{kind=link}
{kind=link}
{kind=link}
- 有部分人用了如下方法之后,并没有达到描述的效果
- 主要问题在于,没有时刻注意要先跳概率大的方向,还有省略重复代码
- 同志们,我只能帮大家到这里了
- 在很多时候加减数不需要先mv到寄存器了,同时,具备刷新cc的能力,省去andq。
- iaddq $-1, 类似是可行的
- 多重循环展开,展开越多速度越快,本质上是减少了指针移动
- 避免mr和rm连写,也就是避免数据冒险
- 多重循环后,一重循环可以去掉末尾指针移动
- 注意jxx的方向,通过调整指令,使得总是跳跃到概率大的地方(数据数量是1到64)
- 到这一步,基本上可以拿到50分以上
- 采用8+2+1循环展开,或者9+2+1展开
- 该方法的核心在于,收尾的是2+1展开,因为类似的8+4+2,难以抹去指针移动(原因后面解释)
- 采用了多重循环组合之后,基本上有55分左右(8+4和8+2均可)
- 说起来比较简单,就是抹掉所有循环的末尾指针移动
- 比如说我有20个数据,在程序跑完的时候,指针停留在第20个数据的前面,第19个数据的后面,也就是说,省掉最后一次
- 具体到如何省掉的呢?类似于将指针增加操作移动到loop开头,设置两个不同的label,第一次进入循环的时候,跳到下面的label,循环末尾的判断,跳回到高位的label,这样,在最后一次循环结束时候,指针就没有移动。
- 那么,为什么说9+2+1是最极限的呢,原因如下:
- 我要抹掉9循环的末尾移动,那么,9循环结束后,到2循环的时候,指针并不在末尾位置,这样就乱了,如何解决这个问题?
- 方案如下:复制一遍二重循环代码,等于说,制造了两个二重循环,一个对应着,指针从末尾开始,另一个对应着,指针差了9个数据点,同理,制造四个一重收尾循环,收尾其实不算做循环了,因为要么做一次copy,要么直接结束,所以指令数极其少,如此,举例比如说,16个数据,原本是9+2+2+2+1,意味着我做了五次指针移动,并且还有一定的控制预测错误,但是,经过抹去操作,我实际上只用了 2+2,两次指针移动,每次指针移动两条add语句,就是2个周期,等于说,一波赚了6个周期,而类似的不能被完整结束的数据点很多,总体下来,性能提升了。
- 到这一步,有58.4分(适当调整三个循环的进入顺序,预测概率大的方向)
- 如果非2-1收尾,很显然,因为要多个版本的循环代码,很有可能超出bytes限制。
- 第一句的初始化rax可以去掉,因为这个程序比较简单,它就是0,不会引发错误
- 但这也不算是一个好的操作,总之可以拿分就是
- 到这一步,59.8分
- 单重循环指令数很少,少到找不到指令填充mr和rm之间的间隙,但因为这个运行次数不多,损失一个周期无关痛痒
- 但计数程序的设计上,开头几个权值很大,并且,0不计数
- 于是,极限操作应运而生,四个一重循环中的,唯一一个对应,只有一个数据点的那个循环,先mr,再jxx,赚回一个周期,同时在0的位置上损失一个周期
- 由于0不计数,1的位置权值很大,1个周期直接满分
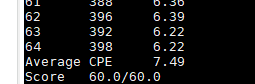
- 最后,CPE=7.49 score=60
- 举例说明,假如有两个数A,B,先检测A,然后根据结果跳到,0对应的B,和1对应的B
- 检测B,根据B的结果决定 +2 +1 +0
- 等于说,本来必须执行两次addq操作,现在合并了之后,只用执行一次,并且jxx用的次数也是一样多的
- 代价是多写很多label和复制代码,同时,注意一点,因为程序始终是顺序执行的,还是需要加一条jmp指令使程序跳到正确位置(仔细想想...)
- 所以,并没有省略掉周期数。(但是感谢sxy同学的暴力思路...得到如下启发)
- 如果同时判断n个数,并且n>2,还是只用增加一个jmp,但同时合并了多条add,(也是概率性的,因为有的时候都不执行add,这时候没什么区别)
- 具体代码书写挺长的,只能做锦上添花用用,很容易超出bytes
- CEP=7.47 score=60
- 在hcl里面检测某种指令组合(因为我可以拿到各个阶段的icode),然后再进行操作(修改逻辑或数据),同时,这种指令组合,在测试文件中不存在,比如5个nop指令(当然5个nop相当于啥都没做,但可以有别的组合),总的来说,不管测试文件有多大,总还是能找到一些指令组合的,因为逻辑上还可以判断指令操作数的内容,条件一多起来,测试文件很难覆盖到。
上述方法可以规避正确性检测,但并不是什么优秀的技术(慎用) - 同样在hcl里面检测某种指令组合,或者是单个指令(单个没什么可操作性),但对其做出足够多的条件判断和错误复原,使得在任何测试情况下都能正确。
这个方法比较难做成功,但算是有用的思想。
- 捕捉到需要做额外操作的时候,一般来说能加速的点也就是提高控制转移的正确性
- jxx需要等待的原因在于没有到ALU阶段,拿不到CC,也计算不了Cnd
- 事实上,给CPU加更多的计算单元和判断电路,在某些时候,额外计算一下Cnd,使得jxx直接跳向正确的方向(比如说jxx前面的代码里面没有修改cc的指令,这个时候cc是固定的了,那么可以用额外的计算部分算出来),但比较遗憾的是,修改hcl并不能真正地为所欲为,加线是很复杂的事情(似乎是不能真正的多增加一个计算单元的,还是需要利用已有的ALU)。
- 关于加线的一个特殊的事情是,逻辑判断的地方可以写>,<,>=,<=,这样的判断,这能帮助做特别多的事情。
- 个人观点:从电路角度来讲,判断大于小于并不是一件简单的事情(如果那么轻易就可以的话,何必用cc,Cnd这样复杂的结构?),以及,为此增加的线路并不少,一个比较现实的因素是,很有可能导致完成一个阶段的操作需要的时间变长,变长了意味着,CPE的时间变长了,程序也就不一定真的变快了(但lab里面显然是不在意一个阶段花了多少时间的,都算作一个Circle,所以就加速了)
- 总的来说就是,如果修改并不精巧的话(注意这个前提),相当于是,延长了Circle的时间,在一个�Circle里面做了更多的事情,使得CPE的数量下降了。(程序运行时间是CPE*Circle的时长,等于说很有可能程序并没有变快)