2. KnetMiner server architecture
Note: see notes at the end about the reasons why we have the architecture described in this page.
KnetMiner consists of several components, as shown in figure 1. This includes:
-
server-datasource-api: a set of core interfaces and components defining Knetminer functionality as a web service. A central concept in this module is the idea of data source, which is a view of the Knetminer API function, implemented on top of a data backend. At the moment, the only implementation we have for a data source is the one based on OXL files (see notes below). -
server-datasource-ondexlocal: An implementation of server-datasource-api based on data fetched from an Ondex.oxlfile and kept in memory. This is the currently only available implementation of the abstract API, so, in practice, we rely on this to provide the API functions. A Knetminer instance based on Ondex can be configured entirely via configuration files, the configuration loading starts with a web listener (usingConfigBootstrapWebListenerin web.xml). -
server-base: this defines a skeleton of a.warJava web application, which mostly mapsserver-datasource-apifunctions to web API URL-based calls. As other modules in Knetminer, this largely based on Spring. The resulting .war is essentially an API based on a web service, which can be accessed programmatically, via HTTP calls. -
client-base: similarly, this contains a skeleton for the Knetminer application that is visible to the end user, hence it defines most of the user interface. -
aratiny: this project and its Maven submodules has a double function:-
when built with the default configuration, which is defined in various Maven POMS, it produces a simple Knetminer instance, which is based on a small demo OXL file (a subset sampled from our Poaceae dataset, the 'ara' name has historical reasons). This kind of building is part of the Knetminer Maven build, which uses this sample application to perform some integration tests by calling the corresponding API. The application is based on
aratiny-wsandaratiny-client, which are concrete extensions ofserver-baseandclient-basementioned above. Such extensions depend onserver-datasource-ondexlocal, ie, they use an OXL and Ondex components as concrete data source. Both the client and the server can be run manually, using scripts inmanual-test, which offer options to run this sample application with different options (eg, using the Neo4j graph traverser). -
aratiny is also a template for building our Knetminer Docker image. This, when launched with its defaults, runs the same sample application over the same small sample dataset. However, a Knetminer Docker container can be configured with data, configuration parameters and user interface customisations about a specific Knetminer dataset (eg, about a given organism) and run a particular Knetminer instance. This is explained in the detail by our Docker documentation. This kind of reconfiguration and instantiation of aratiny is also possible when it's run directly, without Docker (though you should bear in mind we don't test this mode very often).
-
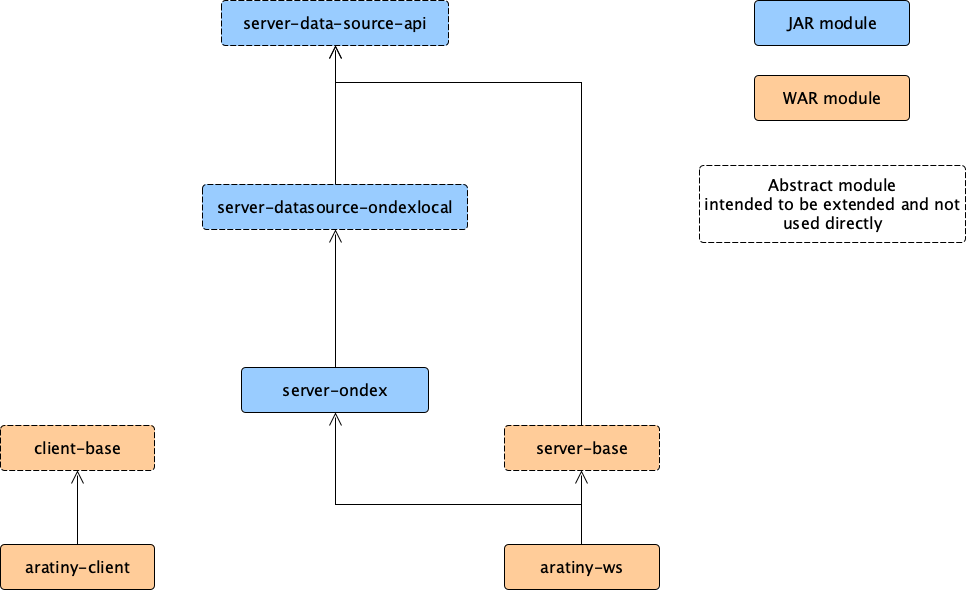 Figure 1: arrangement of the main KnetMiner Maven modules (POM's
Figure 1: arrangement of the main KnetMiner Maven modules (POM's artifactId reported). The dependecies between WAR modules are those established by the overlaying mechanism provided by the Maven WAR plug-in.
