Разрабатывая архитектуру приложения на основе ООП парадигмы мы оперируем объектами и методами. И для обеспечения возможности расширения и долгосрочной поддержки такого приложения доменную модель стоит разрабатывать пользуясь подходом application first. То есть сначала мы строим модель на основе классов, затем переносим ее в табличное представление, а не наоборот. Но объектное и табличное представление имеют много существенных отличий.
JPA - это только спецификация. Она была разработана на основе API Hibernate. Для работы требуется JPA Provider - Hibernate, например. Помимо Hibernate есть и другие провайдеры - Eclips Link, OpenJPA.
Если для простой доменной модели различия между объектным и табличным представлением не сильно повлияет на реализацию логики, то для более сложных моделей мы явно столкнемся со следующими проблемами:
Наследование таблиц в стандарте SQL не поддерживается. Есть, например, поддержка из коробки от postgreSQL, но зависимость от вендора накладывает некоторые ограничения
Идентичность объектов можно спокойно реализовывать на основе бизнес полей. Например класс User(login, password, name, age) - идентичность можно обеспечить только по полю login.
Идентичность в реляционной модели обеспечивается по первичному ключу. Но если в качестве первичного ключа в таблице USER выбрать login, то при его изменении нужно будет учитывать все внешние ключи, которые на него ссылаются.
Поэтому в таблицах для обеспечения идентичности используются суррогатные ключи (автоматически сгенерированные идентификаторы). Такие искусственные ключи плохо ложатся на объектную доменную модель.
Ассоциации между объектами обеспечиваются ссылками из одного объекта на другой. Ассоциации между таблицами поддерживаются внешними ключами, дублируя значения ключа.
Это влияет на направленность связи. Например:
 Видно, что главной сущностью этой связи является объект
Видно, что главной сущностью этой связи является объект User.
В объектной ассоциации именно User хранит список объектов Card.
В табличном представлении нельзя в одной строке таблицы хранить список ссылок на строки другой таблицы.
Столбец внешнего ключа расположен в таблице CARD и тут уже таблица CARD ссылается на таблицу USER, а не наоборот.
Объектные и табличные фактически связи имеют разное направление.
Помимо этого объектные ассоциации поддерживают связь many-to-many, в то время как в реляционных БД эта связь не поддерживается естественным образом - нужна таблица посредник.
Существует фундаментальное различие между доступом к данным в Java и в БД. Допустим, вам нужно сгруппировать список карт по пользователям. В Java вы вызываете такой код
Map<String, List<Card>> cardByUser = new HashMap<>();
//given list of cards
cards.forEach(card -> {
// it's OK for java
// But there is a problem here from SQL perspective
User user = card.getUser();
cardByUser.computeIfAbsent(
user.getLogin(),
new ArrayList<>()
).add(card);
})Это наиболее удобный способ обхода графа объектов в Java. Однако такой способ является неэффективным в SQL. Он может привести к проблеме N + 1 запроса:
/* 1 query for cards */
select * from CARD
/*
then for each card you execute N queries:
*/
select * from USER where USER.id = CARD.user_fkДля повышения производительности нужно уменьшить количество запросов к БД. Это достигается обычно с помощью соединения таблиц.
Различие способов доступа к данным чаще всего приводят к проблемам с производительностью.
(И цель Hibernate в частности) - автоматически преобразовывать объектное представление в табличное, решая вышеуказанные проблемы и автоматически генерировать SQL запросы в ответ на изменение состояния объектов.
Также Hibernate из коробки предоставляет следующие возможности:
- JDBC batching без изменения кода доступа к данным
- Поддержка оптимистических блокировок (в JDBC не предоставляет такого API)
- Независимая от вендора БД абстракция для пессимистичных блокировок
- Независимая от вендора БД поддержка постраничных запросов
- Возможность использовать java.util.List в условиях поиска с IN
- кэш (первого, второго уровня) и кэш запросов
- Возможность использовать нативные запросы
При этом у Hibernate есть и свои минусы:
- Hibernate предоставляет удобные абстракции и API, но не избавляет от необходимости изучать JDBC API, базы данных и SQL. Порог входа в hibernate очень низок, но чтобы стать экспертом - нужно понимать, как устроена работа уровенем ниже.
- Есть много неочивидных моментов, которые могут обескуражить в начале знакомства с Hibernate-ом, если о них не знать. Например порядок вызова методов EntityManager#flush() или FetchType.EAGER по умолчнию при запросе сущностей.
