Presence Broadcast leads to clients flood front-end with long pooling XHR requests with websocket correctly configured #17559
Comments
|
sockjs supports multiple transports according to https://github.com/sockjs/sockjs-client#supported-transports-by-browser-html-served-from-http-or-https |
|
|
|
in case browser cannot establish a web socket connection, Meteor automatically a falls back to long pooling XHR requests.. probably you'll need to check your reverse proxy websockets settings to find the root of this issue.. some links for reference: https://forums.meteor.com/t/xhr-xhr-send-spam-on-production-server/43312/2 |
|
Seems like it must be a bit hit or miss then. As OP says, it is all good after a refresh. If it works only sometimes I can't entirely see that still being a reverse proxy issue.
|
|
@sampaiodiego
As @Beeez noticed we have reverse proxy (Nginx) correct configured and a major of clients works perfect with websocket and problem clients do after refresh. |
|
@sampaiodiego @tassoevan
First was can be not so good for users - for example they can lose their message on connection upgrade (I'm not sure they will, but anyway) |
I do not see the advantage of using ip_hash over a cookie-based method. I cannot say whether this should make a difference, but I expect it to balance your users more evenly because every single connection is considered compared to just the originating IP address (which could mask users behind NAT). |
You are totally right about that. And we also have a proxy users in our organisation, so all of them are represented by single IP address, but
So we use free Nginx version with ip_hash for sticky sessions. |
What a bummer, I did read to the end. Should you need a (presumably) working HAProxy config I share mine. |
Thanks a lot for that, by the way! |
Do you have any specific sections for websockets? Perhaps in ours we might be missing something - though again, since it works like 90% of the time i can't imagine it is a problem with our config. |
|
@Beeez Not in HAProxy, no. My understanding is that Haproxy handles websocket connections transparently. |
|
So in one regard Rocket.Chat client is responding appropriately as concluded above. Some reason websocket isn't established and so falls back to the other way, basically assuming that the websocket must not work. Ok so now ignoring that for now and focusing specifically on the websocket. Can you determine how well your proxy is balancing among your Rocket.Chat instances?
Is this happening a lot? Are Rocket.Chat instances going unavailable? I'm not sure how nginx handles the sticky.. but does it add any sort of header on the response or a cookie so can see how its routing? Would be interesting to see if the websocket hits the same server as the xhr requests. Do you have any sort of liveness check on your actual instances running? To make sure that they are actually responding? It could be some are stickied to an instance that is messed up in some way and when the xhr happens nginx is some how hitting a different instance? |
|
@geekgonecrazy We use Haproxy Stats page that can show availability and when the XHR flooding starts, I see no failing health checks, with 60-80 people on the same instance as I am. All of our backends have 3 days uptime (last automated rolling nightly reboots). The sticky session cookie is the same as in the xhr headers. We dont use nginx as @ankar84 does, but we still see the same issues. |
Interesting.. what does the load look like on the others? I'm just trying to understand if something might be causing the websocket not to upgrade in the Rocket.Chat code base. Also if you get others having this issue.. do they seem to have the same instance as you do? |
|
Hi, @geekgonecrazy and thanks for your attention!
Now we have 2 levels of reverse proxy - 3 proxy of second level behind first level proxy. And 4 RC instances behind second level proxy. Clients distributed to all 12 RC instances by using ip_hash nginx on all two levels of proxy.
Generally. not. But recently I had 2 big RC crash day by day, it's described here. Now we disabled DDP Rate Limiter and implemented sticky sessions and at that moment we have now RC crash.
No, I don't see that in monitoring. All instances state is monitored:
No, instances itself not monitored by some requests, but if Nginx will get 502 or some other bad response, that instance move out from balance pool temporary. First level proxies are monitored by http requests every 10 seconds.
I think answer here is "No". And we see that xhr floods same instance. But after clients refresh (CTRL+R) that xhr flood fixed. And here I don't actually know how - maybe clients connects to different instance and start websocket normally, or maybe clients connects to same instance, but after reconnect upgrade to websocket successfully.
