Test data provider
We enriched the Neodymium library to have an easy way to structure and manage test data in various ways.
We support the following file formats:
- CSV
- XML
- JSON
- Properties
NOTE: This is also the order in which data set files and package test data files are searched. In case you have multiple data set files with the same name but different extensions, only the file which extension has higher priority in the list above will be taken in count. E.g. if you have
FooTest.csvandFooTest.json, the test automation will only read data sets from theFooTest.csv.
Test data is a key-value storage that is defined beside your test classes. There are two different types of data files, data sets and package test data. Combined together they build test data which will be stored in a map that you can access later. In general all package data will be added to the map and then later on data from data sets. It is on purpose that you can overwrite values from package test data with values from data sets. This allows you define general data in package test data and test specific data in the data sets. So you can augment your data sets while having the possibility to override it at the same time.
-
Data sets:
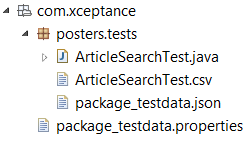
Contains multiple sets of data for a particular test class. A data set file must have the same name as the test class it is providing data for. For example: A data set file for a class named
foo.javacould be for examplefoo.csvorfoo.json -
Package test data:
Provides data for all test classes that are in the same package and inherits to classes all sub packages. Package test data is defined in a file named
package_testdatawhich must contain data in one of the supported file formats and so it needs an proper file ending e.g.:package_testdata.properties
NOTE: In general both types of data files need to be at the same place (package) as the class is else they can't be found.
Data sets are special as each defined set of data automatically causes a separate run of all tests of the class it is defined for. So for example: If you execute a test case and have a data set file with three data sets, it will be automatically executed for each and every defined data set unless told otherwise.
You can control that behaviour with annotations: @DataSet and @SuppressDataSets
-
We support data set in the following file formats: CSV, XML and JSON. Please find an example for each format below.
-
@SuppressDataSets: Can be annotated to a method and/or class. On a class it prevents all methods from beeing executed multiple times for data sets. On a method it is the same behaviour but just for that method and it will override any DataSet annotation from class or method.
-
@DataSet: Can be annotated to a method and/or class. This annotation can be used to limit a method to certain data sets regardless if there is an SuppressDataSets annotation on the class. If the class has an SuppressDataSets annotation the DataSet annotation can be used on a method to reenable execution for all or individual data sets. DataSet annotation can be parameterized to reference a specific data set. One could refer them by using an integer (value) or by using a string (id)
- value:
@DataSet(2)an integer referencing a specific data set (first data set would be referenced by 1) - id:
@DataSet(id = "Jebediah's data set")an string value that refers to an data set which has the same value for attributetestId(see Example 1). This allows you to name your data sets which will come handy at some point. - randomSets
@DataSet(randomSets = 4)an integer value meaning the number of randomly selected data sets to run the test with. If the corresponding test data file contains fewer data sets than mentioned you will receive the exception.
- value:
-
@RandomDataSets: Can be annotated to a method and/or class. This annotation allows to run test with certain amount of random data sets. The random data sets will be chosen from test data list. In case the annotated test also contains
@DataSetannotation, the random sets will be selected among the sets selected by the latter.- value:
@RandomDataSets(2)an integer referencing a number of randomly selected data sets
- value:
MyTest.csv
firstname, testId
Jane, Jane's data set
Jebediah, Jebediah's data set
Jill, Jill's data set
NOTE: Our CSV implementation treats the first line as variable name definition
public class MyTest
{
@NeodymiumTest // by default all methods will be executed with all data sets that are defined
public void allDataSets()
{
// you can access the current value by using DataUtils
String firstname = DataUtils.asString("firstname");
}
}On execution of the code above Eclipse' JUnit view will display the following output

NOTE: use same CSV file as above
@SuppressDataSets // disables data set support for the whole class
public class MyTest
{
@NeodymiumTest
public void noDataSets()
{
// this method will run only once and without any data set because of the SuppressDataSets annotation on the class
}
@NeodymiumTest
@DataSet(3) // overrides the class level @SuppressDataSets to run with the third data set
public void onlyThirdDataSet()
{
// this method will run only with third data set
}
@NeodymiumTest
@DataSet // overrides the class level @SuppressDataSets to run with all data sets
public void allDataSets()
{
// this method will run with all three data sets
}
}
Please checkout our example project to find more hands on examples e.g. RegisterTest.java
Data set files should not only have the same name as the corresponding test class. It is also expected that the file is reachable under the same path as the test with only difference that the test is located in the java source folder and the data set file in the resources folder.
