perf: optimization by introducing bfs and topological sort #290
Conversation
|
Wow, this is really awesome. I've spent a lot of time trying to make this code faster, so it's amazing to see more performance wins! Do you have any sense of how much of the perf win is arenas, vs how much is switching to DFS (edit: oops, I meant BFS)? I did experiment with A* search in this branch: https://github.com/Wilfred/difftastic/tree/a_star_module but I wasn't able to get a performance improvement and I was concerned it was significantly more complex. It's quite possible I was doing something wrong. |
|
I've done some profiles and I found that it takes a lot of time(30%) to drop the keys and values of the hashmap. I guess it is because of the overhead introduced by |
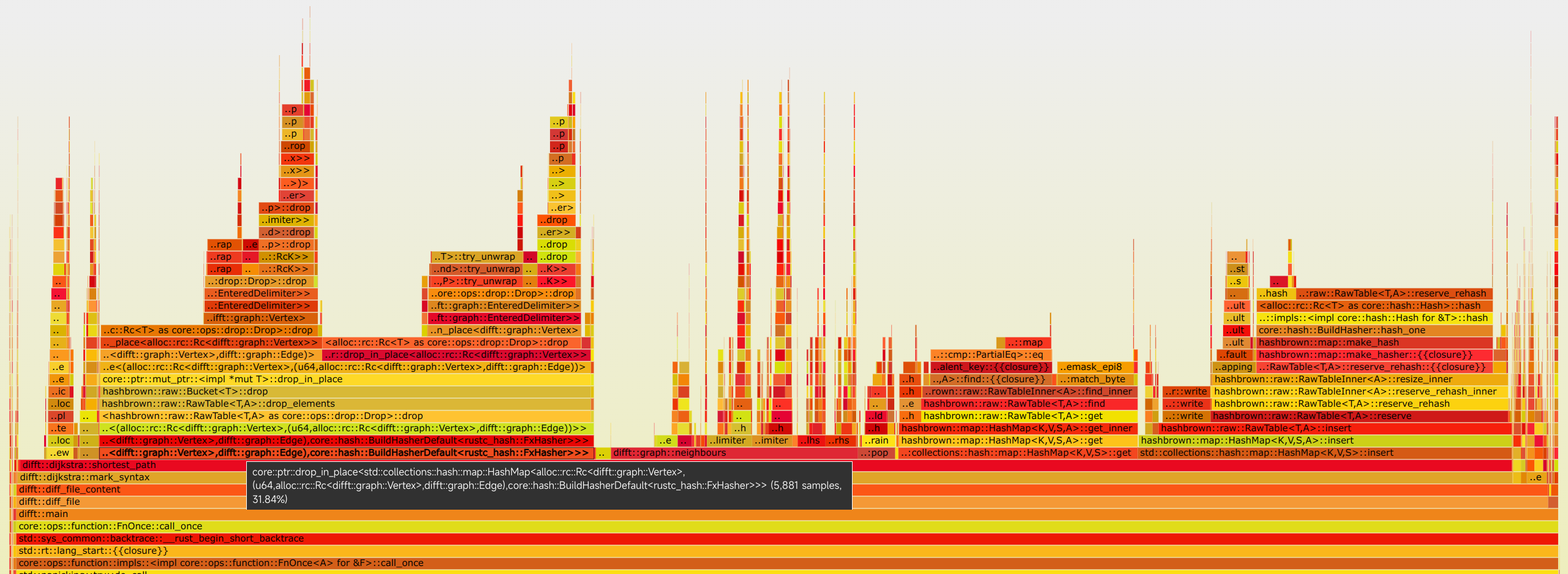

|
And it seems that quite a lot of time is used on the rehash of hashmap. This happens when inserting into the hashmap and it is not large enough to hold the elements. In this situation, all data will be rehashed which is really expensive. So if we are able to estimate the vertex count before actually starting finding the shortest path, we can As for the DFS, I'm not pretty sure but I think naive DFS may not be able to find the shortest path. The BFS shortest path algorithm for DAG is correct because the nearer the vertex is, the earlier it is added to the BFS queue. So when we find the end vertex, the shortest path is found. Maybe we can use dp and DFS to solve this: And there are some statistics when I was testing:
I also did investigations on parallel algorithms such as parallel BFS. But I found it really hard because |
|
I'm not familiar with the unit test. The error msg is as follows: It seems that everything is equal, except for |
|
Just update that test: the two routes have the same length, so both are correct. |
|
FWIW it's totally reasonable to make Syntax implement Send. Syntax is immutable, and it only mutates the Cells during init. |
Yeah, I'm working on this. I've dived into it a little and I found that if we are to make |
|
Wait, are you sure that BFS is giving the correct answer? It's a DAG, but the edges are weighted. BFS will find the route with the fewest edges, which isn't the same as the shortest route . I see a significant number of sample files have changed their output. I'd expected these not to change. |
Oh I think I've missed something, I will fix it. Maybe using dp. |
|
I've merged the arena allocation improvements in 1646d45 :) |
This reduces instruction counts by 4-6% on the sample files. Thanks to @Enter-tainer for suggesting this in #290.