Yes, it seems to my, that it's reverse proxy independent issue. @geekgonecrazy what do you think about suggested solutions? Second way can be something like E2E banner.
|

It is not anything that is stuck to just a single instance. It happens regardless of any single instance. HaProxy for us is doing health checks every ms, so if there was even a single blip, we would know about it in our downtime tracker. |
|
After another crash yesterday #17473 (comment) amount of sockjs clients decreased. |


Hi, @sampaiodiego |
Hi, @geekgonecrazy
|
|
@geekgonecrazy @sampaiodiego UPD. @Beeez can you try to reproduce that in your environment? |
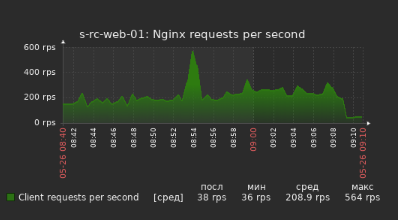

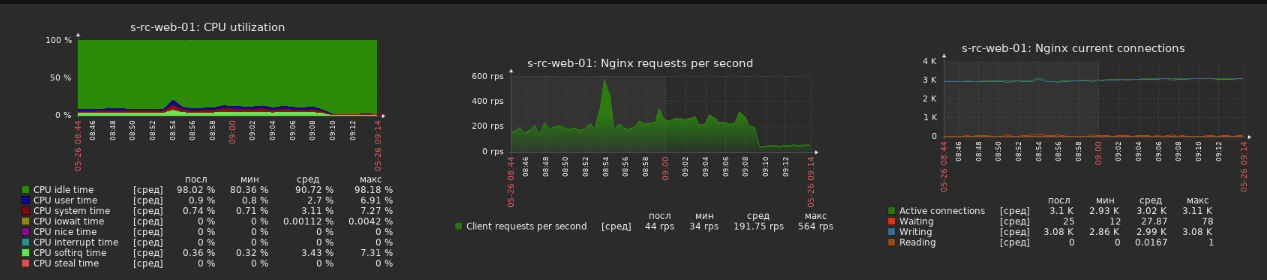


Hi, @summit2020 |
|
@ankar84 , thanks for your reply. I recently came to know that it could be a browser's max. WebSocket connections limit issue. What happens if IE has opened 6+ tabs per host? But I see your issue may not be coming while opening tabs beyond the limit. The reason I see different browsers keep this limit is just to save CPU performance since WebSocket keeps doing something.
|
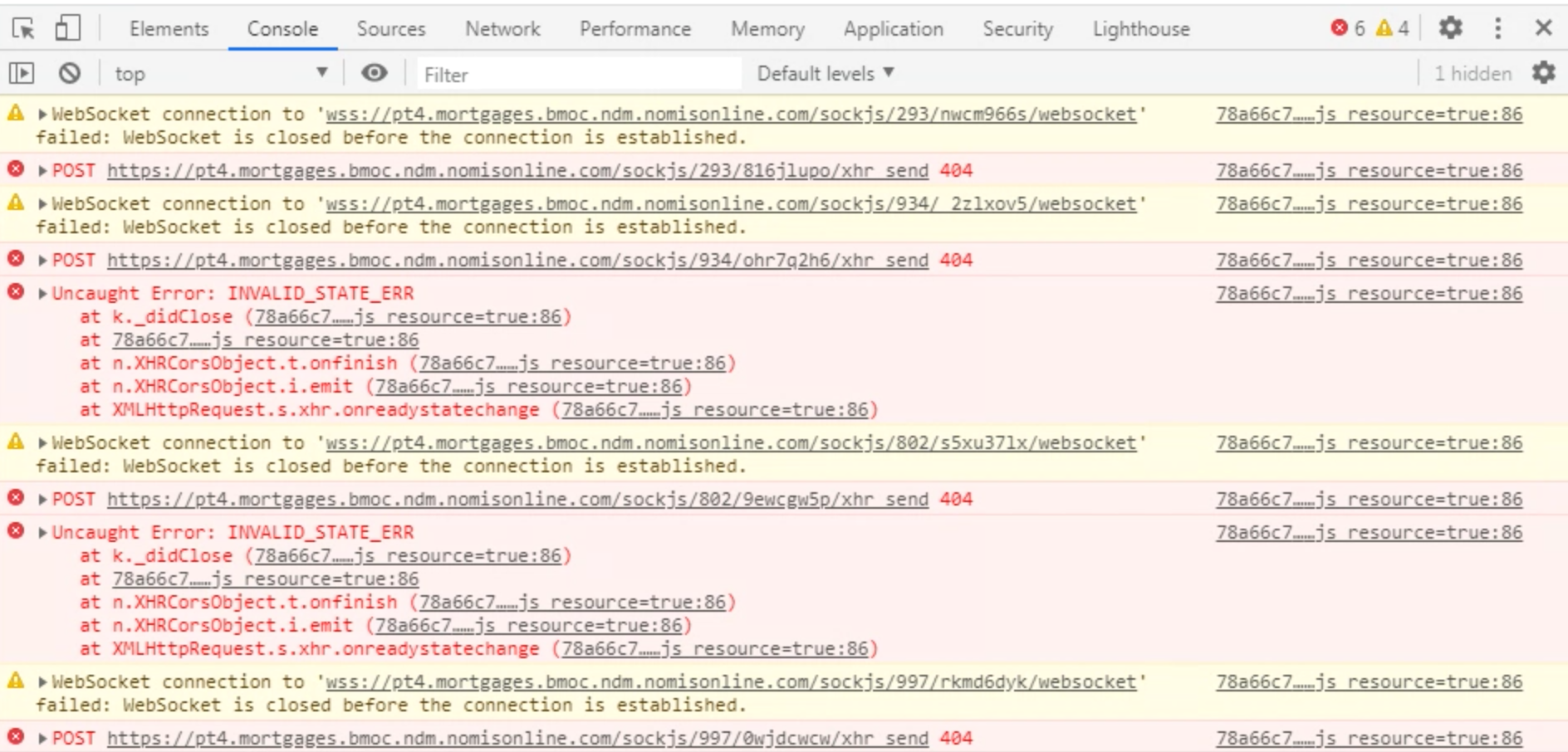
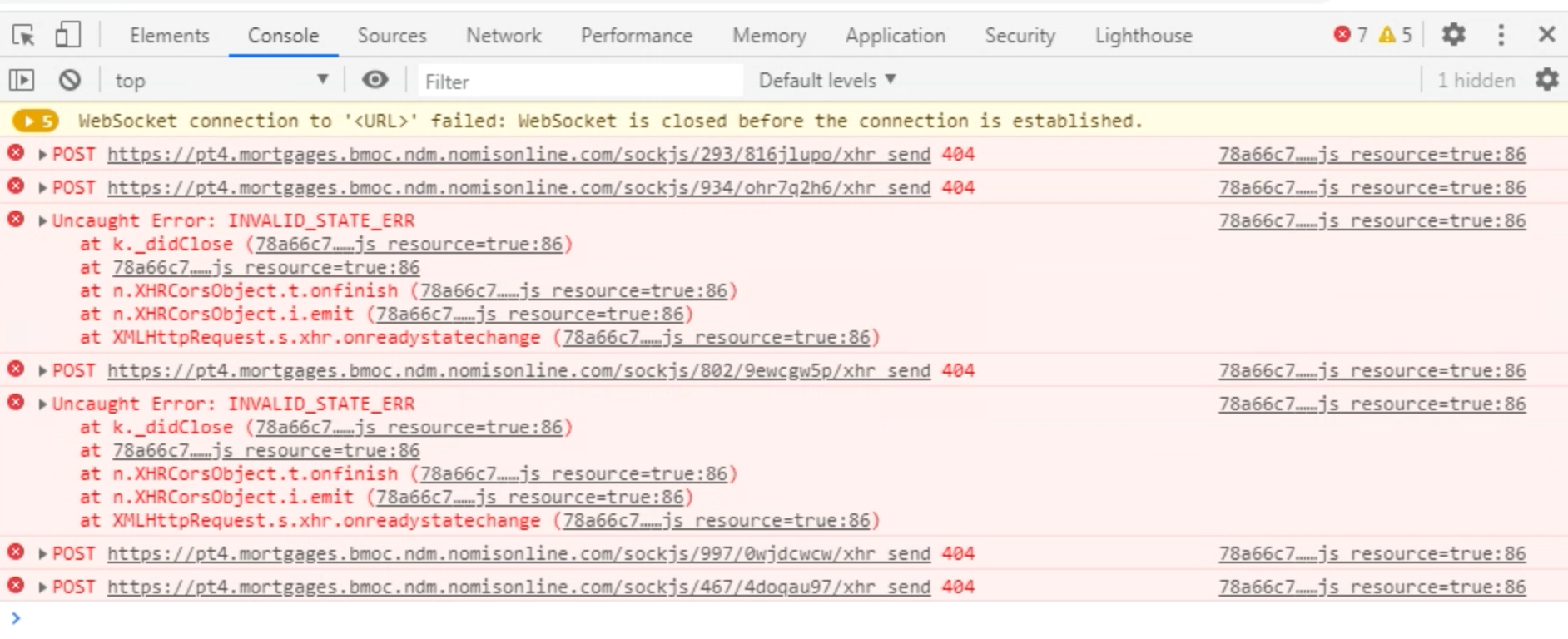
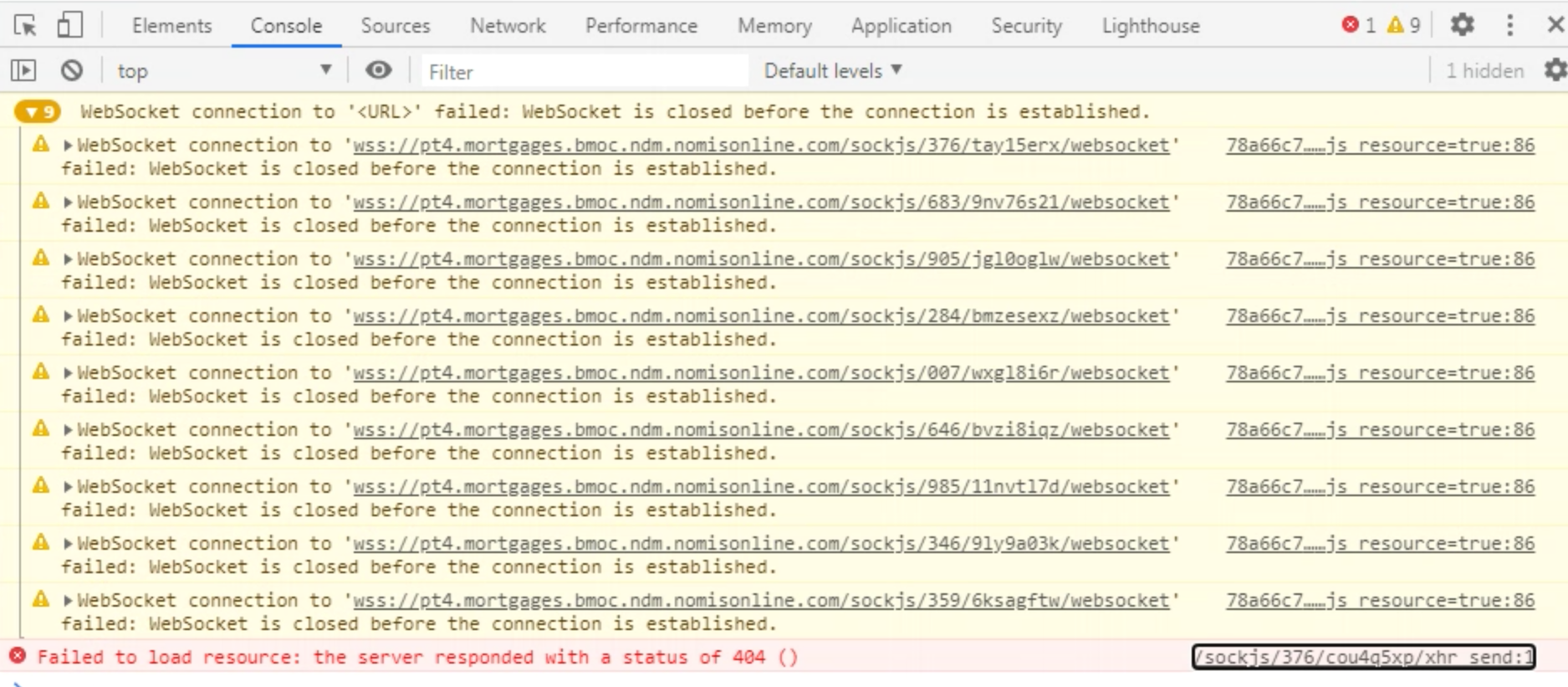
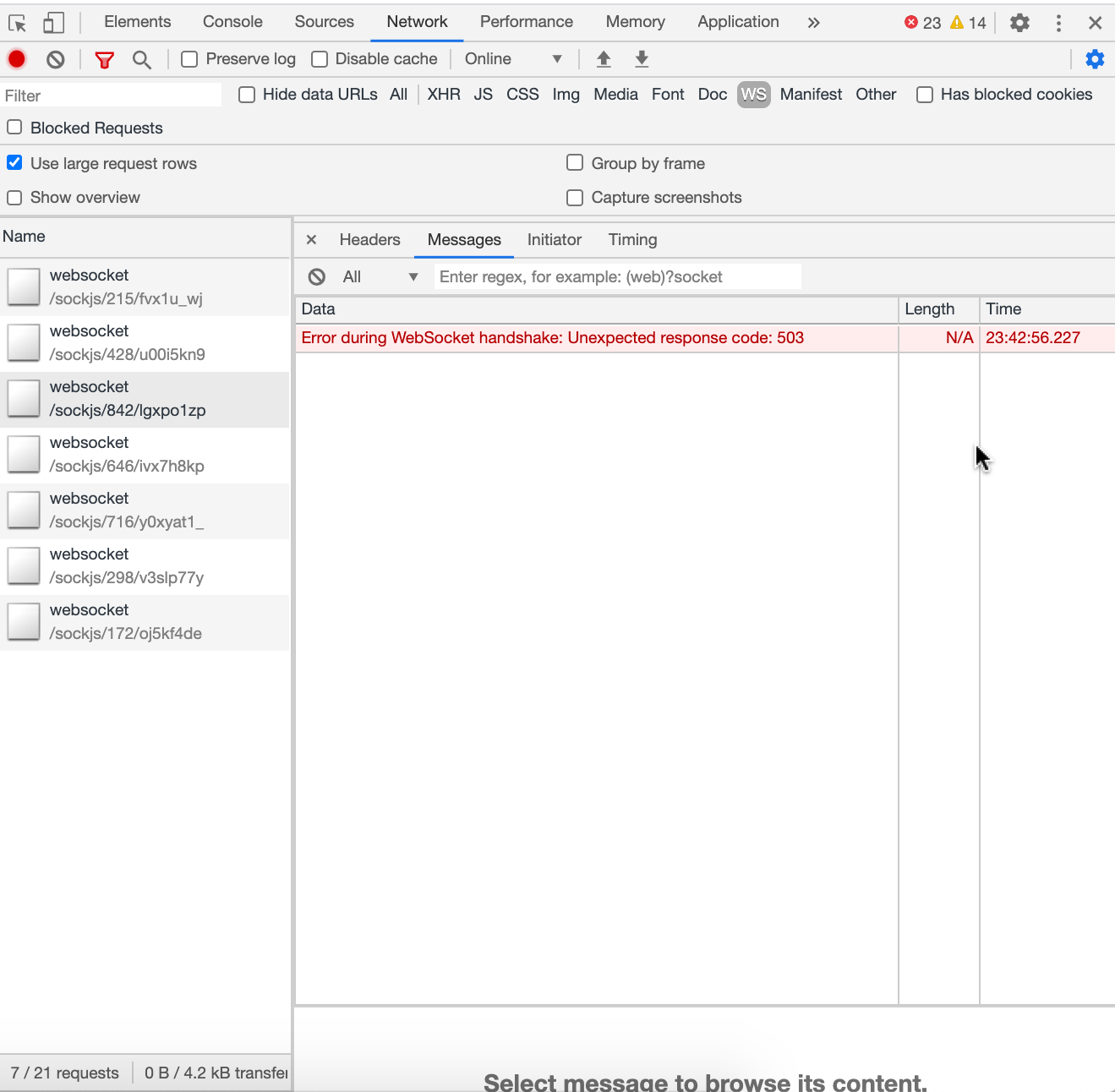
Very interesting research, @summit2020
@geekgonecrazy @sampaiodiego any thoughts about that? |
