In this, we use different resources and their variants of implementations of GhostNet to understand the architecture and performance of GhostNet.
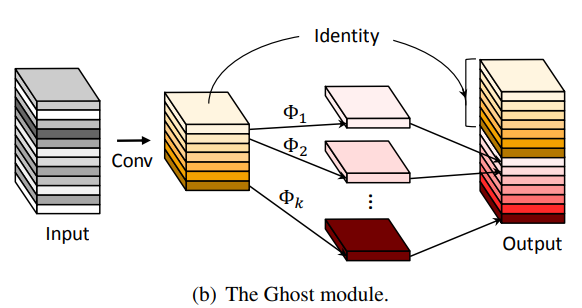
In GhostNet, we introduce a module which utilizes a few small filters to generate more feature maps from the original Conv layer and then develop GhostNet with an extremely efficient architecture and performance.
A Conv Layer is defined by number of input channels tensor of feature maps and many redundant copies of it remain. So, GhostNet generate x% of the total output feature maps, while the remaining are created by a cheap linear operation.
This cheap linear operation results in massive reduction in model parameters and FLOPs while retaining the same performance as of the original baseline model.
GhostNet uses Depthwise Convolution (DWConv) as its cheap linear transformation
Using the GhostModules, Ghost Bottleneck G-bneck is introduced which has two stacked Ghost modules.
- First Ghost module acts as an
expansionlayer increasing the number of channels known asexpansion ratio. - Second Ghost module reduces the number of channels to match the
shortcut path.
Now, the shortcut is connected between the inputs and outputs of these two Ghost Modules. Shortcut path is implemented by
- DownSampling layer
- Depthwise Convolution.
- In primary convolution, Ghost Module is a
Pointwise Convolution.
Following on the G-Bottleneck, a GhostNet is presented in which MobileNetV3 architecture is followed.
We replace the Bottleneck part of the MobileNetV3 and replace it with our GhostBottleneck
- First layer is a
Convlayer with 16 filters - Followed by a series of
Ghost Bottleneckswith gradually increased channels. - These
G-Bnecksare grouped into different stages according to the size of theirinput feature map. - All
G-Bnecksare applied withstride=1except the last one in each stage is withstride=2. - At last a
GlobalAveragePool2dand aConvare used to transform the feature maps into a feature vector.
In contrast to MobileNetV3, large latency.
To customize the Model for some scenarios, we multiply a factor
Factor Width Multiplier as it can change the width of the entire network. It can control
- Model size
- Computational cost
Usually
For more information refer to these links
- Official Implementation:- https://github.com/huawei-noah/Efficient-AI-Backbones
- Original Arxiv Paper: https://arxiv.org/pdf/1911.11907.pdf
- Paperspace Blog:- https://blog.paperspace.com/ghostnet-cvpr-2020/
- Review of GhostNet:- https://sh-tsang.medium.com/review-ghostnet-more-features-from-cheap-operations-1784f3bbc2b
<bound method Module.parameters of GhostNet(
(features): Sequential(
(0): Sequential(
(0): Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(2): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(16, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(24, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=24, bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential(
(0): Conv2d(48, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=48, bias=False)
(1): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(48, 12, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=12, bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential(
(0): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(1): Conv2d(16, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(24, 36, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(36, 36, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=36, bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(72, 12, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=12, bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(4): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(24, 36, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(36, 36, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=36, bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential(
(0): Conv2d(72, 72, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=72, bias=False)
(1): BatchNorm2d(72, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(2): SELayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=72, out_features=18, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=18, out_features=72, bias=True)
)
)
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(72, 20, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(20, 20, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=20, bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential(
(0): Sequential(
(0): Conv2d(24, 24, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=24, bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(1): Conv2d(24, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(40, 60, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(60, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(60, 60, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=60, bias=False)
(1): BatchNorm2d(60, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): SELayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=120, out_features=30, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=30, out_features=120, bias=True)
)
)
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(120, 20, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(20, 20, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=20, bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(6): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(40, 120, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(120, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=120, bias=False)
(1): BatchNorm2d(120, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential(
(0): Conv2d(240, 240, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential(
(0): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(1): Conv2d(40, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 100, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(200, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(8): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 92, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(92, 92, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=92, bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(184, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(9): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 92, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(92, 92, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=92, bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(184, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(10): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(240, 240, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): SELayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=480, out_features=120, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=120, out_features=480, bias=True)
)
)
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(480, 56, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(56, 56, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=56, bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential(
(0): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(1): Conv2d(80, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(11): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(112, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(336, 336, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=336, bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): SELayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=672, out_features=168, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=168, out_features=672, bias=True)
)
)
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(672, 56, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(56, 56, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=56, bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(12): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(112, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(336, 336, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=336, bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential(
(0): Conv2d(672, 672, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(2): SELayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=672, out_features=168, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=168, out_features=672, bias=True)
)
)
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(672, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential(
(0): Sequential(
(0): Conv2d(112, 112, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=112, bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(1): Conv2d(112, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(13): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(960, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(14): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): SELayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=960, out_features=240, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=240, out_features=960, bias=True)
)
)
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(960, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(15): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Sequential()
(2): Sequential()
(3): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(960, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
)
(shortcut): Sequential()
)
(16): GhostBottleneck(
(conv): Sequential(
(0): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): AdaptiveAvgPool2d(output_size=(1, 1))
)
(classifier): Sequential(
(0): Linear(in_features=960, out_features=1280, bias=False)
(1): BatchNorm1d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.2, inplace=False)
(4): Linear(in_features=1280, out_features=1000, bias=True)
)
)>
- Review and understand
GhostNetV2.
GhostNetV2 was also proposed in CVPR 2022
- https://arxiv.org/abs/2211.12905 [GhostNetV2 Paper]
- https://github.com/likyoo/GhostNetV2-PyTorch [Implementation]