Dogen v1.0.30, "Estádio Joaquim Morais"

Municipal stadium in Moçamedes, Namibe, Angola. (C) 2020 Angop.
Introduction
Happy new year! The first release of the year is a bit of a bumper one: we finally managed to add support for org-mode, and transitioned all of Dogen to it. It was a mammoth effort, consuming the entirety of the holiday season, but it is refreshing to finally be able to add significant user facing features again. Alas, this is also a bit of a bitter-sweet release because we have more or less run out of coding time, and need to redirect our efforts towards writing the PhD thesis. On the plus side, the architecture is now up-to-date with the conceptual model, mostly, and the bits that aren't are fairly straightforward (famous last words). And this is nothing new; Dogen development has always oscillated between theory and practice. If you recall, a couple of years ago we had to take a nine-month coding break to learn about the theoretical underpinnings of MDE and then resumed coding on Sprint 8 for what turned out to be a 22-sprint-long marathon (pun intended), where we tried to apply all that was learned to the code base. Sprint 30 brings this long cycle to a close, and begins a new one; though, this time round, we are hoping for far swifter travels around the literature. But lets not get lost talking about the future, and focus instead on the release at hand. And what a release it was.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail.
Video 1: Sprint 30 Demo.
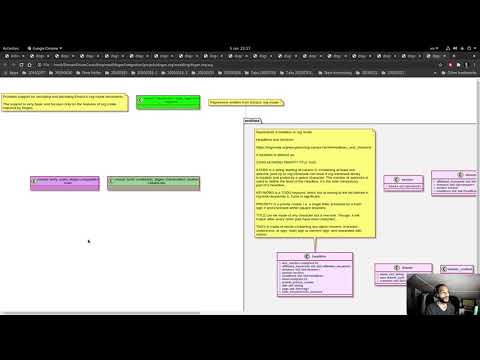
Org-mode support
A target that we've been chasing for the longest time is the ability to create models using org-mode. We use org-mode (and emacs) for pretty much everything in Dogen, such time keeping and task management - it's how we manage our product and sprint backlogs, for one - and we'll soon be using it to write academic papers too. It's just an amazing tool with a great tooling ecosystem, so it seemed only natural to try and see if we could make use of it for modeling too. Now, even though we are very comfortable with org-mode, this is not a decision to be taken lightly because we've been using Dia since Dogen's inception, over eight years ago.
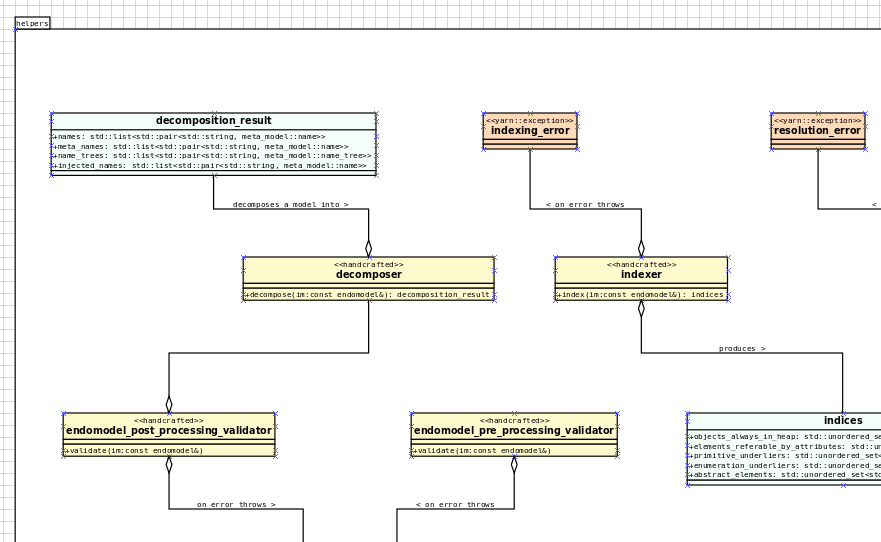
Figure 1: Dia diagram for a Dogen model with the introduction of colouring, Dogen v1.0.06
As much as we profoundly love Dia, the truth is we've had concerns about relying on it too much due to its somewhat sparse maintenance, with the last release happening some nine years ago. What's more pressing is that Dia relies on an old version of GTK, meaning it could get pulled from distributions at any time; we've already had a similar experience with Gnome Referencer, which wasn't at all pleasant. In addition, there are a number of "papercuts" that are mildly annoying, if livable, and which will probably not be addressed; we've curated a list of such issues, in the hope of one day fixing these problems upstream, but that day never came. The direction of travel for the maintenance is also not entirely aligned with our needs. For example, we recently saw the removal of python support in Dia - at least in the version which ships with Debian - a feature in which we relied upon heavily, and intended to do more so in the future. All of this to say that we've had a number of ongoing worries that motivated our decision to move away from Dia. However, I don't want to sound too negative here - and please don't take any of this as a criticism to Dia or its developers. Dia is an absolutely brilliant tool, and we have used it for over two decades; It is great at what it does, and we'll continue to use it for free modeling. Nonetheless, it has become increasingly clear that the directions of Dia and Dogen have started to diverge over the last few years, and we could not ignore that. I'd like to take this opportunity to give a huge thanks to all of those involved in Dia (past and present); they have certainly created an amazing tool that stood the test of time. Also, although we are moving away from Dia use in mainline Dogen, we will continue to support the Dia codec and we have tests to ensure that the current set of features will continue to work.