As mentioned above, a datasource is a Knetminer API implementation over a data backend, namely the KnetminerDataSource abstract class, and currently, we only have the OXL datasource (OndexLocalDataSource). Data source classes must be annotated with @Component (ie, they're based on Spring) and be in the packages that are configured for Spring to scan (see KnetminerServerConfiguration).
The Ondex-based implementation of this class, OndexLocalDataSource, contains the mechanism to
bootstrap the application configuration using the above-mentioned ConfigBootstrapWebListener, which, in turn, is invoked by the web container when it's set up in the server's web.xml (see aratiny-ws).
To summarise, in most cases you can develop custom instances of Knetminer by working on the aratiny reference app, which already includes a configurable, Ondex-based datasource. Custom options to the latter can be defined in its configuration file.
As mentioned above, a new Knetminer instance can be configured by means of configuration files, which include configuration options regarding the data processing, the API and the user interface. Currently, we always manage one instance per dataset, which means a single OXL file + configuration (what we call a dataset). See the [Docker documentation][10.20] for many more details.
While we recommend to stick to the simple arrangement above, variants would be possible. For instance, the same Tomcat server could be running different copies of the same .war applications described above, in such a case you would just need to ensure things don't conflict (eg, ensure different names and URL paths are used, ensure distinct data paths are used).
To reiterate, KnetMiner makes use of a client-server model, where demanding computation is performed in the web server, and visualisation outputs are performed in the JavaScript-based client. The web server is based upon the Spring MVC framework, using Servlet, Ondex, and Lucene APIs to access the Genome-Scale Knowledge-Network (GSKN, or, simply knowledge networks). The web-client makes use of a range of libraries, including jQuery, KnetMaps.js, and GenoMaps.js for interactive data visualisation.
Within a Knetminer instance, the server is controlled via KnetminerServer in server-base. Incoming requests and outgoing responses are always JSON, the format of which is allowed for by KnetminerRequest and KnetminerResponse in the server-datasource-api. This one class contains all possible input parameters and suitable non-null defaults for each, regardless of which ones are used by which request. Responses are always JSON and defined by implementations of KnetminerResponse in server-datasource-api.
The web server requires, as arguments, the path to the GSKN (OXL format) and the semantic motif files (MGQE format). It pre-indexes the GSKN and waits for requests. The OXL files are built via the [KnetBuilder framework][50] (previously named Ondex).
The overview of this architecture is shown below in Figure 2. This represents the internal architecture of the two .war applications that a default instance of Knetminer (eg, aratiny) consists of. This has to be coupled with details regarding how such an instance is made to work with specific data and a specific user interface. As said above, this is explained in the Docker-related documentation.
