[Bounty] Headless browser for fetching Proof Post #40 #44
Conversation
| go router.Run() | ||
|
|
||
| page = page.Timeout(timeoutDuration) | ||
| if err := page.WaitLoad(); err != nil { |
There was a problem hiding this comment.
Will this WaitLoad() handles in-page XHR correctly?
I mean, will it "wait" for enough time to let the page load itself completely?
There was a problem hiding this comment.
After I read the code of go-rod, this WaitLoad() waits only for window.onload. This will cause a bug when the target page has XHR. I'll fix this problem by waiting for XHR after window.onload.
|
@nykma I made the api wait for |
|
@synycboom Thank you for the hard work! Would you be interested in attending our EN Community Call tmr via Telegram group video call? Date: GMT+8, 11:00am-12:00pm, Wednesday Sharing details regarding your PR on the headless browser. Add me on Telegram: BinaryHB0916 |
headless/find.go
Outdated
| } | ||
| } | ||
|
|
||
| c.JSON(http.StatusOK, FindRespond{Found: true}) |
There was a problem hiding this comment.
We need to get the full content of query result in response.
for example, here's a request:
{
"location": "https://www.minds.com/newsfeed/1421043369127186449",
"timeout": "30s",
"match": {
"type": "regexp",
"regexp": {
"selector": "*",
"value": "Sig"
}
}
}This service will respond with found: true, which is pretty good.
But what upstream indeed cares is the whole post content (contents after Sig: in this post).
So we need to return it in API response.
There was a problem hiding this comment.
Or, at least, if I define type: regexp with search condition: ^Sig: .*$, the whole matched substring should be returned in API response.
Same for xpath and js selector: the node's content should be returned. Then proof_service upstream will have a chance to verify the signature in it.
There was a problem hiding this comment.
if we really want to capture part of the content in the node (in case of regexp), normally we should define capturing group(s) in regex as it is more easy to cut the content. However, in my opinion, the returned value from this API should be consistent for all match types. For example, it might return the node's content regardless of what match type. I'm not sure whether you are okay about it. What do you think?
I'm going to change the code to return the node's content instead of a boolean.
There was a problem hiding this comment.
the returned value from this API should be consistent for all match types.
Agree.
it might return the node's content regardless of what match type.
Yeah this is what I think. Even "kinda dirty" match result [1] returned can be tolerated, because all proof_service upstream wants is basiclly only one line: Sig: BASE64_SIGNATURE .
[1]: like some <div> tag is mixed into the returned result.
|
I updated what we have discussed in the comments, test cases and PR details. |
|
Congrats, your important contribution to this open-source project has earned you a GitPOAP! GitPOAP: 2022 Next.ID Contributor: Head to gitpoap.io & connect your GitHub account to mint! Learn more about GitPOAPs here. |
Why do we need this changes?
I'm adding a headless browser service to the
proof_serverto enable proof finding by using the headless browser. This PR uses go-rod [https://github.com/go-rod/rod] as a driver for the headless browser. I saw that this repo uses AWS lambda to deploy the services, so I try to support it. Since the headless browser service requires the headless browser execution file, it must be deployed using docker image instead and it is not fully tested on lambda (it is based on https://github.com/YoungiiJC/go-rod-aws-lambda).Design Specs
The new headless browser service has two APIs.
/healthz(for health check)/v1/findThe parameters for the find API have three match types which are described below.
Note that all three match types above are trying to find the same thing which is the text shown in this picture
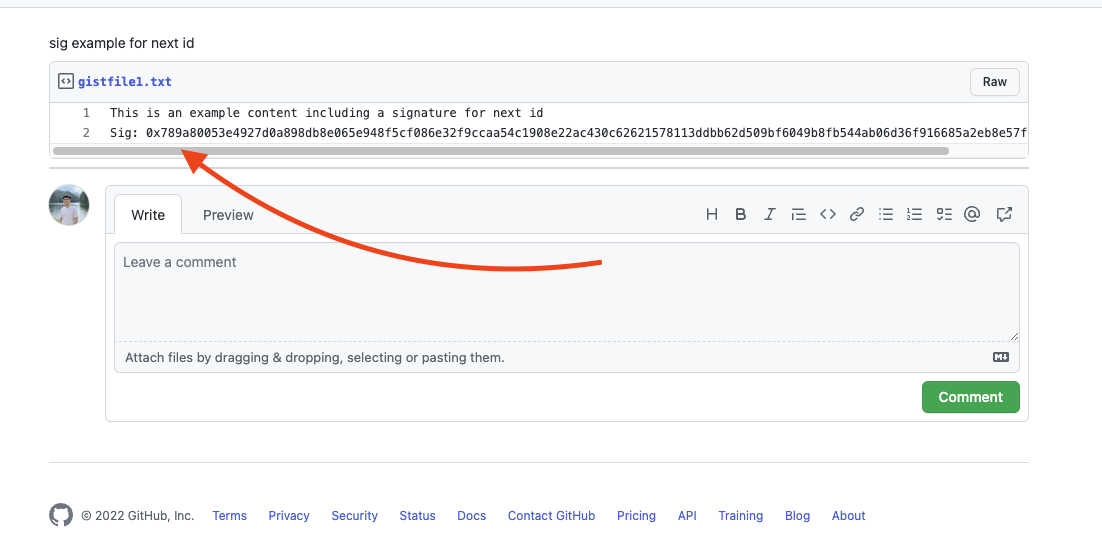
Example Usage