@geekgonecrazy @sampaiodiego I think I can explain that. So only one question remain open - What cause client to downgrade to XHR? Solution for that problem I suggested here
|
@summit2020 thank you for your great research! |
|
Could we make make use of |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
That is a very important issue, please don't close it. Flood still here |
|
@ankar84 May I have your Email? |
|
sugget :meteor should use always websocket |
|
@ankar84 do you Disable Presence Broadcast ? |
No. It is enabled now and always. |
|
Still an issue in 3.14 version of Rocket.Chat |

|
Still an issue in 3.16.3 |

|
4.2.2 looks much better! |
|
I'm on a 4.2.2 now and looks like that issue is solved now on 4.x branch of server versions. I don't know what actually fixed that, but @sampaiodiego thank you so very very much! |
|
that's great to hear @ankar84 .. to give you a bit of context on what changed, this PR #22950 changed how presence updated were sent.. prior to that, as you noticed, we were sending any presence change to every connected user, which obviously adds a lot data going through the wire.. and now you'll receive update of people you're actually seeing on the screen.. so my guess if that previously you reverse proxy was not able to handle the load and thus disconnecting people very often.. haproxy should be able to handle that, but there are other variables that would require and tweak, idk, even network bandwidth.. |
Description:
I asked that question on open.rocket.chat but I need more details about that issue.
@bbrauns and @benedikt-wegmann adviced me here to implement sticky sessions because it is critical to Meteor. Now we experiencing a big performance issues with Rocket.Chat from time to time and we need to implement all features, that can improve stability and performance.
Right after last crash we enabled that sticky sessions in Nginx with ip_hash so one source IP is sticked to one upstream server.
We see in Nginx logs, that it is working fine.