- The Criteria API
JPA оперирует сущностями - классами, помеченными аннотацией @Entity.
import org.hibernate.annotations.NaturalId;
import javax.persistence.*;
@Entity(name = "Post")
@Table(
name = "post",
uniqueConstraints = @UniqueConstraint(
name = "slug_uq",
columnNames = "slug"
)
)
@Data
@Builder(toBuilder = true)
@NoArgsConstructor
@AllArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String title;
@NaturalId
private String slug;
}У каждой сущности должен быть идентификатор - поле, помеченное аннотацией @Id. Значение идентификатора можно генерировать как в приложении, так и предоставить возможность Hibernate-у сгенерировать его автоматически. Автоматическая генерация идентификаторов это тема для отдельного разговора.
Для простого случая можно пометить идентификатор аннотацией
@GeneratedValue(strategy = GenerationType.SEQUENCE). При этом в БД будет создана последовательность с названиемhibernate_sequence, и идентификаторы будут генерироваться при каждом вызовеpersist. Об этом вызове ниже.
Для управления сущностями JPA использует объект EntityManager - он служит центральной точкой входа в функциональность, предоставляемую JPA, и позволяет создавать, обновлять, удалять и запрашивать данные из БД.
EntityManager не является потокобезопасным. Более того - рекомендуется создавать новый EntityManager для каждой новой транзакции.
Так делается в spring, например. Когда мы инжектим
EntityManager, мы получаем прокси
При старте новой логической транзакции эта прокся делигирует в уже существующий для данной транзакции
EntityManager, либо, если подходящий EM еще не существует - создает новый.
EntityManager создается с помощью метода EntityManagerFactory#createEntityManager()
Каждая сущность имеет свой жизненный цикл. Важно понимать, что жизненный цикл сущности имеет смысл только в отношении конкретного экземпляра EntityManager-а. Сама сущность ничего не знает о своем состоянии. И одна и та же сущность может находиться разных состояниях для разных экземпляров EntityManager-а
Во многих источниках определяются следующие четыре состояния для сущности:
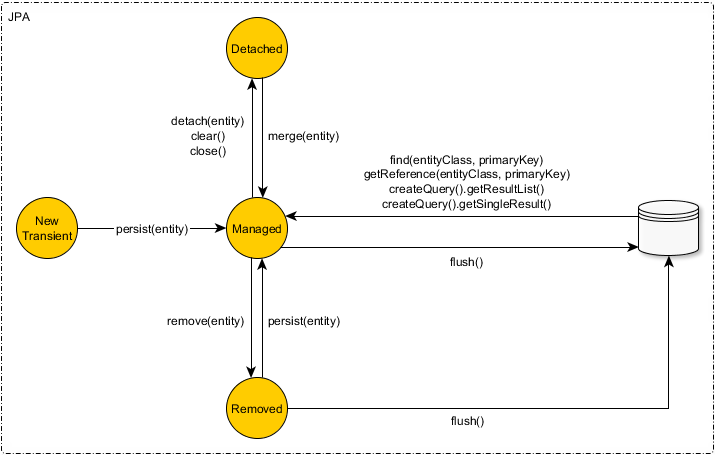
На диаграмме видно, что сущность меняет свое состояние при вызове методов persist, merge, remove и др. у EntityManager-а
Метод persist(Object) переводит сущность из состояния NEW в MANAGED. Для сущностей в состоянии MANAGED EM начинает отслеживать все изменения.
Метод find(Object, Id) находит запись в БД по идентификатору, создает сущность на основе этой записи и переводит ее в состояние MANAGED.
Помимо метода find запрашивать данные из БД можно с помощью запросов в синтаксисе JQPL и нативных запросов:
Query singleResQ = em.createQuery("select p from Post p where p.id = 1", Post.class);
Post p1 = singleResQ.getSingleResult();
Query multResQ = em.createQuery("select p From Post", Post.class);
List<Post> posts = multResQ.getResultList()
Query nativeSingleResQ = em.createNativeQuery("select * from post where id = 1", Post.class);
Post p2 = nativeQuery.getSingleResult();
Query nativeMultResQ = em.createNativeQuest("select * from post");
List<Post> nativeQPosts = nativeMultResQ.getResultList();Возвращенные в результате этих запросов сущности также переходят в состояние MANAGED и отслеживаются EntityManager-ом.
*** В spring data jpa тоже можно запрашивать данные из БД с помщью JPQL или нативных запросов используя репозитории:
public interface PostRepository extends JpaRepository<Post, Long> {
@Query(
nativeQuery = true,
value = "select * from post where id = :id"
)
Post selectNativeById(@Param("id") Long id);
@Query(
nativeQuery = true,
value = "select * from post"
)
List<Post> selectNativeAll();
@Query("select p from Post p where p.id = :id")
Post selectById(@Param("id") Long id);
@Query("select p from Post p")
List<Post> selectAll();
}И все эти запросы также будут возвращать сущности, которые в рамках транзакции будут находится в состоянии MANAGED для определенного в этой транзакции EntityManager-a.
