
targetJdbcPath = jdbc:jtds:sqlserver://127.0.0.1;databaseName=dbName
targetJdbcDriver = net.sourceforge.jtds.jdbc.Driver
targetDbUsername = username
targetDbPassword = password
#####Query configuration
Edit pipeline/target/config/queries/sqlserver-pipeline-named-queries.hbm.xml so it respects your schema and patient model. For example, the following assumes that you have a patient_name table in the target DB with the patient key = “Patient_ID”, the patient forename = “Forename”, and the patient surname = “Surname”:
<sql-query name="getPatientNames">
select Forename, Surname from patient_name where Patient_ID = :patientId
</sql-query>Cognition currently has support for the following common identifiers, but these are easily expandable to meet other requirements:
Identifier|
----------|
NHS numbers|
Date of Births|
First Names|
Last Names|
Addresses|
Post Codes|
Phone numbers|
#####Masking Algorithm Customisation
Finally, optionally edit the files in pipeline/target/config/anonymisation to reflect the regular expressions you want to use to mask the identifiers. For example, you might want to add an expression to mask dates of birth in the format
yyyy.MM.dd
To do this, simply add a new json object to the json array in the dateOfBirthRules.vm file, such as
{"regexp": "(?i)${TimeUtil.getFormattedDate($patient.getDateOfBirth(), 'yyyy.MM.dd')}", "placeHolder" : "DDDDD"}By default, Cognition-DNC comes with some rules to pseudonymise common patterns and approximately matching patterns.
####Usage:
Once the configuration is complete, the only input Cognition requires is a json file of database coordinates that it should process, This can be generated any number of ways, but check out our CognitionJobMaker project for a suggestion.
An example coordinates.json contains the following text:
[
{"sourceTable":"PatientBinaryDocs","pkColumnName":"ID","patientId":1,
"type":"binary","idInSourceTable":43,"sourceColumn":"BinaryContent"},
{"sourceTable":"PatientPlainTextDocs","pkColumnName":"ID","patientId":2,
"type":"text","idInSourceTable":21,"sourceColumn":"TextContent"}
]This file specifies two work coordinates. The first coordinate points to a binary file to be converted and anonymised.
| JSON Key | JSON Value |
|---|---|
| sourceTable | the name of the table of the target object |
| pkColumnName | the primary key name of the table of the target object |
| patientId | the primary key of the patient (used to gather patient specific identifiers) |
| type | either binary or text |
| idInSourceTable | the primary key value of the target object |
| sourceColumn | the name of the column that the target object is in |
The second coordinate points to a plain text type to be anonymised. Cognition can then be executed with the following command:
java -jar /path/to/jar/file.jar --createMode --file=coordinates.json
That’s it! If all has gone well, you should see rich formated XHTML strings representing the converted (and optionally anonymised) documents appearing in your target table.
If you’re interested in/need help with using our Cognition pipeline, please get in touch ismail.e.kartoglu@kcl.ac.uk (developer), caroline.johnston@kcl.ac.uk, amos.folarin@kcl.ac.uk, richard.r.jackson@kcl.ac.uk, richard.j.dobson@kcl.ac.uk