{kind=link}
This is Part 2 in a series of 3 workshops on how to build Serverless applications using AWS Technologies
- AWS Command Line Interface installed and properly set up
- access to the Amazon Console GUI
- Amazon Corretto 11
- Python 3.8.x
- Terraform 0.12.23
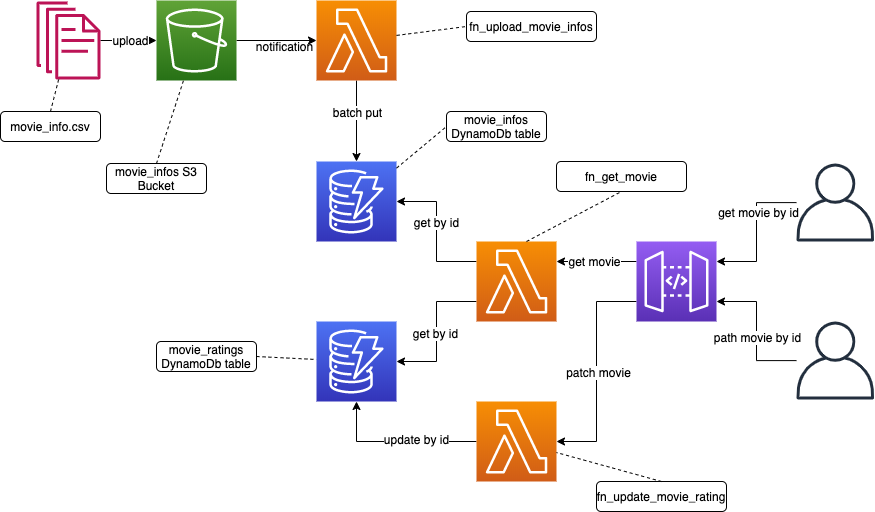
Movies is a fictional application used for the management of movies.
| Property | Type |
|---|---|
| movie_id | String |
| name | String |
| country_of_origin | String |
| release_date | String |
| Property | Type |
|---|---|
| movie_id | String |
| rotten_tomatoes_rating | Number |
| imdb_rating | Number |
- batch ingestion: periodically, a new file is uploaded to the S3 bucket, containing all Movie Info objects
- single update: occasionally, ratings (a Movie Rating object) are updated
- data retrieval: frequently, a full Movie model is retrieved
- Serverless, event-driven, stateless compute workloads
- Lightweight, limited execution time, resource-bound
- Works best as "glue" between other stateless AWS services
- Highly performant, Key-Value and Document NoSQL Data Store
- Serverless, automatically scalable
- Supports ACID transactions
- Simple and secure object storage
- Serverless & stateless
- Object management supports event notifications
- Basic API Gateway, translates events from "web" protocols (HTTP, WebSockets, etc.) into AWS events
- Fully managed service
- AWS IAM - secures access to AWS services and resources
- AWS CloudWatch - logging and monitoring for AWS services
- AWS X-Ray - tracing for AWS services
Write and execute code to define, deploy, update, and destroy your infrastructure.
Five broad categories of IAC tools:
- Ad hoc scripts
- e.g.: typically bash scripts or python, ruby, perl scripts
- Configuration management tools - designed to install and manage software on existing servers
- e.g.: Chef, Puppet, Ansible, SaltStack
- Desired features:
- Coding conventions
- Idempotence
- Distribution
- Server templating tools - create an image of a server that captures a fully self-contained snapshot of the operating system (OS), the software, the files, and all other relevant details
- e.g.:
- Using Virtual Machines:
- Packer - typically used to create images that you run directly on top of production servers, (AMI to run in AWS)
- Vagrant - typically used to create images that you run on your development computers
- Using Containers: Docker, CoreOS rkt, cri-o
- Using Virtual Machines:
- Key component of the shift to immutable infrastructure - once you’ve deployed a server, you never make changes to it again; if you need to update something, such as deploy a new version of your code, you create a new image from your server template, and you deploy it on a new server
- e.g.:
- Orchestration tools
- e.g.: Kubernetes, Apache Marathon & Apache Mesos (DC/OS), Amazon Elastic Container Service (ECS), Docker Swarm, Nomad
- Provisioning tools - designed to install and manage software on existing servers plus installing and deploying the actual servers themselves
- e.g. Terraform, CloudFormation, OpenStack Heat
- open source tool created by HashiCorp (just as Nomad, Packer and Vagrant) and written in the Go (just as Kubernetes, Docker, etc.)
- compiled and distributed as a single binary
- supports numerous infrastructure providers
- IaaS: Amazon Web Services, Microsoft Azure (1st class citizen), Google Cloud Platform, DigitalOcean, Linode, IBM Cloud, Oracle Cloud Infrastructure, Alibaba Cloud, etc.
- PaaS: cloud specific offerings from AWS, Azure, GCP, Heroku, etc.
- SaaS: GitHub, GitLab, Datadog, Graphana, Cloudflare, PagerDuty, Opsgenie, etc.
- Client & server included into a single binary called
terraform - Input represented by source files written using HCL
terraformparses input file and generatesdesired stateterraformretrieves theactual stateterraformcomparesdesired statewithactual state, analyzes the dependency graph and generates the action planterraformconsults plugins for generating the actual API callsterraformapplies (in a non-transactional manner) the action planterraformupdatesactual state
- Configuration management versus provisioning versus using multiple tools together
- use the right tool for the job, or even a combination of multiple tools together
- Mutable infrastructure versus immutable infrastructure
- Chef, Puppet, Ansible, SaltStack, Terraform typically default to a mutable infrastructure paradigm - components are updated in place due to configuration changes
- over time, each component becomes different from another
- Docker, Packer typically default to immutable infrastructure paradigm - components are recreated and replaced
- replacing everything every time might be inefficient by definition
- Chef, Puppet, Ansible, SaltStack, Terraform typically default to a mutable infrastructure paradigm - components are updated in place due to configuration changes
- Imperative (procedural) versus Declarative (functional) (
howversuswhat)- Chef and Ansible encourage a procedural style in which one writes code that specifies, step by step, how to achieve the desired end state.