После закрытия EntityManager-а или после вызова метода detach сущность переходит из состояния MANAGED в состояние DETACHED. В этом состоянии сущность отвязана от EntityManager-а. Это означает, что какие бы изменения вы не делали с DETACHED сущностью, после коммита транзакции эти изменения не попадут в базу.
Метод remove удаляет сущность, перенося ее в состояние REMOVED. Как и в состоянии DETACHED, в REMOVED сущность также отвязана от EntityManager-а. Разница только в том, что метод remove указывает EntityManager-у отправить запрос DELETE в базу после коммита транзакции.
Метод merge служит в основном для обновления данных.
Допустим в транзакции TX1 вы достали сущность из БД.
После коммита TX1 и закрытия EM эта сущность перейдет в состояние DETACHED.
EntityManagerFactory emf = getEMF();
var em = emf.createEntityManager();
var tx = em.getTransaction()
tx.begin();
Post post = em.find(Post.class, 1L);
tx.commit();
em.close();
// after closing EM the post entity goes into DETACHED stateДалее вы открываете TX2, изменяете сущность и хотите сохранить изменения, то есть выполнить UPDATE в базе. Для этого вы вызываете метод merge с измененной сущностью.
post.setTitle('updated post');
em = emf.createEntityManager();
var tx = em.getTransaction();
tx.begin();
var mergedPost = em.merge(post);
em.contains(post) == false;
em.contains(mergedPost) == true;
// UPDATE is not sent to database till commit the transaction
tx.commit();Однако старая сущность останется в состоянии DETACHED навсегда. Метод merge создает новую сущность и возвращает ее. И она уже будет в состоянии MANAGED.
Следует упомнять, что код изменения
DETACHEDсущности не обязательно должно быть после открытия транзакции.DETACHEDсущность - это обычная DTO, и вы можете делать с ней все, что угодно. ЭкземплярDETACHEDсущности уже никогда не перейдет в состояниеMANAGED.
JPA автоматически отправляет изменения в БД после коммита транзакции.
Явно вызывать EntityManager#flush() не нужно - это считается плохой практикой.
Помимо коммита транзакции EntityManager#flush() может быть спровоцирован рядом других событий:
- JPQL запросы
- Запросы через Criteria API
- Нативные запросы
Это нужно для поддержания консистентности данных с кэшом первого уровня. Подробнее об этом чуть далее
Видимость этих изменений в других транзакциях зависит от их уровня изоляции. По умолчанию в JPA используется уровень READ COMMITED. Поэтому сюрпризов быть не должно и эти изменения не должны быть видны другим транзакциям (конечно, если вы об этом явно не попросите).
После того, как сущность была переведена в состояние MANAGED, она сохраняется внутри EntityManager-а в мапе:
Map<EntityUniqueKey, Object> entitiesByUniqueKey = new HashMap<>(INIT_COLL_SIZE);А ключ для мапы определяется следующим образом:
public class EntityUniqueKey implements Serializable {
private final String entityName;
private final String uniqueKeyName;
private final Object key;
private final Type keyType;
...
@Override
public boolean equals(Object other) {
EntityUniqueKey that = (EntityUniqueKey) other;
return that != null &&
that.entityName.equals(entityName) &&
that.uniqueKeyName.equals(uniqueKeyName) &&
keyType.isEqual(that.key, key);
}
...
}И эта мапа используется в качетве кэша первого уровня, который работает по стратегии write-behind.

Алгоритм поиска сущности в EntityManager выглядит следующим образом:
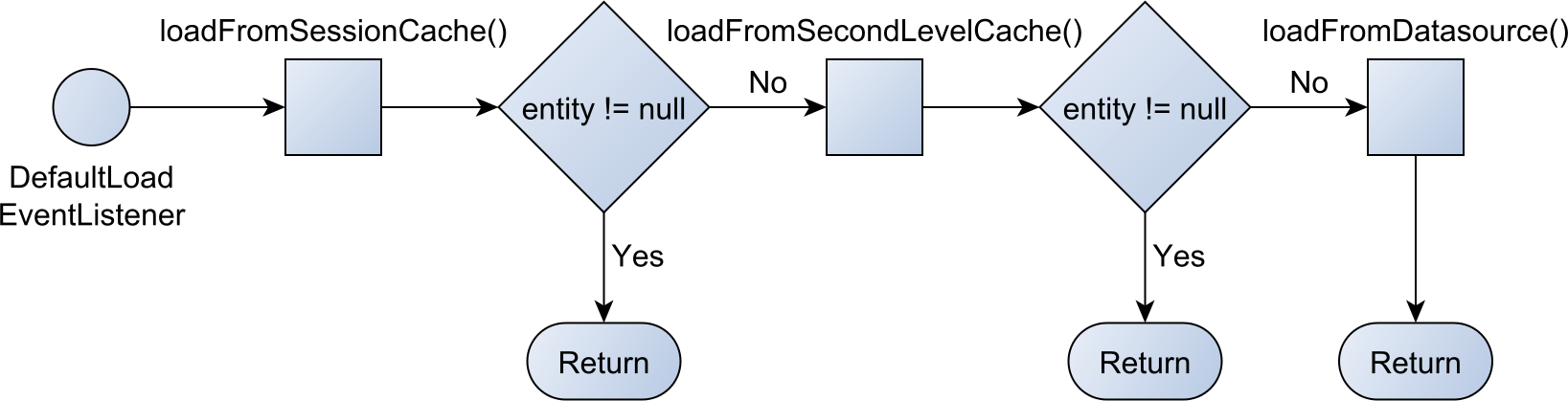
- Сначала происходит поиск в мапе EntityManager-а
- Затем в кэше второго уровня (если настроен)
- В последнюю очередь EM делает запрос в БД
// select * from USER where id = 1 && save it to cache
User selectedUser = em.find(User.class, 1L);
// cache hit
User cachedUser = em.find(User.class, 1L);
// two objects are identical i.e.