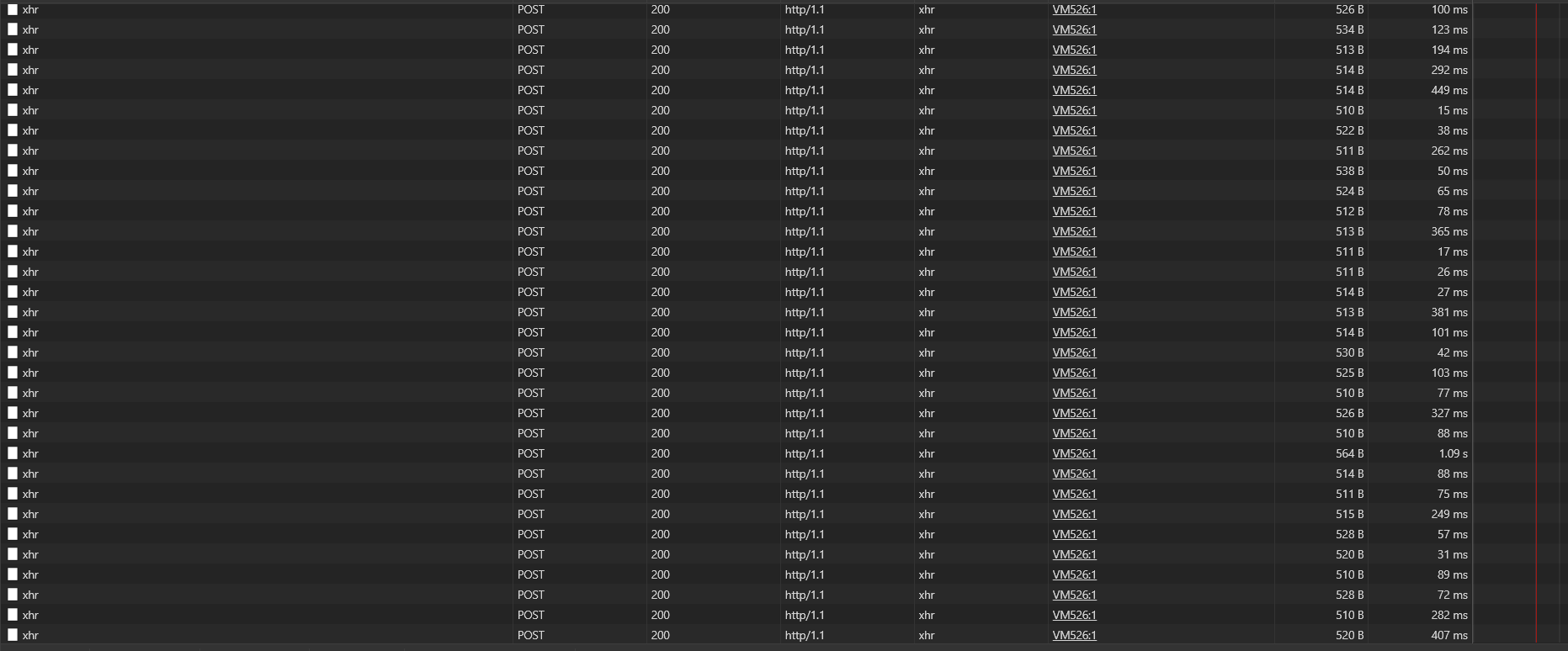
But we have about 300 clients that send every second request like this:
With response like this:
So, it is defiantly not a websocket. But Rocket.Chat works pretty normal for such problem clients.
I don't why!
What is this? Is it some kind of compatibility to websocket or what? JavaScript Socket?
Steps to reproduce:
Expected behavior:
All clients should successfully work via websocket, as most of clients do.