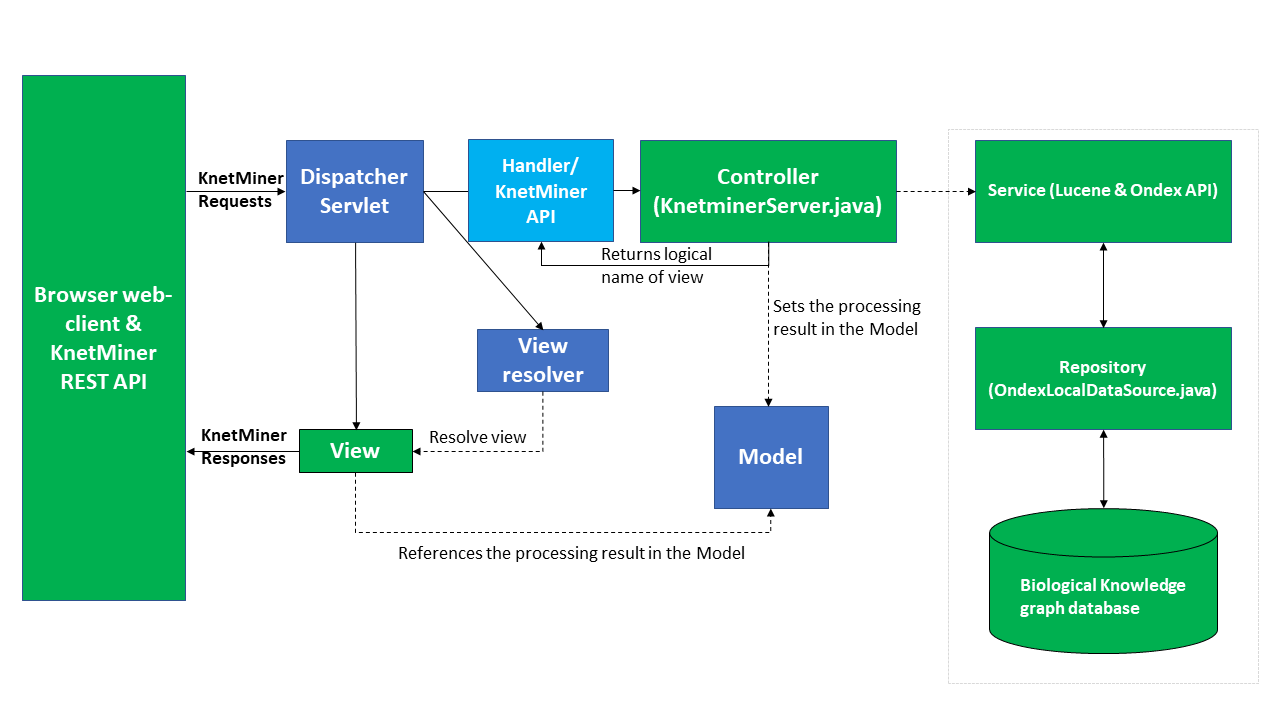 Figure 2: KnetMiner architecture overview, where green processes have been created by us, and dark blue processes are provided by SpringSource. The light blue process is provided by the SpringSource and our own API.
Figure 2: KnetMiner architecture overview, where green processes have been created by us, and dark blue processes are provided by SpringSource. The light blue process is provided by the SpringSource and our own API.
[50] https://github.com/Rothamsted/knetbuilder/wiki
If you're thinking that the Knetminer architecture is too complex for the way it's used, it's because it indeed it indeed has become over-complicated with time.
In fact, initially the Knetminer software was initially designed to support multiple instances of the same API (ie, data sources) implemented on different data backends (eg, OXL, reltional database). Moreover, in the original design each new UI instance was realised as extensions of
the client-base and server-base modules, to have dataset-specific customisations for the two web applications.
Nowadays, we always use the OXL-based data source only (with a variant that partially uses Neo4j, see Semantic-Motif-Searching-in-Knetminer) and we have constrained code extensions to support one data source only per server. The latter is because it is now much easier to distribute data sets over Docker instances and also, while we plan to switch to a graph database backend in future (very likely, Neo4j), that could be implemented with a simpler architecture, where the data source implementation doesn't need to be configurable (although, very likely we will keep the separation between the abstract API and its implementation).
Hence, in future developments we might reduce the number of different modules that Knteminer consists of (ie, one api WAR and one client WAR), and we might simplify the data source idea into a single REST controller class, which has supporting business logic components such as the current OndexServiceProvider.