はてブ記事を用いた興味分析のデータの準備のためのスクリプトです.
はてブRSSファイルに対して,そのそれぞれのWebページについて本文抽出と形態素解析をし,
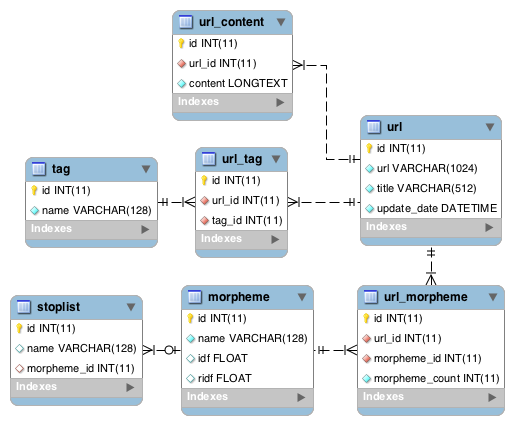
その結果をMySQLのDBに登録します.結果,次のようなDB(MySQL)状態が出来上がります.
MacOSX環境にてmysql, mecab, python, pip, rubyが事前にインストールされていることを前提とします.
-
Cコードのコンパイル
$ cd scripts $ gcc-4.8 `mysql_config --include` `mecab-config --cflags` parse_web_content_to_morpheme.cpp `mysql_config --libs` `mecab-config --libs` -fopenmp -o parse_web_content_to_morpheme.o
gcc-4.8がインストールされていない場合はインストールする。
$ brew tap homebrew/versions $ brew install gcc48
-
pdftotextコマンドを制限解除してインストール
$ wget ftp://ftp.foolabs.com/pub/xpdf/xpdf-3.04.tar.gz $ tar zxvf xpdf-3.04.tar.gz $ cd xpdf-3.04 $ ./configure $ vim xpdf/pdftotext.cc 次のようにコメントアウト(191行目〜197行目あたり) // check for copy permission // if (!doc->okToCopy()) { // error(errNotAllowed, -1, // "Copying of text from this document is not allowed."); // exitCode = 3; // goto err2; // } $ make $ sudo make install
$ pdftotextコマンドが呼び出せることを確認する。
詳細はPDF文書からテキストを抽出するを参照また、以下の手順により、日本語を抽出できるようにする。
$ wget ftp://ftp.foolabs.com/pub/xpdf/xpdf-japanese.tar.gz $ tar zxvf xpdf-japanese.tar.gz $ mkdir -p /usr/local/share/xpdf/ $ mv xpdf-japanese /usr/local/share/xpdf/japanese $ vim /usr/local/etc/xpdfrc # コメントを外す textEncoding UTF-8 ... # 追記 cidToUnicode Adobe-Japan1 /usr/local/share/xpdf/japanese/Adobe-Japan1.cidToUnicode unicodeMap ISO-2022-JP /usr/local/share/xpdf/japanese/ISO-2022-JP.unicodeMap unicodeMap EUC-JP /usr/local/share/xpdf/japanese/EUC-JP.unicodeMap unicodeMap Shift-JIS /usr/local/share/xpdf/japanese/Shift-JIS.unicodeMap cMapDir Adobe-Japan1 /usr/local/share/xpdf/japanese/CMap toUnicodeDir /usr/local/share/xpdf/japanese/CMap
$ pdftotext [日本語を含むPDF].pdf -を実行し、日本語が適切に出力される確認する。
詳細はxpdfを使ってPDFから日本語抽出を参照 -
pythonライブラリ(MySQL-python,NumPy,NLTK,MeCab,feedparser)のインストール
$ sudo pip install MySQL-python $ sudo pip install -U numpy $ sudo pip install -U nltk # エラーになるなら https://github.com/nltk/nltk/issues/824 →$ pip install setuptools==9.1 $ curl -O http://mecab.googlecode.com/files/mecab-python-0.996.tar.gz $ sudo pip install mecab-python-0.996.tar.gz $ sudo pip install feedparser -
MySQLのユーザー登録・データベースへの権限付与
$ mysql -u root -p
> CREATE USER 'hatena'@'localhost' IDENTIFIED BY 'hatena'; > GRANT ALL PRIVILEGES ON hatena_bookmark.* TO 'hatena'@'localhost' IDENTIFIED BY 'hatena'; > CREATE DATABASE hatena_bookmark CHARACTER SET utf8;