That's that for the rationale for moving away from Dia. But why org-mode? We came up with a nice laundry list of reasons:
- "Natural" Representation: org-mode documents are trees, with arbitrary nesting, which makes it a good candidate to represent the nesting of namespaces and classes. It's just a natural representation for structural information.
- Emacs tooling: within the org-mode document we have full access to Emacs features. For example, we have spell checkers, regular copy-and-pasting, etc. This greatly simplifies the management of models. Since we already use Emacs for everything else in the development process, this makes the process even more fluid.
- Universality: org-mode is fairly universal, with support in Visual Studio Code, Atom and even Vim (for more details, see Get started with Org mode without Emacs). None of these implementations are as good as Emacs, of course - not that we are biased, or anything - but they are sufficient to at least allow for basic model editing. And installing a simple plugin in your editor of choice is much easier than having to learn a whole new tool.
- "Plainer" plain-text: org-mode documents are regular text files, and thus easy to life-cycle in a similar fashion to code; for example, one can version control and diff these documents very easily. Now, we did have Dia's files in uncompressed XML, bringing some of these advantages, but due to the verbosity of XML it was very hard to see the wood for the trees. Lots of lines would change every time we touched a model element - and I literally mean "touch" - making it difficult to understand the nature of the change. Bisection for example was not helped by this.
- Models as documentation: Dogen aims to take the approach of "Literate Modeling" described in papers such as Literate Modelling - Capturing Business Knowledge with the UML. It was clear from the start that a tool like Dia would not be able to capture the wealth of information we intended to add to the models. Org-mode on the other hand is the ideal format to bring disparate types of information together (see Replacing Jupyter with Orgmode for an example of the sort of thing we have in mind).
- Integration with org-babel: Since models contain fragments of source code, org-mode's support for working with source code will come in handy. This will be really useful straight away on the handling of text templates, but even more so in the future when we add support for code merging.
Over the past few sprints we've been carrying out a fair bit of experimentation on the side, generating org-mode files from the existing Dia models; it was mostly an exercise in feasibility to see if we could encode all of the required information in a comprehensible manner within the org-mode document. These efforts convinced us that this was a sensible approach, so this sprint we focused on adding end-to-end support for org-mode. This entailed reading org-mode documents, and using them to generate the exact same code as we had from Dia. Unfortunately, though C++ support for org-mode exists, we could not find any suitable library for integration in Dogen. So we decided to write a simple parser for org-mode documents. This isn't a "generic parser" by any means, so if you throw invalid documents at it, do expect it to blow up unceremonially. Figure 2 shows the dogen.org model represented as a org-mode document.

Figure 2: dogen.org model in the org-mode representation.
We tried as much as possible to leverage native org-mode syntax, for example by using tags and property drawers to encode Dogen information. However, this is clearly a first pass and many of the decisions may not survive scrutiny. As always, we need to have a great deal of experience editing models to see what works and what does not, and it's likely we'll end up changing the markup in the future. Nonetheless, the guiding principle is to follow the "spirit" of org-mode, trying to make the documents look like "regular" org-mode documents as much as possible. One advantage of this approach is that the existing tooling for org-mode can then be used with Dogen models - for example, org-roam, org-ref, org-brain, org-tanglesync and many more. Sadly, one feature which we did not manage to achieve was the use of stitch-mode in the org-babel blocks. It appears there is some kind of incompatibility between org-mode and polymode; more investigation is required, such as for instance playing with the interestingly named poly-org. As Figure 3 demonstrates, the stitch templates are at present marked as fundamental, but users can activate stitch mode when editing the fragment.

Figure 3: Stitch template in dogen.text model.
In order to make our life easier, we implemented conversion support for org-mode:
$ head dogen.cli.dia
<?xml version="1.0" encoding="UTF-8"?>
<dia:diagram xmlns:dia="http://www.lysator.liu.se/~alla/dia/">
<dia:diagramdata>
<dia:attribute name="background">
<dia:color val="#ffffffff"/>
</dia:attribute>
<dia:attribute name="pagebreak">
<dia:color val="#000099ff"/>
</dia:attribute>
<dia:attribute name="paper">
$ dogen.cli convert --source dogen.cli.dia --destination dogen.cli.org
$ head dogen.cli.org
#+title: dogen.cli
#+options: <:nil c:nil todo:nil ^:nil d:nil date:nil author:nil
#+tags: { element(e) attribute(a) module(m) }
:PROPERTIES:
:masd.codec.dia.comment: true
:masd.codec.model_modules: dogen.cli
:masd.codec.input_technical_space: cpp
:masd.codec.reference: cpp.builtins
:masd.codec.reference: cpp.std
:masd.codec.reference: cpp.boost
This feature was mainly added for our benefit, but it may also be useful for any users that wish to update their models from Dia to org-mode. We made use of conversion to migrate all of the Dogen core models into org-mode, including the library models - though these required a bit of manual finessing to get them into the right shape. We also performed a number of modeling tasks in the sprint using the new format and the work proceeded as expected; see the below sections for links to a video series on this subject. However, one thing we did notice is that we missed the ability to visualise models as UML diagrams. And that gives us a nice segway into the second major story of this sprint.
Initial PlantUML support
Whilst the advantages of modeling using textual languages over graphical languages are patently obvious, the truth is the modeling process requires both views in order to progress smoothly. Maybe its just me but I get a lot of information about a system very quickly just by looking at a well-curated class diagram. It is especially so when one does not touch a sub-system for extended periods of time; it only takes a few minutes to observe and absorb the structure of the sub-system by looking carefully at its class diagram. In Dogen, we have relied on this since the beginning, particularly because we need to context-switch in-and-out so often. With the move to org-mode we suddenly found ourselves unable to do so, and it was quite disorienting. So we decided to carry out yet another little experiment: to add basic support for PlantUML. PlantUML is a textual notation that describes pretty much all types of UML diagrams, as well as a tool that converts files in that notation over to a graphical representation. The syntax is very simple and intuitive. Take for example one of the samples they supply:
@startuml
Class11 <|.. Class12
Class13 --> Class14
Class15 ..> Class16
Class17 ..|> Class18
Class19 <--* Class20
@endumlThis very simple and compact notation produces the rather wonderful UML class diagram:
Figure 4: UML Class Diagram generated from PlantUML sample. Source: PlantUML site.

Given the notation is so straightforward, we decided to create a codec that outputs PlantUML documents, which can then be processed by their tool. To do so, simply convert the model:
$ dogen.cli convert --source dogen.cli.org --destination dogen.cli.plantuml
The listing below has a fragment of the output produced by Dogen; it contains the PlantUML representation of the dogen.org model from Figure 2.