|
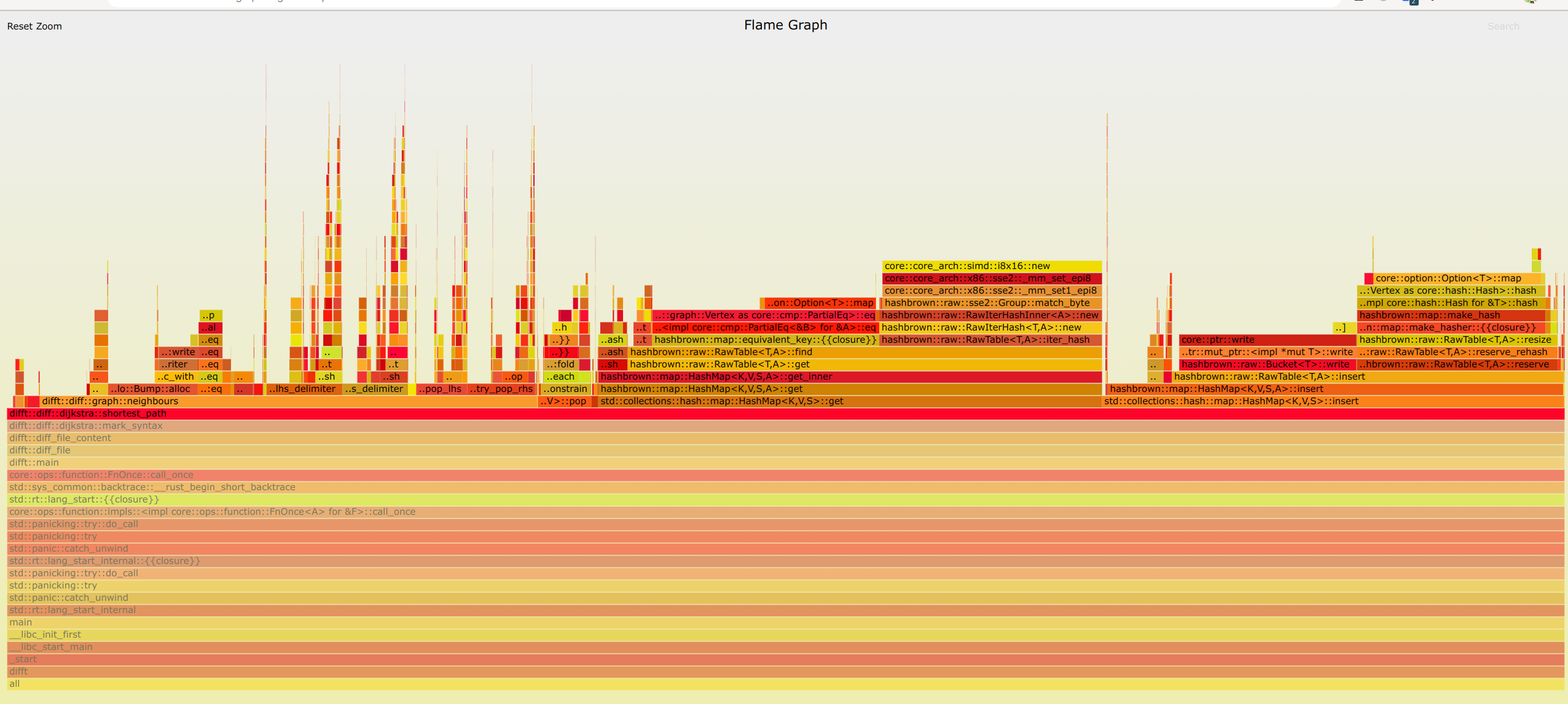
Hi, I profile on the latest master branch. And I found that it is pretty fast! The performance is very similar to the wrong BFS code in this PR.
And currently, the bottleneck seems to be So code in this PR might not be helpful. But I will still investigate performance optimizations! I will send a new PR if I can further optimize difftastic. |
Add `nameof` contextual keyword test cases
chore: generate and sync latest changes
For a DAG, we can find its shortest path by using bfs in$O(V+E)$ , while dijkstra takes $O(V+E\log V)$ time. BTW, I guess maybe we can introduce heuristic search algorithms like A* to further optimize it.
I also use the arena to allocate nodes to avoid the overhead of refcount.
As for the performance issue discussed in #236, it took ~25s on my machine, and currently, it only takes ~15s.
A unit test is failing and some cleaning work is needed. I'm still working on this. Feel free to give comments!