{kind=link}
{kind=link}
{kind=link}
A Markov Decision Process (MDP) based implementation of a Pacman agent, to survive and battle through a handicapped stochastic environment
If AI chooses to move to a particular direction:
- It moves to the direction intended 80% of the time
- However, in 20% of the time, it may move to a direction which is perpendicular to the original intended direction.
For instance, if PACMAN chooses to move UP, there is a 80% chance it will do so, however, a 10% chance it may move left, and 10% to the right (not originally intended).
The Value Iteration algorithm is used in each time step of the game to calculate the max expected utility of all possible action.It uses the bellman equation to calculate utility of each possible action from a given state, by taking into account non‐determinism of the game and outputs the actions which yields maximum expected utility along with its value. Once this is computed, the action with the max value is chosen.
Discount factor represents to what degree of importance the AI places on the future for each decision it makes

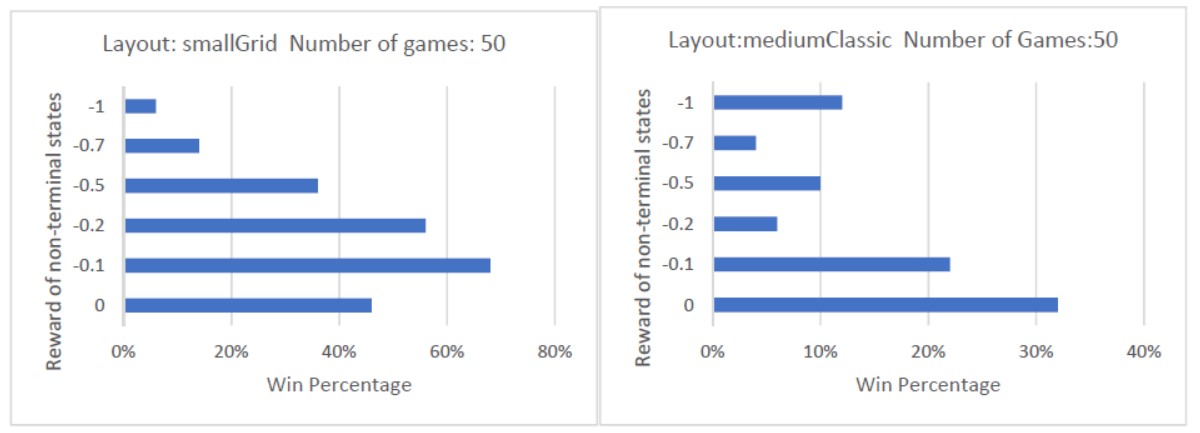
Blank states represents blank cells within the board (have neither of the following: capsule, food, ghost, wall, ghost). Assigning a very small negative reward to such a state may incentivize the Pacman agent to pursue its goal quicker and discourage it from lingering around blank cells which do not have any reward.
The chart below demonstrates different reward values of blank states,tested against win percentages.
 It can be noticed that iterations as small as 100 is good enough for small grid, however for larger layouts such as ‘mediumClassic’, it can be noticed that there is a lot to gain from a higher number of iterations, as increasing iterations from 1000 to 2000 results in dramatic increase of about 15% win.
It can be noticed that iterations as small as 100 is good enough for small grid, however for larger layouts such as ‘mediumClassic’, it can be noticed that there is a lot to gain from a higher number of iterations, as increasing iterations from 1000 to 2000 results in dramatic increase of about 15% win.
python pacman.py -q -n 1 -p MDPAgent -l <grid name>
# example
python pacman.py -q -n 1 -p MDPAgent -l mediumClassic