// the object's references point to same memory address
assert selectedUser == cachedUserТакой кэш дает ряд преимуществ
Батчинг
Все изменения сущности аккумулируются в батч и исполняются один раз при выполнении EntityManager#flush()
Повторяемое чтение
Как известно спецификация ANSI определяет 4 уровня изоляции транзакций:
- READ UNCOMMITED
- READ COMMITED
- REPEATABLE READ
- SERIALIZABLE
Уровни изоляции определяют тот уровень несинхронизированного конкуретного доступа к данным, который допускается в конкретном приложении.
По умолчанию во многих в БД используется уровень READ COMMITED, как наиболее компромиссный в том смысле, что он позволяет избежать самые неудобные аномалии: DIRTY READ и DIRTY WRITE При этом допускаются следующие:
- NON REPEATABLE READ
- LOST UPDATE
- PHANTOM READ
Уровень REPEATABLE READ фактически (в PostgreSQL и MySQL) позволяет избежать даже таку аномалию как PHANTOM READ. А в PosgreSQL даже LOST UPDATE.
Однако, например, в Oracle уровень REPEATABLE READ не поддерживается. Oracle Driver выкинет исключение, если попытаться начать транзакцию с этим уровнем.
Но зато SERIALIZABLE в Oracle делает примерно то же, что и REPEATABLE READ в PostgreSQL и MySQL, а настоящего SERIALIZABLE в Oracle нет.
Так вот, даже с уровнем изоляции READ COMMITED кэш первого уровня позволяет имитировать уровень REPEATABLE READ, но все же допуская аномалии PHANTOM READ и LOST UPDATE.
Так как любой запрос - JPQL, Criteria API, Native Query - всегда достигает базы данных (кроме случаев, когда происходит second level cache hit), то нужно быть уверенным, что все зафиксированные в EM изменения попадут в базу перед выполнением запроса. Как минимум потому, что логика запроса может быть основана на этих изменениях.
Для этого в спецификации JPA определена так называемая flush-before-query стратегия синхронизации. То есть, как уже поминалось ранее, по умолчанию JPQL, Criteria API и нативные запросы провоцируют EntityManager#flush().
*** В spring data jpa такое поведение также определено по умолчанию.
Если не настроен кэш второго уровня, любые запросы всегда будут уходить в базу. При этом, так как в JPA уровень изоляции транзакций по умолчанию настроен READ COMMITED, то запросы могут провоцировать следующие аномалии:
- NON REPEATABLE READ
- LOST UPDATE
- PHANTOM READ
При обработке результата запроса JPA сравнивает результаты с сущностями, которые уже есть в кэше. И если находит сущности с двумя одинаковыми идентификаторами - выбирает ту, которая есть в кэше, а не ту, которая пришла в результате запроса. Таким образом мы избавляемся от аномалии: NON REPEATABLE READ
В случае, если данные были удалены, запрос не найдет их БД. Так как в результате запрос не вернет ни одной сущности, то никакой попытки пойти в кэш и не будет.
В случае, если данные наоборот были добавлены, запрос найдет эти данные, хотя в кэше их нет.
Таким образом защиты от фантомного чтения не происходит.
Защита от LOST UPDATE может быть реализована с помощью оптимистических блокировок.
Все вышесказанное справедливо как для JPA: JPQL и нативных запросов, так и для spring data jpa используя репозитории.