-
はてブRSSファイルのダウンロード
1. はてブのページを開く 2. 画面上部の[設定] → [データ管理]を開く 3. [RSS 1.0形式でダウンロード]を右クリックして「別名でリンク先を保存」し, 「./scripts/data/hatena_bookmark_rss.htm」に保存 -
ストップワードの修正(任意)
$ vim scripts/data/stoplist.dat
デフォルトのストップワードの詳細はHTML特殊文字を含めたストップワードを参照
-
実行
$ cd scripts $ ./main.sh
- urlテーブル(URLを保持)
| カラム名 | 内容 |
|---|---|
| id | ID |
| url | URL |
| title | ページタイトル |
| update_date | 更新日時 |
- tagテーブル(タグを保持)
| カラム名 | 内容 |
|---|---|
| id | ID |
| name | タグ名 |
- morphemeテーブル(webページの本文に含まれる形態素,IDFを保持)
| カラム名 | 内容 |
|---|---|
| id | ID |
| name | 形態素名 |
| idf | IDF(この形態素が存在するwebページ数) |
- stoplistテーブル(ストップワード,形態素とのマッピングを保持)
| カラム名 | 内容 |
|---|---|
| id | ID |
| name | ストップワード名 |
| morpheme_id | morphemeテーブルのid |
- url_contentテーブル(webページの本文情報を保持)
| カラム名 | 内容 |
|---|---|
| id | ID |
| url_id | urlテーブルのid |
| content | webページurl_idの本文情報 |
- url_tagテーブル(URLとタグのマッピングを保持)
| カラム名 | 内容 |
|---|---|
| id | ID |
| url_id | urlテーブルのid |
| tag_id | tagテーブルのid |
- url_morphemeテーブル(URLと形態素のマッピング,TFを保持)
| カラム名 | 内容 |
|---|---|
| id | ID |
| url_id | urlテーブルのid |
| morpheme_id | morphemeテーブルのid |
| morpheme_count | TF(webページurl_idにおける形態素morpheme_idの出現回数) |
補足
# URLを保持
create table url (
id int(11) not null auto_increment,
url varchar(1024) not null,
title varchar(512) not null,
update_date datetime not null,
primary key(id) );
# タグを保持
create table url_tag (
id int(11) not null auto_increment,
url_id int(11) not null,
tag_id int(11) not null,
primary key (id) );
# URLとユーザタグのマッピングを保持
create table url_tag (
id int(11) not null auto_increment,
url_id int(11) not null,
tag_id int(11) not null,
primary key (id) );
# webページの本文情報を保持
create table url_content (
id int(11) not null auto_increment,
url_id int(11) not null,
content longtext not null,
primary key (id) );
# webページに含まれる形態素, IDF(形態素の存在ドキュメント数),残差IDFを保持
create table morpheme (
id int(11) not null auto_increment,
name varchar(128) not null,
idf float,
ridf float,
primary key (id) );
# URLと形態素のマッピング,TF(形態素の出現回数)を保持
create table url_morpheme (
id int(11) not null auto_increment,
url_id int(11) not null,
morpheme_id int(11) not null,
morpheme_count int(11) not null,
primary key (id) );
# stoplistを保持
create table stoplist (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(128) NOT NULL,
morpheme_id int(11),
PRIMARY KEY (id) )extractcontent.rbはBSDライセンスにて配布されたコードであり,Nakatani Shuyoさんが著作権を保持しており,無保証です.