An optimized K-means implementation for the one-dimensional case.
Exploits the fact that one-dimensional data can be sorted.
For the lower level functions prefixed with numba_, Numba acceleration is used,
so callers can utilize these functions within their own Numba-accelerated functions.
Note that this library is not an implementation of optimal 1D K-means, which is known to be possible through dynamic programming approaches and entails
This library utilizes Numba, a JIT compiler, for acceleration. As there is a compile time overhead, the first invocation may be slower than usual.
Numba caches the compiled functions, so execution times should stabilize after the first invocation.
Guaranteed to find the optimal solution for two clusters by employing a clever binary search.
The algorithm is deterministic.
Uses the K-means++ initialization algorithm to find the initial centroids. Then uses the Lloyd's algorithm to find the final centroids, except with optimizations for the one-dimensional case. The algorithm is non-deterministic, but you can provide a random seed for reproducibility.
For number of elements
-
Two clusters:
$O(\log{n})$
($+ O(n)$ for prefix sum calculation if not provided,$+ O(n \cdot \log {n})$ for sorting if not sorted) -
$k$ clusters:$O(k ^ 2 \cdot \log {k} \cdot \log {n}) + O(i \cdot \log {n} \cdot k)$
(The first term is for K-means++ initialization, and the latter for Lloyd's algorithm)
($+ O(n)$ for prefix sum calculation if not provided,$+ O(n \cdot \log {n})$ for sorting if not sorted)
This is a significant improvement over common K-means implementations.
For example, general implementations for
Note that you must use the underlying numba_ functions directly in order to directly supply prefix sums and skip sorting.
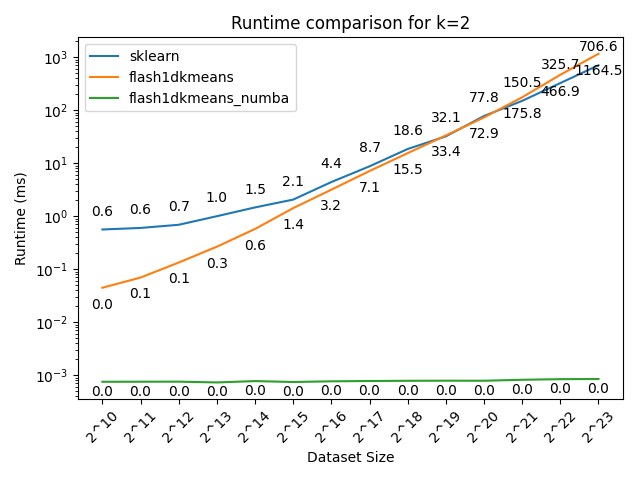
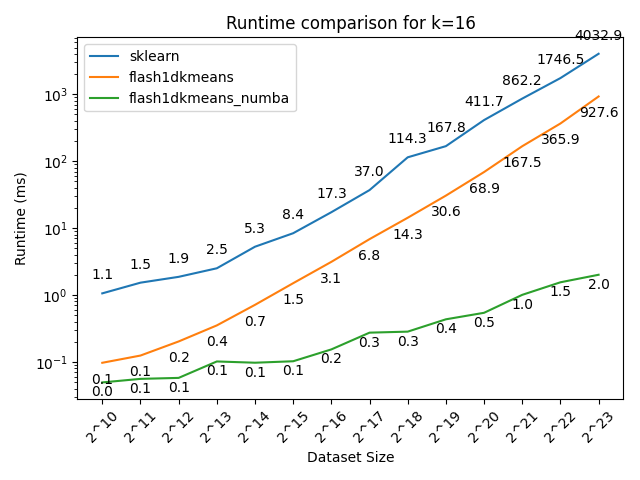
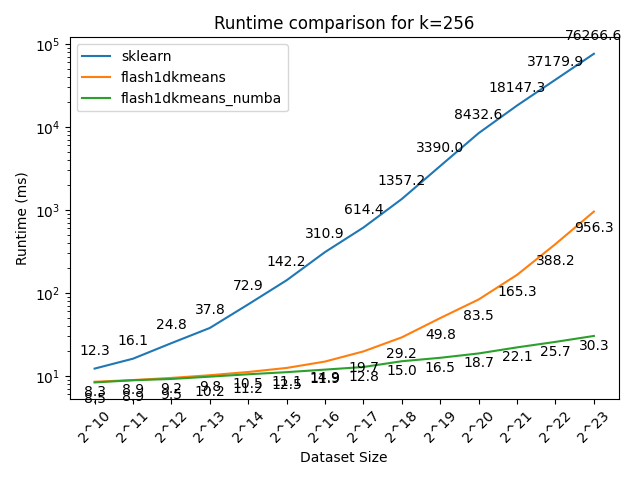
Here we compare flash1dkmeans against one of the most commonly used K-means implementations, sklearn.cluster.KMeans.
In the figures below, we show the K-means clustering runtime on randomly generated data of various sizes.
- flash1dkmeans measures the wrapper function kmeans_1d, which includes the sorting and prefix sum calculation overheads.
- flash1dkemeans_numba measures the underlying Numba-accelerated functions, excluding the sorting and prefix sum calculation overheads. (A case where this performance is useful is when you only have to sort once, while calling K-means multiple times on different segments of the same data - or if you already have the sorted prefix sum calculations ready. Both happened to be the case for Any-Precision-LLM.)
 |
 |
 |
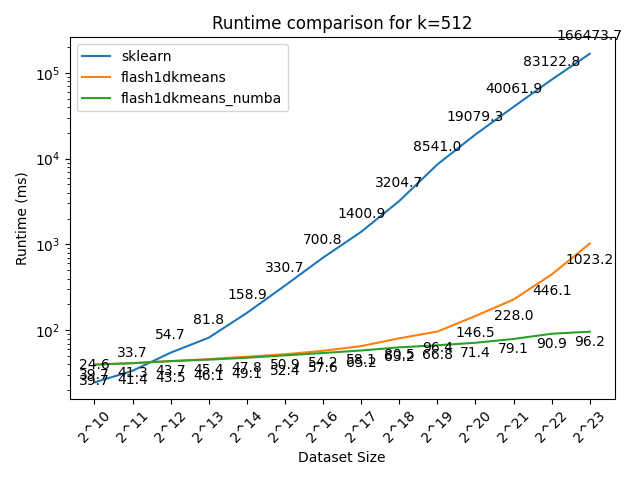 |
You can confirm that flash1dkmeans is several orders of magnitude faster, even when measured with the wrapper function, including the sorting and prefix sum calculation overheads.
Additionally, you can see that for the two-cluster case, the algorithm indeed is
These speeds are achieved while finding the optimal clustering for the two-cluster case, and running an optimized but mathematically equivalent algorithm to sklearn’s implementation for the k-cluster case, ensuring identical or better results apart from numerical errors and effects from randomness.
The figures below demonstrate this by comparing the squared error of the clusterings, on real and generated datasets obtained using scikit-learn.
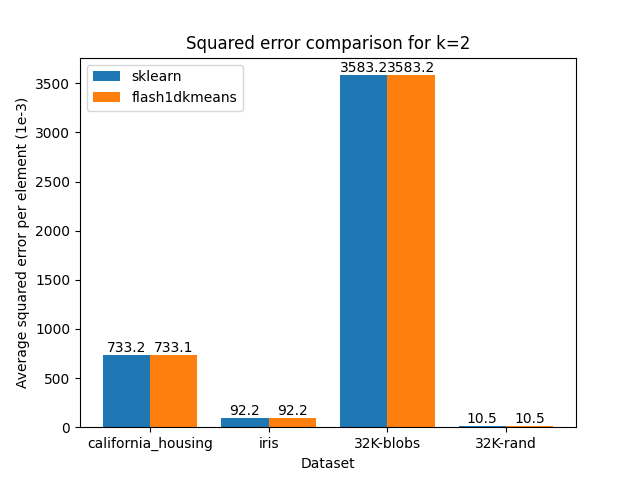 |
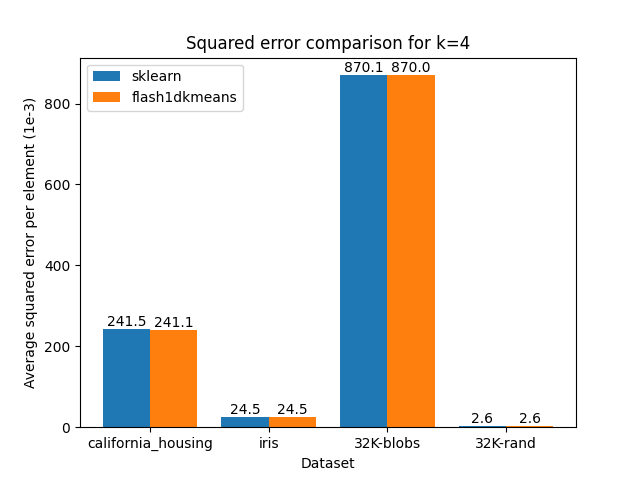 |
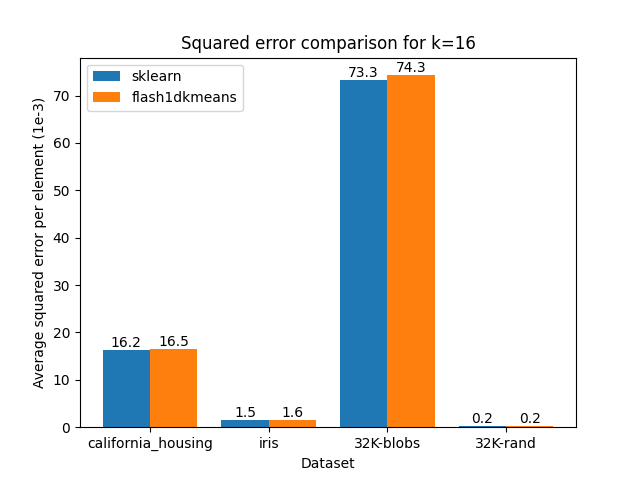 |
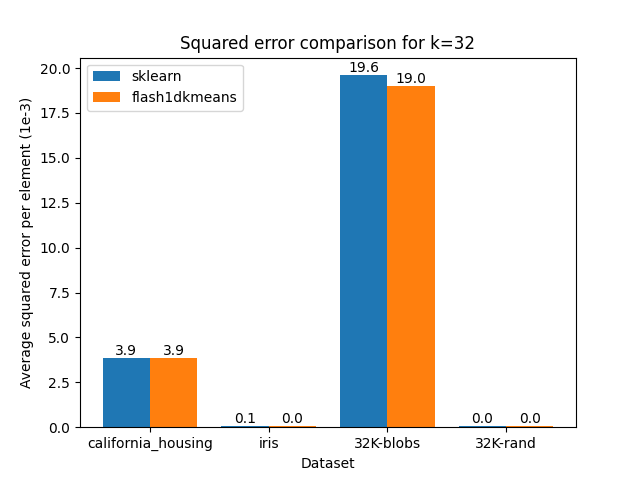 |
pip install flash1dkmeansfrom flash1dkmeans import kmeans_1d
data = [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
k = 2
centroids, labels = kmeans_1d(data, k)from flash1dkmeans import kmeans_1d
import numpy as np
data = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0])
weights = np.random.random_sample(data.shape)
k = 3
centroids, labels = kmeans_1d(
data, k,
sample_weights=weights, # sample weights
max_iter=100, # maximum number of iterations
random_state=42, # random seed
)The underlying Numba-accelerated function numba_kmeans_1d_k_clusters can be used directly for more control.
