- Ubuntu: 18.04
- Python: 3.7.0
- Database: Kafka
- Collecting Logs: Fluent-bit
$ sudo docker-compose up --build -d
- Kafka Tool: https://www.kafkatool.com/
- Copy File
$ cp ./supervisor/supervisor_kafka.conf /etc/
- Start Supervisor
$ supervisord -c /etc/supervisord_kafka.conf
$ cd fluent-bit
$ sudo docker-compose up --build -d

-
leader & follower:
- 通常只有leader對外提供服務,follower只是被動地追隨leader狀態,保持與其同步。存在的唯一價值就是充當leader的候補。
-
ISR
- 與leader replica保持同步的replica集合。
- Kafka為partitioner動態維護一個replica集合。該集合中所有的replica儲存的訊息記錄都與leader replica保持同步狀態。只有這個集合中的replica才能被選舉為leader,也只有該集合中所有replica都接收到同一筆訊息,kafka才會將該訊息標誌為已傳送狀態。
-
replica
- 分為兩種:領導者備份和追隨者備份。
- 追隨者備份是不能提供服務給用戶端的(例如訊息寫入或訊息消費請求)。它只是被動地向leader replica取得資料,一旦leader replica所在的broker當機,Kafka會從剩餘的replica中選列出新的leader繼續提供服務。
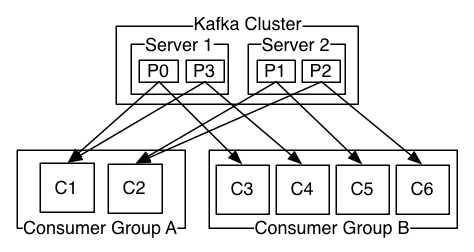
-
消費者組(Consumer Group):
- 其下可以有一個或多個consumer實例。一個consumer實例,可以是一個執行緒,也可以是執行在其他機器上的處理程序。
- group.id 唯一標示一個consumer group
- 對某個group而言,訂閱topic每個分區只能分配給該group下的consumer實例
-
位移(offset): 每個consumer實例都會為它所消費的分區維護屬於自己的位置資訊來記錄目前消費了幾筆訊息,並且定時向Kafka傳送offset訊息,所有offset都儲存於__consumer_offsets的topic中,默認有50個分區,以因應寫入負載(zookeeper只是協調服務元件,不適合作為位移資訊的儲存元件。)
| 參數 | 說明 |
|---|---|
| session.timeout.ms | Coordinate檢測Consumer當機時間,進一步更快地開啟rebalance,避免更大的consumer lag。預設值為10秒。 |
| max.poll.interbal.ms | Consumer處理邏輯最大時間,設定比訊息平均處理時間稍大的值 |
| auto.offset.reset | 預設值為latest |
| fetch.max.bytes | Consumer端單次取得資料的最大位元組數。若實際業務訊息很大,則必須設定該參數為一個較大的值。 |
| enable.auto.commit | 指定consumer是否自動傳送offset。 |
| auto.commit.interval.ms | 傳遞offset的間隔時間,預設為5秒。 |
| max.poll.records | 控制單次poll呼叫傳回的最大訊息數。 |
- 訊息發布語義保障
- 最多一次(at most once): 訊息可能遺失,但不會被重複處理。
- 最少一次(at least one): 傳遞offset訊息,與消費無法在同一個交易中完成,訊息不會被遺失,但會被重複處理。
- 精確一次(exactly one): 訊息一定會被處理並且只會被處理一次。
- 組成員發生變更,例如新成員加入組、已有的成員離組,或發生當機.