( ! ) Однако по поводу нативных запросов следует сказать, что не все нативные запросы будут сравнивать полученные из БД данные с сущностями в кэше. Сравнение будет происходить, когда в результате запроса возвращается именно сущность, и в списке вывода (selection list) присутствуют колонки, соответствующие всем полям данной сущности.
Например следующий запрос вернет данные из базы, несмотря на то, что сущность с переданным идентификатором будет в кэше:
@Query(
nativeQuery = true,
value = "select title from post where id = :id"
)
String selectTitleById(@Param("id") Long id);Сущность попадает в кэш EM при:
- вызовах
persistилиmerge - если была найдена методом
find - Если была найдена в результате запросов JQPL, Criteria API и Native Query
В случае с Native Query есть один нюанс: сущность попадает в кэш только в том случае, если при создании запроса был указан тип (класс) сущности.
em.createNativeQuery(
"select * from post",
Post // entity type is specified
).getResultList()
// cache will be populated with found entitiesЕсли тип не указывать, то даже если сущность была найдена в результате запроса, в кэш она не попадет - недостаточно информации для создания ключа мапы.
// entity type is not specified
em.createNativeQuery("select * from post")
.getResultList()
// cache woun't be populated with found entities*** spring data jpa
Разогрев кэша также происходит при выполнении запросов используя JpaRepository.
Это касается:
- существующих методов (
findById,findAll, ...) - сгенерированных запросов на основе парсинга названия метода
- JPQL запросов через аннотацию
@Query - Нативных запросов через аннотацию
@Query
( ! ) Наверное стоит упомянуть, что сущности будут попадать в кэш, только если нативный запрос возвращает именно сущность (или список сущностей), а не проекции, то есть в списке вывода запроса присутствуют все колонки, которые соответствуют полям возвращаемой сущности.
Например при выполнении следующего запроса сущность переданным id не будет помещена в кэш
@Query(
nativeQuery = true,
value = "select title from post where id = :id"
)
String selectTitleById(@Param("id") Long id);Существует три типа маппингов в JPA:
- Сущности (
@Entity) - Простые типы (String, Long, Dobule, Date, Boolean и т.д.)
- Встраиваемые типы (
@Embeddable)
Отличаются от сущностей тем, что им запрещено иметь собственный идентификатор.
@Table(name = "users")
@Entity
class User {
@Id
@Column(name ="id")
Long id;
@Column(name = "login")
String login;
@Embedded
FullName fullName;
}
@Embeddable
class FullName {
@Column(name = "first_name")
String firstName;
@Column(name = "last_name")
String lastName;
}Они отлично подходят для реализации такого вида ассоциации из UML, как композиция
В табличном представлении поле fullName "раскрывается" в две отдельные колонки таблицы users
create table users(
id bigint primary key,
login varchar(256),
first_name varchar(256),
last_name varchar(256)
)
Мы рассмотрим основные виды связей
- many-to-one (one-to-many)
- one-to-one
- many-to-many
Связь many-to-one представляет собой дочернюю сторону связи one-to-many между двумя таблицами. Дочерняя сторона в данном случае - это таблица, в которой располагается внешний ключ связи.
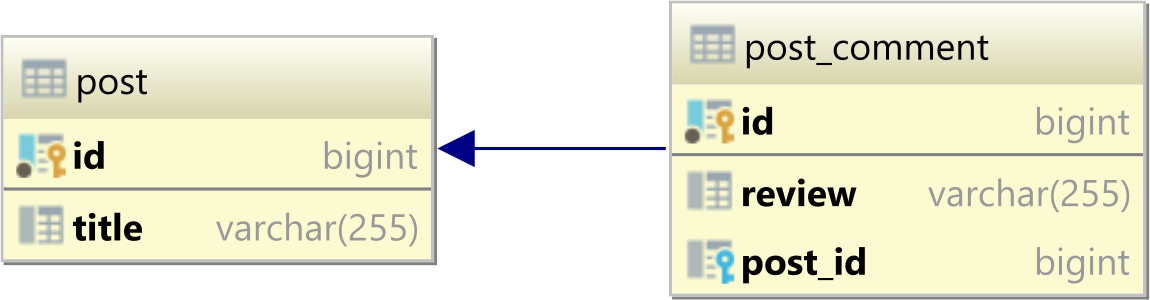
В данном примере к одному посту можно оставить несколько комментариев. И один коментарий может принадлежать только одному посту.
Соответствующую связь между объектами Post и PostComment можно представить композицией:

Чтобы отобразить такую связь, используется аннотация @ManyToOne в дочерней сущности:
@Entity(name = "PostComment")
@Table(name = "post_comment")
public class PostComment {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
Long id;
String review;
@ManyToOne
Post post;
}При этом по умолчанию название колонки для внешнего ключа строится из: "название поля для родительской сущности"_"название поля идентификатора в родительской сущности"
Т.е. в данном случае:
"название поля родительской сущности" = "post"
"название поля идентификатора в родительской сущности" = "id"
=> post_id
Чтобы сконфигурировать навание колонки внешнего ключа используется аннотация @JoinColumn:
@ManyToOne
@JoinColumn(name="post_fk")
Post post;Объектая ассоциация в данном случае имеет такое же направления, что и реляционная связь. То есть объект PostComment ссылается на объект Post.
