Server Architecture
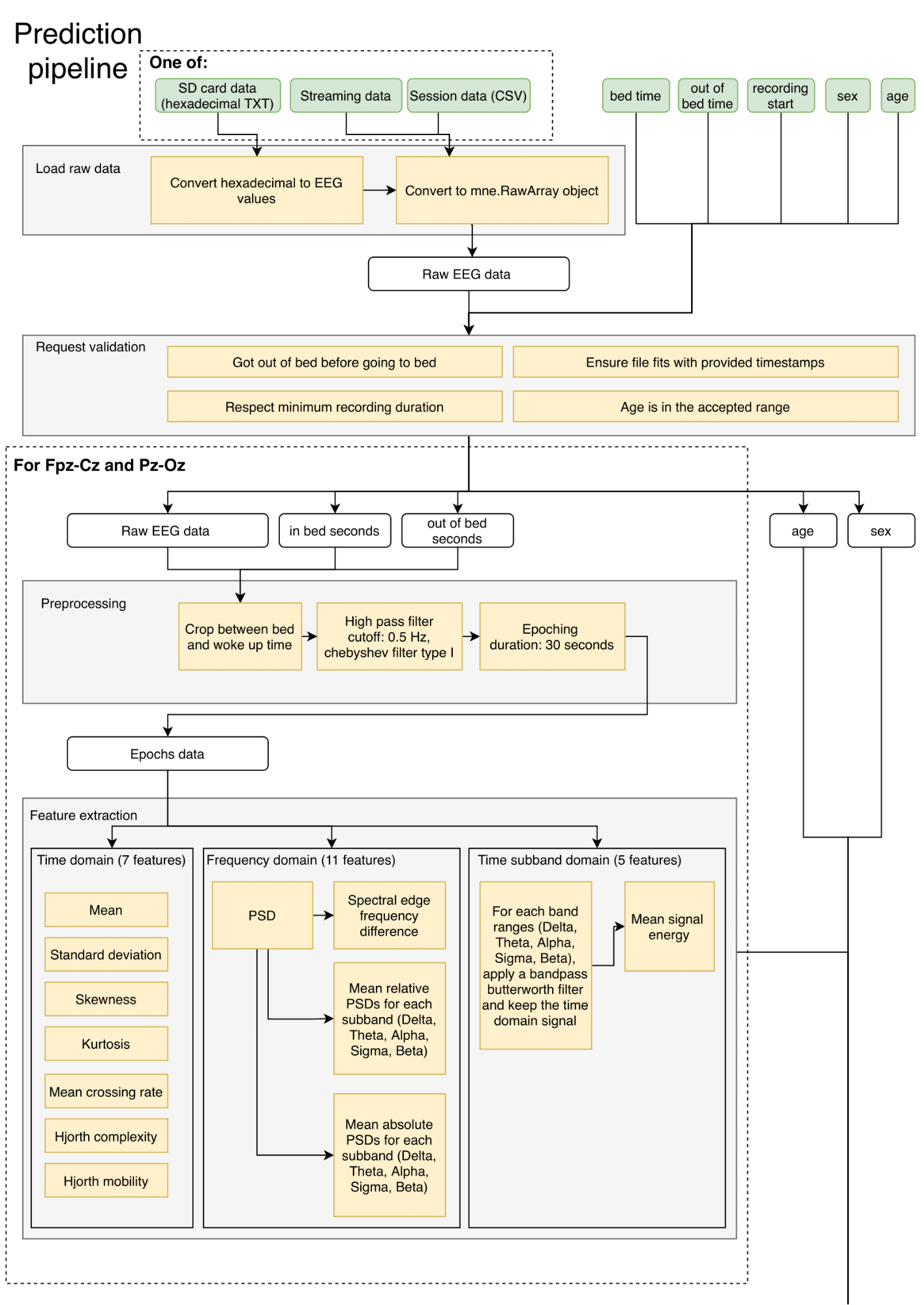
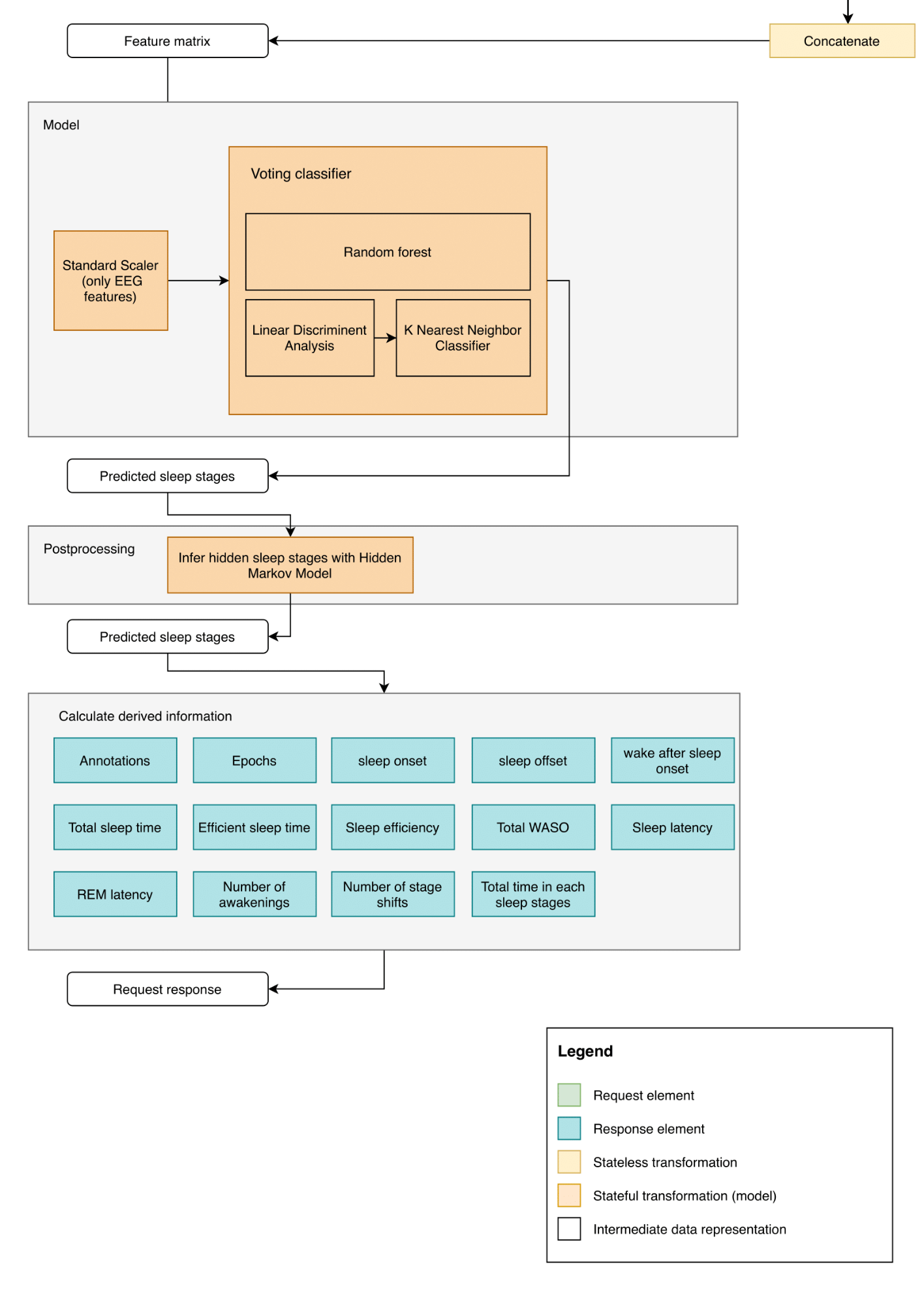
Our server is composed of a single endpoint, that allows the classification of sleep stages based on EEG data. It is is therefore mainly composed of the data classification pipeline. You can find a detailed diagram of it's parts at the end of this page. Its architecture is described in length in the Classification Model & Pipeline wiki page.
In short, the stages of the pipeline are the following:
- Loading of the raw data
- Validation of the input data
- Pre-processing
- Feature extraction
- Classification
- Post-processing
- Metrics calculation
Our architecture meets the need to support different acquisition boards (which have different sampling frequencies) and different data formats. In fact, since the first step in the pipeline is to standardize the data in the same format (i.e. an mne.RawArray object), the rest of the pipeline is agnostic of the original data format, platform and acquisition card. Again, for more information on the choices behind this classification pipeline, the Classification Model wiki page contains detailed explanations of the steps taken to develop our model for classifying EEG data into sleep stages.