Actual behavior:
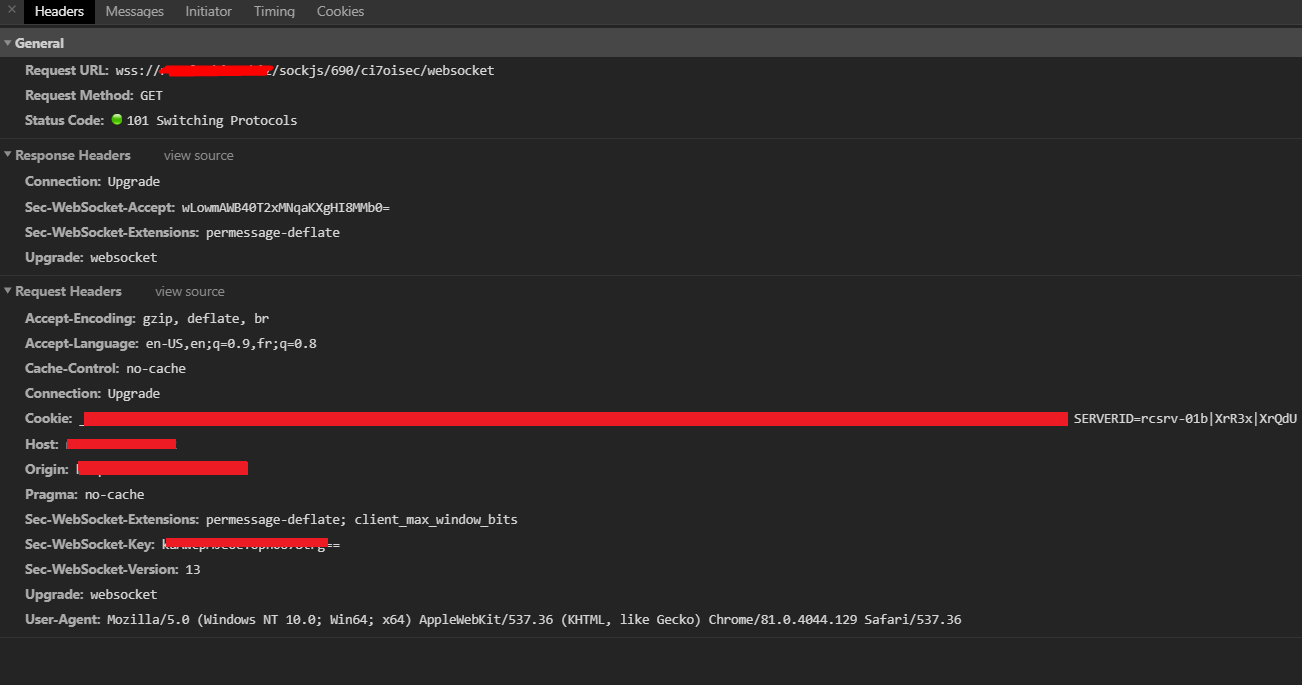
From problem client:
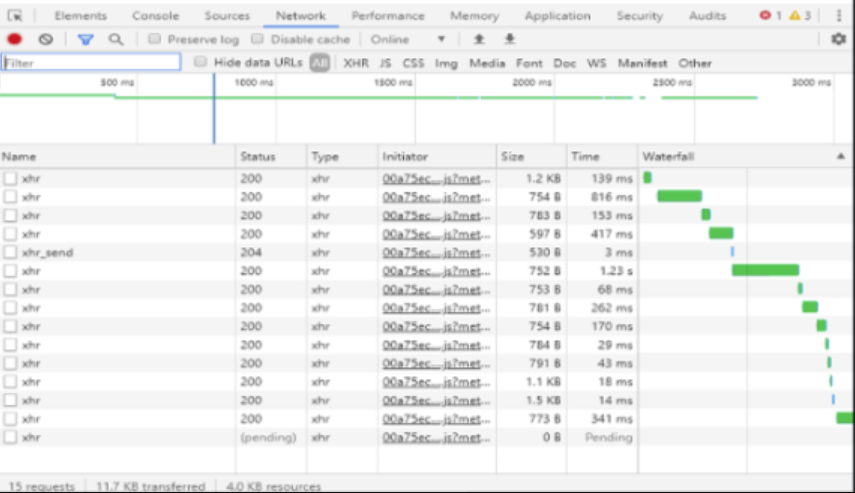
Server Setup Information:
Client Setup Information
Additional context
CTRL+Ron client totally fixed that problem. Just after reload client successfully open websocket (response 101) and request flood stops.But I want to know what exactly is the mode in which problem clients are working and how to fix it permanently?
And what developers think could be the reason for that behavior?
@tassoevan @sampaiodiego please check that issue.
The text was updated successfully, but these errors were encountered: