ProgressReport04272010
Table of Contents:
The following manually constructed petri net represents the Peterson algorithm as it is simulated by the trace generator:
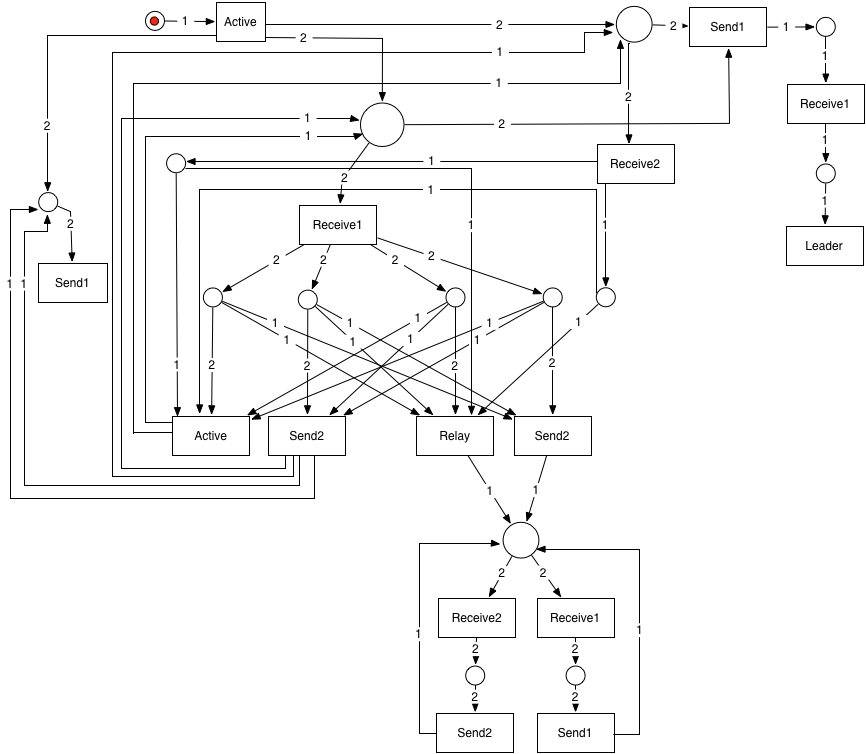
A few notes about this diagram:
-
The middle section with many crossing arrows represents a mutual exclusion of two concurrent processes. One of these generates active and send2 concurrently; and the second generates relay and send2 concurrently. These two sets of messages are not allowed to overlap in a single algorithm round.
-
The leader branch and the relay sub-graphs have no concurrency. So petri nets are not necessary to represent these.
-
There are dependencies between r1 and s2, (r1, r2) and active, (r1, r2) and relay. These dependencies create the tremendous complexity in the petri net representation.
-
There are no dependencies in a round between s1 and any of the other messages. As a result, its represented in the petri net with many fewer places and transitions.
After working on this diagram, we believe that (1) this diagram is unreadable and is not very usable for a systems developer, and (2) it is highly unlikely that we can generate this kind of petri net from execution traces.
We think that a much simpler representation of concurrency for this algorithm may be something like the following (cf. CCS, FSP):
{s1, (r2->active XOR relay), (r1->active || relay), (r1->s2)}
In the set above each elements must be executed once, and those elements with incoming arrows must first satisfy the source of the arrow. Graphically this is easier to read than the petri net equivalent.
Summary:
-
The algorithm executes in multiple 'active' rounds at a node. Originally the node rounds could only be identified implicitly (i.e. an active round was complete once all the 5 messages were observed: active/relay, recv1, recv2, send1, send2). This implicit separation of rounds is difficult to identify automatically.
-
Invariants that hold for a particular simulator state do not hold for other states (i.e. over the entire trace). For example, invariants that hold for the relay state of the node cannot be identified unless they also hold for the active state of the node. It is not clear how to mine invariants here, as naive approaches do not work due to the issue explained in the next point.
-
Its unclear how much we should push on handling concurrency in our representation and algorithm. Its an important feature of distributed systems, but its also very difficult.
-
At the moment the most practical solution is to pre-process the traces and parallelize all consecutive messages if we have not mined a dependency between them. The show stopper to this is that we have no means to infer to which round a given message belongs. This means that the algorithm will neglect the round structure and will incorrectly present all rounds as independent, parallel processes.
We investigated how a petri net could be synthesized from the traces. The net in last weeks report was not completely satisfying because it did not capture the behaviour accurately.
Since the ultimate goal was to get a more concise repesentation of concurrency, the first idea was to condense linear parts of the resulting automaton to a special node indicating concurrency. Using this technique, we could reduce the following automaton:
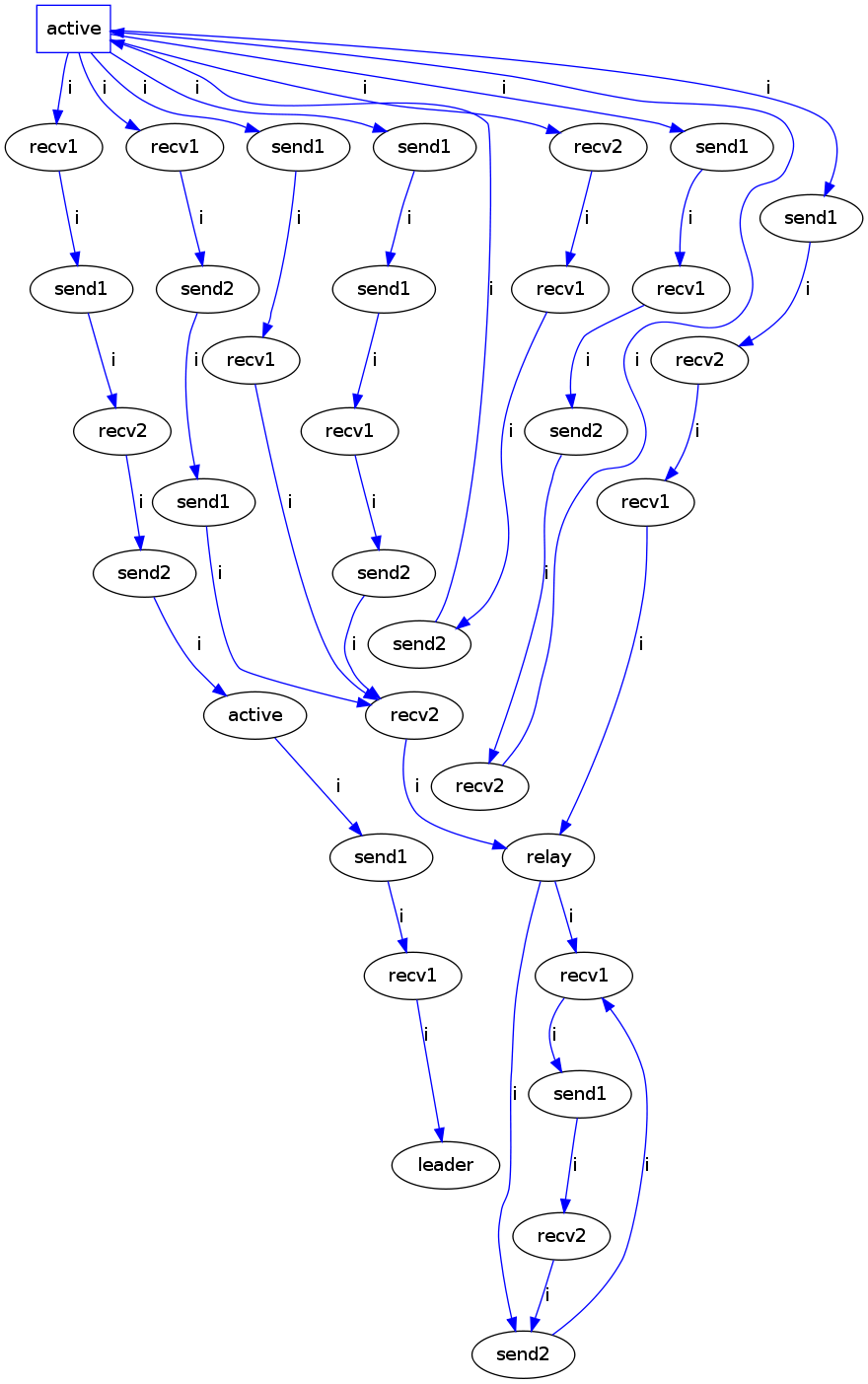
Using the independence properties (i.e. absence of AlwaysPrecedes constraints) obtained from invariant mining, we condensed the graph to the following graph. Process names are abbreviated, and process names in list notation can occur in any order.
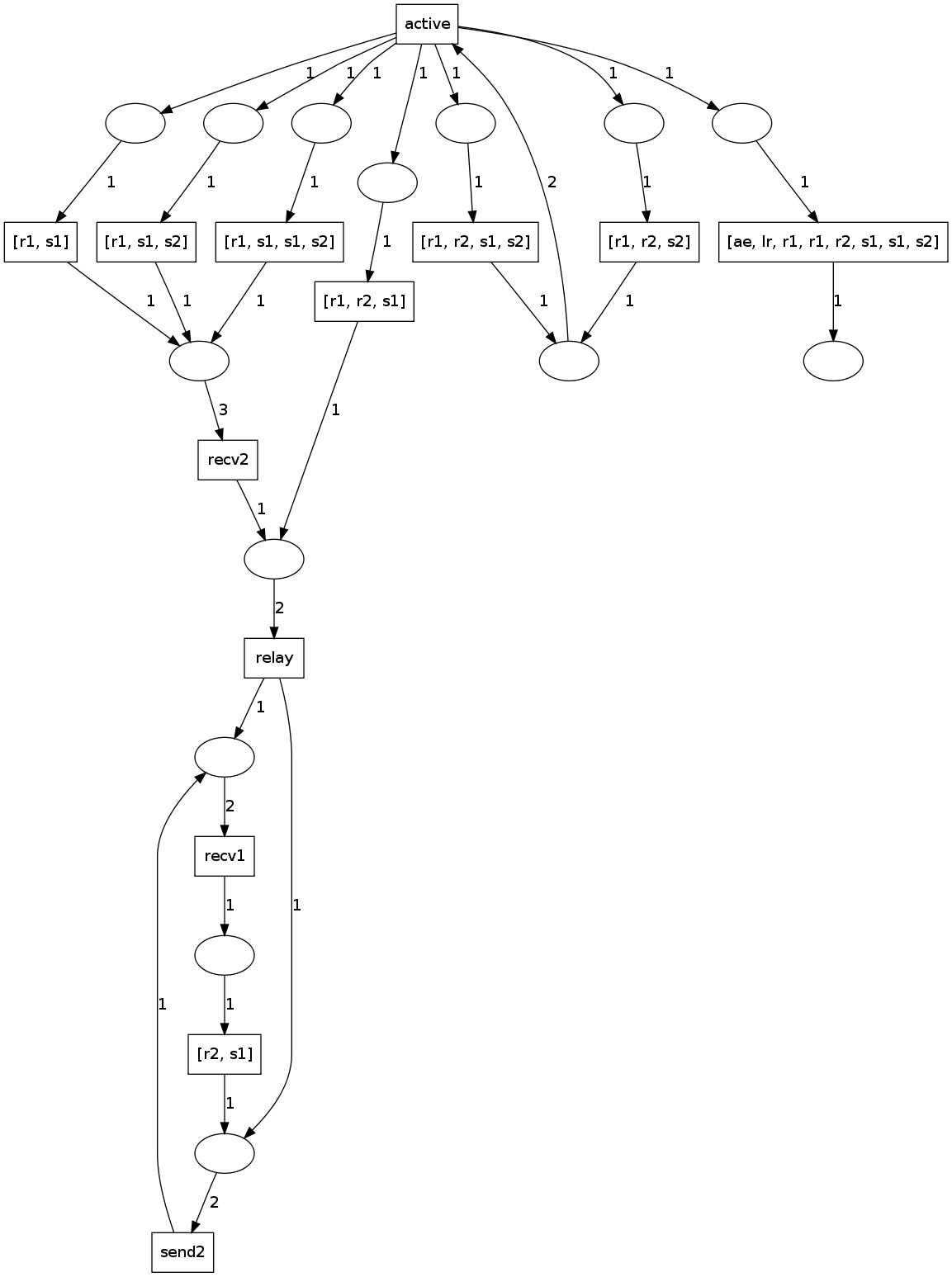
The result is not satisfying for several reasons. Most importantly we don't feel that it captures the behaviour of the system accurately (there is no correspondence to the many different branches after active). Also, if condensation produced identical process nodes, we would need another bisimulation pass to (possibly) merge them. The advantage is that the system works without altering bisim - we merely insert a post-processing step.
The next idea was to condense the initial trace and do bisimulation afterwards. The main problem here turned out to be find out what should be condensed. We tried to mine a petri net, and condense the trace as long as the net could produce it. The net we mined from the AlwaysPrecedes relation is
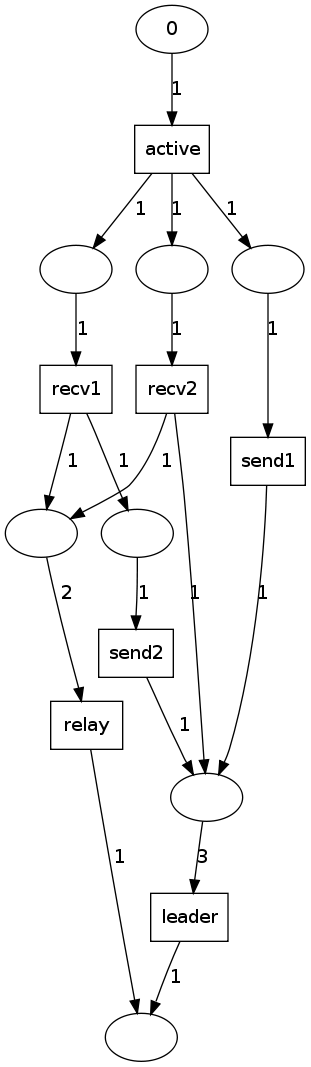
We could condense most of the initial runs of every node, resulting in an overall condensation of arround 30%. Further runs (i.e. mid and end range of the trace) could often not be condensed, because the net does not capture the fact that instead of relay, the net could produce active, in which case, for example, sent2 could be delayed until after active. We were not able to mine any properties suggesting this behaviour. The problems here reveal a weakness of the property miner: The properties in mid and end range of traces are less accurate, and often not mined. In particular, since every trace begins with active all properties of the form active AP * are meaningless.
Finally we tried to construct the petri net inline from the traces by parallelizing any events for which we had not mined explicit ordering invariants. The result is shown below:

To demonstrate that the process suffers from missing invariants (i.e. invariants that hold, but that we could not mine) we did the process again using explicitly distinct fwd1/fwd2 messages in relay state:

- Improve invariant miner