- Procedural code does not fully capture the state of the infrastructure, only the "update"
- Procedural code limits reusability
- Terraform, CloudFormation, SaltStack, Puppet all encourage a more declarative style in which one writes code that specifies the desired end state, and the IaC tool itself is responsible for figuring out how to achieve that state.
- "zero-downtime" is difficult (but not impossible) to express in purely declarative terms
- Chef and Ansible encourage a procedural style in which one writes code that specifies, step by step, how to achieve the desired end state.
- Master & agent versus masterless & agentless
- Chef, Puppet, and SaltStack require masters and agents
- master components are used for storing the state of your infrastructure and distributing updates
- agent components run in background, receive and apply commands from masters
- More infrastructure, more maintenance effort, more security concerns
- Ansible, CloudFormation, Terraform - no masters, no agents
- Chef, Puppet, and SaltStack require masters and agents
- Large community versus small community
- Popularity order: Ansible, SaltStack, Terraform, Chef, Puppet
- CloudFormation - closed source, works only with AWS
Summary for main components of HCL
Resources are the most important element in the Terraform language. Each resource block describes one or more infrastructure objects, such as virtual networks, compute instances, or higher-level components such as DNS records.
resource "aws_instance" "web" {
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
}While resources are the primary construct in the Terraform language, the behaviors of resources rely on their associated resource types, and these types are defined by providers.
Each provider offers a set of named resource types, and defines for each resource type which arguments it accepts, which attributes it exports, and how changes to resources of that type are actually applied to remote APIs.
Most of the available providers correspond to one cloud or on-premises infrastructure platform, and offer resource types that correspond to each of the features of that platform.
Providers usually require some configuration of their own to specify endpoint URLs, regions, authentication settings, and so on. All resource types belonging to the same provider will share the same configuration, avoiding the need to repeat this common information across every resource declaration.
provider "google" {
project = "acme-app"
region = "us-central1"
}Input variables serve as parameters for a Terraform module, allowing aspects of the module to be customized without altering the module's own source code, and allowing modules to be shared between different configurations.
When you declare variables in the root module of your configuration, you can set their values using CLI options and environment variables. When you declare them in child modules, the calling module should pass values in the module block.
variable "availability_zone_names" {
type = list(string)
default = ["us-west-1a"]
}Output values are like the return values of a Terraform module, and have several uses:
- A child module can use outputs to expose a subset of its resource attributes to a parent module.
- A root module can use outputs to print certain values in the CLI output after running terraform apply.
- When using remote state, root module outputs can be accessed by other configurations via a terraform_remote_state data source.
output "instance_ip_addr" {
value = aws_instance.server.private_ip
}A local value assigns a name to an expression, allowing it to be used multiple times within a module without repeating it.
locals {
key = "value"
}A module is a container for multiple resources that are used together.
Every Terraform configuration has at least one module, known as its root module, which consists of the resources defined in the .tf files in the main working directory.
A module can call other modules, which lets you include the child module's resources into the configuration in a concise way. Modules can also be called multiple times, either within the same configuration or in separate configurations, allowing resource configurations to be packaged and re-used.
Data sources allow data to be fetched or computed for use elsewhere in Terraform configuration. Use of data sources allows a Terraform configuration to make use of information defined outside of Terraform, or defined by another separate Terraform configuration.
Each provider may offer data sources alongside its set of resource types.
data "aws_ami" "example" {
property = "value"
}- Define Modules
- aws_dynamodb_table
- aws_s3_bucket
- aws_iam_role
- aws_lambda_function
- aws_api_gateway_rest_api
- aws_api_gateway_resource
- aws_api_gateway_method
- aws_api_gateway_deployment
- aws_api_gateway_integration
- aws_lambda_permission
- aws_s3_bucket_notification
- Configure DynamoDB Tables -
movie_infos_tableandmovie_ratings_table - Configure S3 Bucket -
movie_infos_bucket - Define IAM Assume Role Policy for
ambda.amazonaws.comservices - Define IAM Policy documents -
upload_movie_infos_lambda_iam_policy_document,update_movie_rating_lambda_iam_policy_documentandget_movie_lambda_iam_policy_document - Configure IAM Roles -
upload_movie_infos_lambda_role,update_movie_rating_lambda_roleandget_movie_lambda_role - Configure Lambdas
upload_movie_infos_lambda,update_movie_rating_lambdaandget_movie_lambda - Configure API Gateway (resources, methods, deployments, integrations)
- Configure Lambda Permissions
- Configure S3 Bucket Notifications
- Generate input test file:
cat movie-infos.csv
mv1,Interstellar,United States,2014-10-26
mv2,The Dark Knight Rises,United States,2012-07-16
mv3,The Prestige,United Kingdom,2006-10-17
- Upload file to S3 bucket
aws s3 cp ~/movie-infos.csv s3://${bucket_name}- Send PATCH request
curl --request PATCH \
--url ${API_GW_DEPLOYMENT_URI}/movies/mv1 \
--header 'content-type: application/json' \
--data '{
"movie_id": "mv1",
"rotten_tomatoes_rating": 98,
"imdb_rating": 43
}'- Send GET request, verify results
curl --request GET \
--url ${API_GW_DEPLOYMENT_URI}/movies/mv1