This is useful when the algorithm is run multiple times on different segments of the data, or to use within another Numba-accelerated function.
The list of available functions are as follows:
numba_kmeans_1d_two_clustersnumba_kmeans_1d_two_clusters_unweightednumba_kmeans_1d_k_clusternumba_kmeans_1d_k_cluster_unweighted
All of these functions assume the data is sorted beforehand.
from flash1dkmeans import numba_kmeans_1d_k_cluster
import numpy as np
n, k = 1024, 4
# Generate random data
data = np.random.random_sample(n)
data = np.sort(data)
# Generate random weights
weights = np.random.random_sample(data.shape)
# Calculate prefix sums
weights_prefix_sum = np.cumsum(weights)
weighted_X_prefix_sum = np.cumsum(data * weights)
weighted_X_squared_prefix_sum = np.cumsum(data ** 2 * weights)
middle_idx = n // 2
# Providing prefix sums reduces redundant calculations
# This is useful when the algorithm is run multiple times on different segments of the data
for start_idx, stop_idx in [(0, middle_idx), (middle_idx, n)]:
centroids, cluster_borders = numba_kmeans_1d_k_cluster( # Note that data MUST be sorted beforehand
data, k, # Note how the sample weights are not provided when the prefix sums are provided
max_iter=100, # maximum number of iterations
weights_prefix_sum=weights_prefix_sum, # prefix sum of the sample weights, leave empty for unweighted data
weighted_X_prefix_sum=weighted_X_prefix_sum, # prefix sum of the weighted data
weighted_X_squared_prefix_sum=weighted_X_squared_prefix_sum, # prefix sum of the squared weighted data
start_idx=start_idx, # start index of the data
stop_idx=stop_idx, # stop index of the data
random_state=42, # random seed
)Refer to the docstrings for more information.
This repository has been created to be used in Any-Precision-LLM project, where multiple 1D K-means instances are run in parallel for LLM quantization.
However, the algorithm is general and can be used for any 1D K-means problem.
I have proved the validity for the two cluster case - detailed version of the proof might be posted in the future.
Feel free to leave issues or contact me at jakehyun@snu.ac.kr for inquiries.