Но если направление объектной ассоциации противоложное, то есть если объект Post ссылается на список объектов PostComment, нужна другая аннотация
Эта аннотация также отображает реляционную связь many-to-one
Она нужна, чтобы поменять направленность ассоциации между объектами. Различают два вида @OneToMany:
- Двунаправленная
- Однонаправленная:
Двунаправленная она потому, что в дочерней сущности есть соответствующая @ManyToOne ассоциация.
@Entity
@Table(name = "post")
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String title;
private String slug;
@OneToMany(mappedBy = "post")
List<PostComment> postComments = new ArrayList<>();
}При этом владельцем связи считается дочерняя сущность. Это значит, что именно дочерняя сущность контролирует синхронизацию значения колонки внешнего ключа с кэшом EntityManager-а. Параметр mappedBy нужно указывать именно для того, чтобы показать, что сущность не является владельцем связи.
Если параметр mappedBy не указать, hibernate не поймет, что мы имеем ввиду, и создаст в БД третью таблицу:
create table post_post_comments (
post_id bigint not null,
post_comments_list_id bigint not null
)Несмотря на то, что за синхронизацию внешнего ключа отвечает дочерняя сущность, поддерживать объекты в актуальном состоянии нужно и родительской и в дочерней сущности. Автоматически hibernate это не делает.
Ниже показан пример, как нужно правильно добавлять/удалять сущность PostComments в список:
void addPostComment(PostComment postComment) {
postComments.add(postComment);
postComment.setPost(this);
}
void removePostComment(PostComment postComment) {
postComments.remove(postComment);
postComment.setPost(null);
}( ! ) Чтобы такой способ удаляния работал корректно, нужно переопределить меоды equals и hashCode. Иначе удаление из коллекции будет использовать дефолтный метод equals, который сравнивает ссылки.
Так тоже может сработать, но только в рамках одной транзакции. Между разными транзакциями уже могут возникать проблемы, так как одна и та же запись в БД может быть представлена разными обектами.
Одно из главных перимуществ использования двунаправленной ассоциации - это возможность каскадного распространения изменений из родительской сущности в дочернюю.
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL)
List<PostComment> postCommentsList = new ArrayList();Например:
- если сохранить только
Post, то все добавленные в списокpostCommentsListкомментарии тоже сохранятся. - если удалить родительскую сущность
Post, дочерние тоже удалятся.
При удалении комментария из коллекции списка postCommentsList и последующем сохранением сущности Post, объект PostComment не удалится из БД. Вместо этого в базу отправится следующий запрос:
update post_comment set post_id=NULL where id=${post_comment_id}Чтобы сущность удалилсь из БД, нужно добавить параметр
orphanRemoval=true в аннотацию @OneToMany:
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL, orphanRemoval = true)
List<PostComment> postComments = new ArrayList<>();В дочерней сущности отсутствует соответствующая @ManyToOne ассоциация. При этом владельцем связи считается родительская сущность
Атрибут mappedBy больше не нужен.
Однако нужна аннотация @JoinColumn(name="post_id")
Если не указать @JoinColumn hibernate сгенерирует третью таблицу:

Поэтому отображение теперь выглядит так
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "post_id")
private List<PostComment> postCommentsList = new ArrayList<>();Однако однонаправленная связь имеет ряд недостатков (или недоработок со стороны hibernate), так как теперь сущность Post отвечает за синхронизацию комментариев PostCommnet с кэшом.
Допустим создается сущность Post с тремя комментариями, и затем сохраняется:
@Transactional
public void createPostWithComments() {
Post post = createPost("First post");
post.addComment(createComment("My first review"));
post.addComment(createComment("My second review"));
post.addComment(createComment("My third review"));
postRepository.save(post);
}JPA отправит в БД следующие запросы:
insert into post (title, id)
values ('First post', 1)
insert into post_comment (review, id)
values ('My first review', 2)
insert into post_comment (review, id)
values ('My second review', 3)
insert into post_comment (review, id)
values ('My third review', 4)
update post_comment set post_id = 1 where id = 2
update post_comment set post_id = 1 where id = 3
update post_comment set post_id = 1 where id = 4
Зачем нужны три последних update-а? Все дело в том, в каком порядке EM выполняет операции flush (вот статья на эту тему).
persist выполняется перед тем, как обновляются элементы коллекции.