@startuml
set namespaceSeparator ::
note as N1
Provides support for encoding and decoding Emacs's org-mode
documents.
The support is very basic and focuses only on the features
of org mode required by Dogen.
end note
namespace entities #F2F2F2 {
class section #F7E5FF {
+{field} blocks std::list<block>
}
class document #F7E5FF {
+{field} affiliated_keywords std::list<affiliated_keyword>
+{field} drawers std::list<drawer>
+{field} section section
+{field} headlines std::list<headline>
}
<snip>You can process it with PlantUML, to produce SVG output (or PNG, etc):
$ plantuml dogen.org.plantuml -tsvg
The SVG output is particularly nice because you can zoom in and out as required. It is also rendered very quickly by the browser, as attested by Figure 5.

Figure 5: dogen.org SVG representation, produced by PlantUML.
While it was fairly straightforward to add basic PlantUML support, the diagrams are still quite far from the nice orderly representations we used to have with Dia. They are definitely an improvement on not having any visual representation at all, mind you, but of course given our OCD nature, we feel compeled to try to get them as close as possible to what we had before. In order to do so we will have to do some re-engineering of the codec model and bring in some of the information that lives in the logical model. In particular:
- generalisation parsing so that we can depict these relationships in the diagram; this is actually quite tricky because some of the information may live on profiles.
- some level of resolution: all intra-model types must be resolved in order to support associations.
These changes will have to remain on the work stack for the future. For now the diagrams are sufficient to get us going, as Figures 5 and 6 demonstrate. Finally, its also worthwhile pointing out that PlantUML has great integration with Emacs and with org-mode in particular, so in the future it is entirely possible we could "inject" a graphical representation of model elements into the model itself. Clearly, there are many possibilities to explore here, but for now these remain firmly archived in the "future directions" section of the product backlog.

Figure 6: Fragment of the PlantUML representation of dogen.profiles model.
Add support for reference directories
With this release we also managed to add another feature which we have been pining for: the ability to have models in multiple directories. In the past we automatically detected the library directory, and we also checked for models in the target directory; due to this it was not possible to have models in any other directory. With this release, a new command line parameter was added: --reference-directory.
$ dogen.cli generate --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Displaying options specific to the generate command.
For global options, type --help.
Generation:
-t [ --target ] arg Model to generate code for, in any of the
supported formats.
-o [ --output-directory ] arg Output directory for the generated code.
Defaults to the current working directory.
-r [ --reference-directory ] arg One or more directories to check for
referenced models.
Users can supply directories containing their models and Dogen will check those directories when resolving references. This means you no longer need to keep all your models in a big jumble on the same directory, but should instead start to keep them together with the code they generate. We used this feature in Dogen to separate the old dogen.models directory, and created a number of modeling directories where all the content related to modeling for a given component will be placed. For example, see the dogen.org modeling directory:
$ ls -l
total 76
-rw-r--r-- 1 marco marco 3527 2021-01-02 12:37 CMakeLists.txt
-rw-r--r-- 1 marco marco 10360 2021-01-03 17:36 dogen.org.org
-rw-r--r-- 1 marco marco 3881 2021-01-03 13:53 dogen.org.plantuml
-rw-r--r-- 1 marco marco 60120 2021-01-03 13:54 dogen.org.svg
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Milestones and Ephemerides
This sprint saw the 13,000th commit to Dogen.
Figure 7: Commit number 13,000th was made to the Dogen GitHub repository.
Significant Internal Stories
This sprint had two key goals, both of which were achieved: org-mode and PlantUML support. These were described in the user facing stories above. In this section we shall provide more details about how this work was organised, as well as other stories which were not user facing.
Org-mode work
The following stories were required to bring about org-mode support:
- Add support for reading org mode documents: creation of an org-mode parser, as well as a model to represent the types of this domain.
- Add org-mode codec for input: story to plug in the new org-mode parser into the codec framework, from an input perspective.
- Create a model to org transform: output side of the work; the addition of a transform which takes a Dogen model and generates an org-mode document.
