- 完成网络爬虫系统设计,系统应包括:抓取网页、分析网页、判断相关度、保存网页信息、数据库设计和存储、多线程设计等。
- 设计基于多线程的网络爬虫。
- 通过http将待爬取URL列表对应的URL网页代码提取出来。
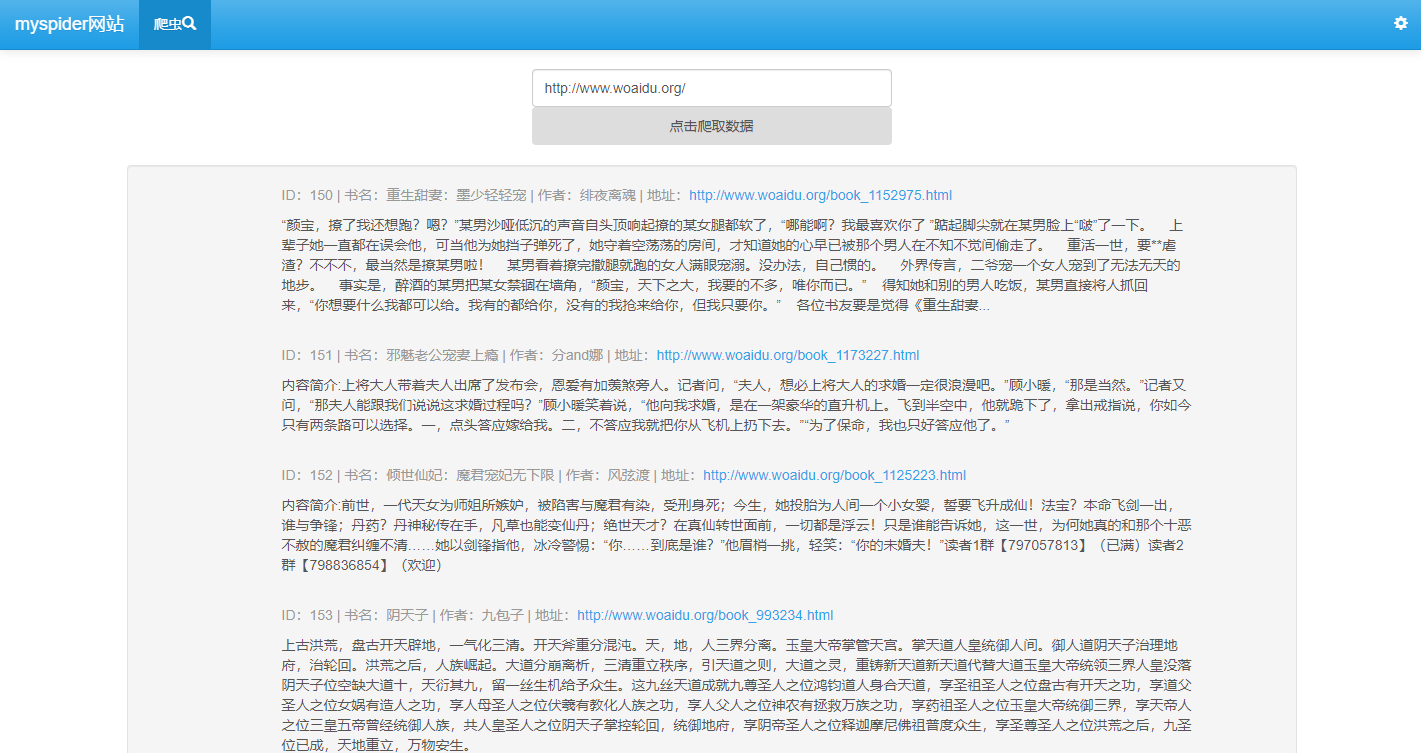
- 提取所有需要的信息并且通过算法判断网页是否和设定的主题相关。
- 广度优化搜索,从网页中某个链接发出,访问该链接网页上的所有链接,访问完成后,再通过递归算法实现下一层的访问,重复以上步骤。
Django 2.2
class MyCrawler():
def __init__(self, seeds):
self.current_deepth = 1
# 初始化book列表
self.books = []
# 使用种子初始化url队列
self.linkQuence = linkQuence()
# 加锁,保护数据
self.lock = Lock()
# 线程池
self.url_queue = queue.Queue()
if isinstance(seeds, str):
self.linkQuence.addUnvisitedUrl(seeds)
if isinstance(seeds, list):
for i in seeds:
self.linkQuence.addUnvisitedUrl(i)
print("Add the seeds url \"%s\" to the unvisited url list" % str(self.linkQuence.unVisited))
# 抓取过程主函数
def crawling(self, seeds, crawl_count):
# 广度搜索
# 循环条件:待抓取的链接不空且专区的网页不多于crawl_count
while self.linkQuence.unVisitedUrlsEnmpy() is False and self.current_deepth <= crawl_count:
# 队头url出队列
visitUrl = self.linkQuence.unVisitedUrlDeQuence()
print("队头url出队列: \"%s\"" % visitUrl)
if visitUrl is None or visitUrl == "":
continue
# 获取超链接
links = self.getHyperLinks(visitUrl)
# 获取链接为空则跳过
if links is None:
continue
print("获取新链接个数: %d" % len(links))
# 将url放入已访问的url中
self.linkQuence.addVisitedUrl(visitUrl)
print("已访问网站数: " + str(self.linkQuence.getVisitedUrlCount()))
# 未访问的url入列
for link in links:
self.linkQuence.addUnvisitedUrl(link)
print("未访问的网站数: %d" % len(self.linkQuence.getUnvisitedUrl()))
self.current_deepth += 1
print("总的book数: %d" % self.books.__len__())
# 多线程采集book
for book in self.books:
self.url_queue.put(book)
spider_list = []
for i in range(20):
try:
t1 = Thread(target=self.getPageData, args=())
t1.start()
spider_list.append(t1)
except:
i += 1
for spider in spider_list:
spider.join()
# 获取源码中得超链接
def getHyperLinks(self, url, ua_agent='Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'):
try:
print('1这里执行了..')
links = []
# 随机休眠一定时间
time.sleep(random.random() * 2)
# request头部信息
header = {'User-Agent': ua_agent}
print('2这里执行了..')
# 获取源码
html = requests.get(url, timeout=30, headers=header, verify=False)
html.encoding = 'utf-8'
urls = re.findall(r'href="(.*?)"', html.text)
print('3这里执行了..')
for ur in urls:
# print('3这里执行了..')
# print('+'*50,ur)
# 如果以【/book_】开头则是想要的book网址
if ur.startswith('/book_'):
bookUrl = 'http://www.woaidu.org' + ur
# 查重,book列表如果已经存在该链接则不再添加
if self.books.__contains__(bookUrl):
continue
# 添加到book列表
self.books.insert(0, bookUrl)
# 相关性判断,判断是否和所设定的网址有关系
elif (ur.endswith('.html') and '/book_' not in ur) or 'www.woaidu.org/' in ur:
# print('>'*50,ur)
if not ur.startswith('http'):
ur2 = url + ur
else:
ur2 = ur
# 添加相关的网址链接
links.append(ur2)
print('4这里执行了..')
return links
except Exception as e:
print('没有获得超链接...')
return None
def getPageData(self, ua_agent='Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'):
while not self.url_queue.empty():
url_data = self.url_queue.get()
# print(url_data)
header = {'User-Agent': ua_agent}
html = requests.get(url_data, verify=False, headers=header)
html.encoding = 'utf-8'
with self.lock:
if html.status_code == 200:
# 通过正则表达式,抓取跟主题相关的内容
# print(html.text)
nam = re.findall(r'<title>(.*?) txt电子书下载 - 我爱读电子书 - 我爱读', html.text)
author = re.findall(r'作者:(.*?)\n', html.text)
# summay = re.findall(r'(.*?)</p>', html.text, re.S)
summay = re.findall(r'<p class="listcolor descrition" style="padding: 10px;">(.*?)</p>', html.text,
re.S)
# 查重,根据book的url判断是否已经在数据库当中
if Book.objects.filter(url=url_data).exists():
print("数据库已经存在该书:" + url_data)
else:
print('往Book表中存取的数据:', nam[0].strip(), author[0].strip(), url_data, summay[0].strip())
book = Book.objects.create(name=nam[0].strip(), author=author[0].strip(), url=url_data,
brief=summay[0].strip())
# 获取刚插入的book_id
book_id = book.pk
print('book_id:', book_id)
book.save()
# 获取下载地址
down_urls = re.findall(r'<a rel="nofollow" href=(.*) target="_blank">点击下载</a>', html.text)
# 获取更新时间
print('down_urls', down_urls)
up_times = re.findall(r'div class="ziziziz">(\d+-\d+-\d+)</div', html.text)
print('up_times', up_times)
new_sources = []
# 获取来源
for old_url in down_urls:
# 获取第一个参数
one_info = re.findall(r'_([^_]+)', old_url)[0]
# 获取第二个参数
twq_info = re.findall(r'_([^_]+)', old_url)[1].split()[0][:-1]
sources = re.findall(
r'a rel="nofollow" href="https://txt.woaidu.org/bookdownload_bookid_{}_snatchid_{}.html" target="_blank">(.*?)</a>'.format(
one_info, twq_info), html.text)[0]
new_sources.append(sources)
for source, up_time, down_url in zip(new_sources, up_times, down_urls):
print('往DownUrl表中存取的数据:', book_id, source, up_time, down_url.strip('""'))
down = DownUrl.objects.create(book_id=book_id, source=source, update_time=up_time,
down_url=down_url.strip('""'))
down.save()
class linkQuence():
def __init__(self):
# 已访问的url集合
self.visted = []
# 待访问的url集合
self.unVisited = []
# 获取访问过的url队列
def getVisitedUrl(self):
return self.visted
# 获取未访问的url队列
def getUnvisitedUrl(self):
return self.unVisited
# 添加到访问过得url队列中
def addVisitedUrl(self, url):
self.visted.append(url)
# 移除访问过得url
def removeVisitedUrl(self, url):
self.visted.remove(url)
# 未访问过得url出队列
def unVisitedUrlDeQuence(self):
try:
return self.unVisited.pop()
except:
return None
# 保证每个url只被访问一次
def addUnvisitedUrl(self, url):
if url != "" and url not in self.visted and url not in self.unVisited:
self.unVisited.insert(0, url)
# 获得已访问的url数目
def getVisitedUrlCount(self):
return len(self.visted)
# 获得未访问的url数目
def getUnvistedUrlCount(self):
return len(self.unVisited)
# 判断未访问的url队列是否为空
def unVisitedUrlsEnmpy(self):
return len(self.unVisited) == 0