Таким образом, сначала EM выполняется три insert для комментариев без внешнего ключа.
Затем обновляет их проставляя зачение внешнего ключа.
Если добавленить в БД ограничение non null для внешнего ключа:
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "u_post_id", nullable = false)
List<PostComment> postComments;то поведение еще более странное:
insert into post (title, id)
values ('First post', 1)
insert into post_comment (review, id, post_id)
values ('My first review', 2, 1)
insert into post_comment (review, id, post_id)
values ('My second review', 3, 1)
insert into post_comment (review, id, post_id)
values ('My third review', 4, 1)
update post_comment set post_id = 1 where id = 2
update post_comment set post_id = 1 where id = 3
update post_comment set post_id = 1 where id = 4То есть JPA сгенерировал правильные insert, но update-ы все равно выполнил.
Чтобы привести дела в норму, можно добавить параметр updatable=false в аннотацию @JoinColumn. Тогда получим то, что ожидаем.
Я вначале подумал, что в этом случае сущность PostComment нельзя будет обновить. Однако следующий тест выполняется:
when:
long changedCommentId = txTemplate.execute({
def savedPost = uPostRepository.findById(1L).get()
def postComments = savedPost.getPostComments()
def postComment = postComments.get(0)
postComment.setReview("updated review")
uPostRepository.save(savedPost)
return postComment.getId()
})
then:
sql.query("select * from u_post_comment where id = ${changedCommentId}", {
while (it.next()) {
assert it.getString('review') == 'updated review'
}
})Вообще из-за такого не очень понятного поведения рекомендуют не использовать однонаправленную @OneToMany связь.
Вместо нее можно использовать двунаправленную связь. А еще лучше @ManyToOne. Потому что использовать @OneToMany мы можем в том случае, если количество дочерних элементов не велико, так как невозможно лимитировать размер коллекции @OneToMany.
В большинстве случаев @ManyToOne - все, что вам нужно.
Со стороны БД связь "один к одному" основывается на уникальности колонки внешнего ключа в дочерней таблице. И может быть представлена следующим образом:

Данная связь тоже может быть двунаправленной либо однонаправленной:
Даже объектная ассоциация @OneToOne похожа на @ManyToOne, если смотреть со стороны дочерней сущности.
@Entity
@Table(name = "post_details")
public class PostDetails {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
Long id;
String createdBy;
Instant createdAt;
@OneToOne
@JoinColumn(name = "post_fk")
Post post;
}Можно использовать аннотацию @JoinColumn, чтобы переопределить название колонки внешнего ключа.
Однако просто так это не будет работать - по какой-то причине JPA не проставляет уникальный индекс для внешнего ключи. Это нужно сделать явно:
- либо через параметр
@JoinColumn(unique=true) - либо через
@Table(uniqueConstraints=...)
@Table(
name = "post_details",
uniqueConstraints = @UniqueConstraint(
name = "post_id_fk_uk",
columnNames = "post_id"
)
)
Владельцем связи является дочерняя сущность, то есть сущность PostDetails отвечает за генерацию FK. Это значит, что при добавлении сущности Post к сущности PostDetails, автоматически сгенерится значение внешнего ключа:
def post = postRepository.findById(1L).get()
def postDetails = PostDetails.builder()
.createdBy("admin")
.createdAt(Instant.now())
.post(post)
.build()
postDetailsRepository.save(postDetails)insert into post_details (created_at, created_by, post_id, id)
values (
'2022-03-31 15:58:35.968539',
'admin',
'1', -- post_id foreign key
'1'
)В случае двунаправленной связи в родительской сущности тоже добавляется ассоциация @OneToOne, направленная в сторону дочерней. При этом владельцем связи считается дочерная сущность - поэтому используется атрибут mappedBy:
@Entity
@Table(name = "post")
public class Post {
...
@OneToOne(mappedBy = "post")
PostDetails details;
}В предложенном выше варинте связи между таблицами есть недостаток - явное указание уникальности внешнего ключа. Вместо этого можно просто сделать PK = FK.

Чтобы поддержать такое отображение нужны следующие изменения в дочерней сущности:
@Entity
@Table
public class PostDetails {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
Long id;
String createdBy;
Instant createdAt;
@OneToOne
@MapsId
Post post;
}В этом случае внешний ключ по умолчанию будет называться post_id
Поменять его название можно все той же аннотацией @JoinColumn:
@OneToOne
@MapsId
@JoinColumn(name = "post_id_fk")
Post post;Способ сохранения PostDetails при этом никак не поменяется - следующий код продолжит работать:
def post = postRepository.findById(1L).get()
def postDetails = PostDetails.builder()
.createdBy("admin")
.createdAt(Instant.now())
.post(post)
.build()
postDetailsRepository.save(postDetails)
И теперь доставать сущность PostDetails можно по ключу Post
Отображает связь "many-to-many" между таблицами, которая в БД реализуется с помощью третьей таблицы:

Может быть однонаправленной или двунаправленной
Добавляем сущность Tag:
@Entity
@Table(name = "tag")
public class Tag {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
Long id;
String name;
}Пусть владельцем связи будет сущность Post, и тогда она будет содержать коллекцию тэгов:
@Entity
@Table(name="post")
class Post {
...