- Add tags to org model: originally we tried to infer the element's meta-type by its position (e.g. package, "regular" element, attribute). However, it soon became obvious this was not possible and we ended up having to add org tags to perform this work. A story related to this one was also Assorted improvements to org model, where we sorted out a small number of papercuts with the org documents.
- Consider replacing properties drawer with tables: an attempt to use org-mode tables instead of property drawers to represent meta-data. We had to cancel the effort as we could not get it to work before the end of the sprint.
- Convert library models into org: we spent a fair bit of time in converting all of the JSON models we had on our library into org-mode. The automatic conversion worked fairly well, but it was missing some key bits which had to be added manually.
- Convert reference models into org: similarly to the library models, we had to convert all of Dogen's models into org-mode. This also includes the work for C++ and C# reference models. We managed to use the automatic conversion for all of these, after a fair bit of work on the conversion code.
- Create a "frozen" project: although we were moving away from Dia, we did not want the existing support to degrade. The Dia Dogen models are an exacting test in code generation, which add a lot of value. There has always been an assumption that these would be a significant part of the code generator testing suite, but what we did not anticipate is that we'd move away from using a "core" codec such as Dia. So in order not to lose all of the testing infrastructure we decided to create a "frozen" version of Dogen, which in truth is not completely frozen, but contains a faithful representation across all supported codecs of the Dogen models at that point in time. With Frozen we can guarantee that the JSON and Dia support will not be any worse for all the features used by Dogen at the time the snapshot was taken.
- Remove JSON and Dia models for Dogen: once Frozen was put in place, we decommissioned all of the existing Dia and JSON models within Dogen. This caused a number of breaks which had to be hunted down and fixed.
- Add org-to-org tests and Analysis on org mode round-tripping: we added a "special" type of round-tripping: the org-to-org conversion. This just means we can read an org-mode document and then regenerate it without introducing any differences. It may sound quite tautological, but it has its uses; for example, we can introduce new features to org documents by adding it to the output part of the transform chain and then regenerating all documents. This was useful several times this sprint. It will also be quite useful in the future, when we integrate with external tooling; we will be able to append data to user models without breaking any of the user content (hopefully).
- Inject custom IDs into org documents: we tried not to have an identifier in org-mode documents for each element, but this caused problems when recreating the topology of the document. We had to use our org-to-org transform to inject
custom_id(the org-mode attribute used for this purpose), though some had to be injected manually.
Whitespace handling
Whilst it was introduced in the context of the org-mode, the changes to the handling of whitespace are a veritable epic in its own right. The problem was that in the past we wanted to preserve whitespace as supplied by the user in the original codec model; however, if we did this for org-mode documents, we would end up with very strange looking documents. So instead we decided to trim leading and trailing whitespace for all commentary. It took a while to get it to work such that the generated code had no differences, but this approach now means the org-mode documents look vaguely sensible, as does the generated code. The following stories were involved in adding this feature:
- Move documentation transform to codec model: for some reason we had decided to place the documentation trimming transform in the logical model. This made things a lot more complicated. In this sprint we moved it into the codec model, which greatly simplified the transform.
Stitch templates are consuming whitespace: this was a bit of a wild-goose chase. We thought the templates were some how causing problems with the spacing, but in the end it was just to do with how we trim different assets. Some hackery was required to ensure text templates are correctly terminated with a new line. - Remove leading and trailing new lines from comments: the bulk of the work where we trimmed all commentary.
- Allow spaces in headlines for org mode documents: to make org-mode documents more readable, we decided to allow the use of spaces in headlines. These get translated to underscores as part of the processing. It is possible to disable this translation via the not-particularly-well-named key
masd.codec.preserve_original. This was mainly required for types such asunsigned intand the like.
PlantUML work
There were a couple of stories involved in adding this feature:
- Add PlantUML markup language support: the main story that added the new codec. We also added CMake targets to generate all models.
- Add comments to PlantUML diagrams: with this story we decided to add support for displaying comments in modeling elements. It is somewhat experimental, and its look and feel is not exactly ideal, but it does seem to add some value. More work on the cosmetics is required.