- 組訂閱topic的分區數發生變動,例如使用命令列指令增加了訂閱topic的分區數。
- rebalance策略: (1) 加入組:所有的consumer向coordinate發送JoinGroup請求。當收集完全部的JoinGroup請求後,coordinate從中選擇一個consumer擔任group的leader,並把所有成員資訊以及他們的訂閱資訊發送給leader。 (2) 同步更新分配方案:由leader制定分配方案,即根據分配策略決定每個consumer負責哪些topic的哪些分區。一旦完成分配,leader會把分配方案封裝進SyncGroup請求平行處理送給coordinate。
| 優點 | 缺點 | |
|---|---|---|
| 每個執行緒維護專屬KafkaConsumer | 實現簡單;快速實現;方便位移管理;容易維護分區間的訊息消費順序 | Socket連接負擔大;consumer數受限於topic分區數,擴充性差;broker端處理負載高(發往boker請求數增加) |
| 全域Consumer + 多woker執行緒 | 可獨立擴充consumer數和woker數,伸縮性佳 | 難於維護分區內的訊息管理;woker執行緒例外可能導致消費資料遺失 |

-
ProducerRecord:
- 由topic, partition, key, value 和 timestamp組成。
- 建立訊息物件的時候直接指定要發送的分區,這樣producer發送該訊息時可以直接發送到指定分區,不用先透過patitioner計算目標分區
-
RecordMetadata:
- 傳回給用戶端的訊息的中繼資料資訊包含: offset, timestmap topic, serializedKeySize和serializedValueSize
-
工作流程:
- 使用者首先建制待發送的訊息物件ProducerRecord,然後呼叫KafkaProducer#send方法進行發送。KafkaProducer接受到訊息後首先序列化,然後結合本機快取的中繼資料一起發送給partitioner去確定目標分區,最後追加寫入記憶體中的訊息緩衝集區(預設為32MB)。此時KafkaProducer#send方法成功傳回。
- 補充send執行緒: (1) 不斷輪詢緩衝區尋找已做好發送準備的分區。 (2) 將輪詢獲得的各個batch按照目標分區所在的leader broker進行分組。 (3) 將分組後的batch透過底層建立的Socket連接發送給各個broker。 (4) 等待伺服器發送response回來。
| 參數 | 說明 |
|---|---|
| acks | 控制producer生產訊息的持久性。當producer發送一筆訊息給Kafka叢集時,這筆訊息會被發送到指定topic分區leader所在的broker上,producer等待該leader broker傳回訊息的寫入結果,已確定訊息被成功發送。 |
| buffer.memory | 指定快取訊息的緩衝區大小,預設為32MB。 |
| request.timeout.ms | 當prodcuer發送請求給broker後,其需要在規定的時間範圍內將處理的結果返回給producer。預設為30秒。如果逾時,則會拋出TimeoutException例外交給使用者處理。 |
| max.request.size | 控制producer發送請求的大小。 |
| batch_size | 一個batch封裝訊息的大小;分配過大,會給記憶體帶來相當大的壓力;分配過小,導致傳輸量過低。預設值為16KB。 |
| linger_ms | 控制訊息發送延遲時間 |
| 說明 | 優點 | 缺點 | |
|---|---|---|---|
| 單KafkaProducer實例 | 所有執行緒共用一個KafkaProducer實例 | 實現簡單,效能好 | 所有執行緒共用一個記憶體緩衝區,可能需要較多的記憶體;一旦Producer某個執行緒當機導致KafkaProducer實例被破壞,則所有使用者執行緒都無法執行 |
| 多KafkaProducer實例 | 每個執行緒維護自己專屬的KafkaProducer實例 | 每個使用者執行緒擁有專屬的KafkaProducer實例、緩衝區空間以及一組對應的設定參數,可以進行細粒度的最佳化;單一KafkaProducer當機不會影響其他producer執行緒工作 | 需要較大的記憶體分配負擔 |
- acks=all 必須所有follower回應了發送訊息才能被認為傳送成功。
- 使用帶有callback機制的send
| 參數 | 說明 |
|---|---|
| log.dirs | 指定Kafka持久化訊息的目錄。指定多個目錄的做法通常是被推薦的,因為Kafka可以把負載均勻地分配到每個目錄下。 |
| delete.topic.enabled | 是否允許Kafka刪除topic。 |
| log.retention.{hours | minutes |
| max.request.size | 控制producer發送請求的大小。 |
| message.max.bytes | Kafka broker最大能夠接受的訊息大小,預設是997KB。 |
| num.network.threads | 控制broker在後台用於處理網路請求的執行緒數。預設是3。 |
-
最佳化傳輸量
-
producer端:
- 適當增加batch.size,例如100~512KB。
- 適當增加linger.ms,例如10~100毫秒。
- 設定compression.type=lz4
- acks=0 或 1。
- retries = 0
- 如多執行緒共用producer或分區數很多,增加buffer.memory。
-
consumer端:
- 採用多consumer實例。
- 增加fetch.min.bytes,例如10000
-
-
最佳化延遲時間
- 說明:
- producer端: 訊息發送的延遲時間,即Producer發送PRODUCE請求到broker端傳回請求response的時間間隔。
- consumer端: consumer 發送 FETCH請求到broker端傳回請求response的時間間隔。
- producer端:(如果使用者對於延遲時間具有比較高的要求,但卻容忍偶發的訊息遺失)
- 設定linger.ms=0
- 設定compression.type=none
- 設定ack=1 或0
- consumer端:
- 設定fetch.min.bytes=1
- 說明:
-
最佳化持久性
- 定義了kafka從集中訊息不容易遺失的程度。通常由容錯來實現,也就是備份機制,即使單一broker當機,資料依然是可用的。
- producer端:
- 設定acks = all
- 設定retries為一個較大的值。例如10~30
- consumer端:
- 設定auto.commit.enable=False
- 訊息消費成功後呼叫commutSync傳送位移。