@ManyToMany(cascade = {PERSIST, MERGE})
@JoinTable(name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
List<Tag> tags = new ArrayList<>();
}Указав каскад cascade = {PERSIST, MERGE} при сохранении сущностей Post сущности Tag тоже будут сохраняться, а также будет создаваться запись в таблице post_tag, которая и реализует связь "many-to-many"
( ! ) Cascading: Указывать cascade = {REMOVE} смыла не имеет. Удаление сущности Post не должно провоцировать удаление сущности Tag. Аналогично и обратное. Должна удаляться только запись из таблицы post_tag.
Поэтому вместо cascade = ALL указывается только PERSIST и MERGE
Проблемы появляются при удалении тэгов из списка родительской сущности.
post = createPostWithTags(tag1, tag2, tag3) //post.id = 1
post.getTags().remove(tag1)
postRepository.save(post);DELETE FROM post_tag WHERE post_id = 1
INSERT INTO post_tag (post_id, tag_id) values (1, 2)
INSERT INTO post_tag (post_id, tag_id) values (1, 3)То есть сначала удаляются все записи с post_id = 1, а затем вставляются те, которые сохранились в кэше EM. T_T
Чтобы эту проблему убрать, для @ManyToMany вместо List нужно использовать Set:
@ManyToMany(cascade = {PERSIST, MERGE})
@JoinTable(name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
Set<Tag> tags = new ArrayList<>();Тогда при удалении тэгов из Set-а
post = createPostWithTags(tag1, tag2, tag3) //post.id = 1
post.getTags().remove(tag1)
postRepository.save(post);Hibernate сгенерирует правильный запрос:
DELETE FROM post_tag WHERE post_id = 1 and tag_id = 2Для двунаправленной связи обе сущности содержат коллекции, ссылающиеся друг на друга.
Так как в связи "many-to-many" обе стороны - родительские (а дочерней стороной выступает третья "соединительная" таблица), то разработчик сам выбирает, какая из сущностей будет владеть связью. И в подчиненной сущности нужно просто указать аннотацию ManyToMany(mappedBy = ...).
Например, пусть связью владеет сущность Post, тогда в сущности Tag указываем следующее:
@ManyToMany(mappedBy = "tags")
Set<Post> posts = new HashSet<>();Атрибут mappedBy указывает на коллекцию tags в сущности Post.
Это значит, что именно сущность Post ответственна за то, чтобы синхронизировать все изменения с соединительной таблицей.
Здесь, как и для @OneToMany, все равно нужны вспомогательные методы добавления/удаления из коллекции, чтобы держать в синхронизированном состоянии обе сущности.
public void addTag(Tag tag) {
tags.add(tag);
tag.getPosts().add(this);
}
public void removeTag(Tag tag) {
tags.remove(tag);
tag.getPosts().remove(this);
}Наследование таблиц по умолчанию не поддерживаются. JPA (и Hibernate) в частности поддерживает наследование сущностей, определяя три стратегии:
- Создание единой таблицы (тогда в не которых колонках будут null)
- Родительская + Дочерние таблицы (При этом при запросе данных нужно будет делать JOIN)
- Отдельные таблицы на каждую дочернюю сущность
Объявляется наследование просто - над базовой сущностью нужно поставить аннотацию @Inheritance и указать стратегию.
Пример - базовый класс JOIN strategy:
@Data
@Entity
@SuperBuilder
@NoArgsConstructor
@Inheritance(
strategy = InheritanceType.JOINED
)
@Table(name = "request")
@EntityListeners(AuditingEntityListener.class)
@AllArgsConstructor
public class Request {
@Id
@Builder.Default
String id = UUID.randomUUID().toString();
@Enumerated(EnumType.STRING)
Status status;
@CreatedDate
@Column(updatable = false)
Instant created;
enum Status {
NEW,
SENT,
SUCCESS,
FAILURE
}
}@Data
@Entity
@Table(name = "create_request")
@EqualsAndHashCode(callSuper = true)
@SuperBuilder
@NoArgsConstructor
@AllArgsConstructor
public class CreateRequest extends Request {
@Embedded
CreatedObject createdObject;
}У Vlad Mihalcea в блоке есть отличная
подборка статей на тему наследования