Smaller stories
A number of smaller stories was also worked on:
- Merge dia codec model into main codec model: we finally got rid of the Dia "modelet" that we have been carrying around for a few sprints; all of its code has now been refactored and placed in the
dogen.codecmodel, as it should be. - Split orchestration tests by model and codec: our massive file containing all code generation tests was starting to cause problems, particularly with treemacs and lsp-mode in emacs. This story saw the monster file split into a number of small files, organised by codec and product.
- Add missing provenance details to codec models: whilst trobuleshooting an issue we noticed that the provenance details had not been populated correctly at the codec level. This story addresses this shortcoming and paves the way for GCC-style errors, which will allow users to be taken to the line in the org-document where the issue stems from.
Video series of Dogen coding
This sprint we recorded some videos on the implementation of the org-mode codec, and the subsequent use of these models. The individual videos are listed on Table 2, with a short description. They are also available as a playlist, as per link below.
Video 2: Playlist "MASD - Dogen Coding: Org Codec".
| Video | Description |
|---|---|
| Part 1 | In this part we provide context about the current task and start off by doing some preliminary work setting up the required infrastructure. |
| Part 2 | In this video we review the work done to process org mode documents, and start coding the codec transform. However, we bump into a number of problems. |
| Part 3 | In this video we review the work done to get the org codec to generate files, and analyse the problems we're having at present, likely related to errors processing profiles. |
| Part 4 | In this video we review the work done offline to implement the basic support for reading org-mode documents and start the work to write org mode documents using our org model. |
| Part 6 | In this part we review the round-trip work made to support org mode, and refactor the tags used in org models. We also add support for org custom IDs. |
| Part 7 | Addendum video where we demonstrate the use of the new org mode models in a more expansive manner. |
| Part 8 | In this second addendum we work on the org-to-org transform, solving a number of issues with whitespacing. |
| Part 9 | In this video we try to explore moving away from properties to represent meta-data and using tables instead, but we run into a number of difficulties and end up spending most time fixing bugs related to element provenance. |
Resourcing
As you can see from the lovely spread of colours in the pie chart below (Figure 8), our story-keeping this sprint was much healthier than usual; the biggest story took 24.3% which is also a great sign of health. Our utilisation rate was also the highest since records began, at 70%, and a marked improvement over the measly 35% we clocked last sprint. To be fair, that is mainly an artefact of the holiday season more than anything else, but who are we to complain - one is always happy when the numbers are going in the right direction, regardless of root cause. On the less positive front, we spent around 16.2% on activities that were not related to our core mission - a sizable increase from the 11% last time round, with the main culprit being the 4.5% spent on addressing Emacs issues (including some low-level elisp investigations). On the plus side, we did make a few nice changes to our Emacs setup, which will help with productivity, so its not just sunk costs. Predictably, the circa 84% dedicated to "real work" was dominated by org-mode stories (~54%), with PlantUML coming in at a distant second (7%). All and all, it was a model sprint - if you pardon the pun - from a resourcing perspective.

Figure 8: Cost of stories for sprint 30.
Roadmap
The road map has been working like clockwork for the last few sprints, with us ticking stories off as if it was a mere list - clearly no longer the Oracle of Delphi it once was - and this sprint was no exception. Were we to be able to continue with the same release cadence, the next sprint would no doubt also tick off the next story on our list. Alas, we have ran out of coding time, so Sprint 31 will instead be very long running sprint, with very low utilisation rate. In addition, we won't bother creating sprints when the work is completely dedicated to writing; instead, regular service will resume once the writing comes to an end.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 3. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.30_amd64-applications.deb | dogen_1.0.30_amd64-applications.deb |
| Windows | MSI | DOGEN-1.0.30-Windows-AMD64.msi | DOGEN-1.0.30-Windows-AMD64.msi |
Table 3: Binary packages for Dogen.
Note 1: The Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Note 2: Due to issues with Travis CI, we did not manage to get OSX to build, so and we could not produce a final build for this sprint. The situation with Travis CI is rather uncertain at present so we may remove support for OSX builds altogether next sprint.
Next Sprint
The goals for the next sprint are:
- to implement path and dependencies via PMM.
That's all for this release. Happy Modeling!