In case it's required to place the data set file in another location, the @Datafile annotation can be useful. Neodymium provides the @Datafile annotation to override the data sets file location. By using this feature you are able to reuse the same data set for multiple test cases.
The file referred to by this annotation needs to reside within the resource path. You need to provide the full path to the file relative to the resource folder, including the file extension.
@DataFile("com/xceptance/neodymium/testclasses/data/set/json/CanReadDataSetJson.json")
public class CanReadDataSetJsonAgain
{
@NeodymiumTest
public void test()
{
DataUtils.asString(key);
}
}Package test data is almost the same as data sets except that it doesn't lead to multiple method execution. It is also a key value store that you can access from all the classes in a package and its sub packages. Package test data are defined in a file named e.g. package_testdata.csv (ending depends on chosen content format). One of the goodies of package test data is that the containing data will be inherited. For example: you define package test data in package com.mycompany and you can also use them from classes in sub packages like com.mycompany.tests and you can override these values by redefine a new value in a sub package test data file.
It's possible to change the package testdata's zone of validity by moving in deeper in the structure. Moving the file deeper in structure (e.g, from checkout.guest to checkout.guest.shipping) will decrease the zone of validity. In contrast to this, when the file is moved higher in structure (e.g, from checkout.guest.shipping to checkout.guest), the validity zone will be increased.
Test data and data sets are automatically processed on test execution. The NeodymiumRunner looks for package test data files and data set files. To access the data from your test case you can use DataUtils class or you can access the underlying hash map directly by using Neodymium.dataValue("<key>") from the Neodymium context class.
There are a few convenience methods in DataUtils that might be handy as these methods offer auto type conversion from string
| Method | Description |
|---|---|
String asString(String key) |
returns the value for stored key as string |
int asInt(String key) |
returns the value for stored key as integer |
long asLong(String key) |
returns the value for stored key as long |
double asDouble(String key) |
returns the value for stored key as double |
float asFloat(String key) |
returns the value for stored key as float |
boolean asBool(String key) |
returns the value for stored key as boolean |
T get(Class<T> clazz) |
creates an instance of the given class and tries to set value of member by searching test data for fields with the same name |
randomEmail() |
creates an random email address based on the values from configuration |
randomPassword() |
creates an random password based on the values from configuration |
The test data files should follow a specific key value pattern. We show case the format for each type below.
The first line of the *.csv file defines the names for the available data fields each of the following lines defines a data set. If you are writing the files by hand please pay attention that you do not add any unneeded spaces. They will lead to errors since the are added without trimming into the names or values of the data set.
name1,name2,name3
value1-set1,value2-set1,value3-set1
value1-set2,value2-set2,value3-set2
Our XML format has a datafile root element. This can hold as dataset element which results in a execution of the test method using the data elements as available parameters for that execution.
<?xml version="1.0" encoding="UTF-8"?>
<datafile>
<dataset>
<data key="name1">value1-set1</data>
<data key="name2">value2-set1</data>
<data key="name3">value3-set1</data>
</dataset>
<dataset>
<data key="name1">value1-set2</data>
<data key="name2">value2-set2</data>
<data key="name3">value3-set2</data>
</dataset>
</datafile>Our JSON format represents an array of objects. Each JSON object results in a execution of the test method using the data it holds.
[
{"name1":"value1-set1", "name2":"value2-set1", "name3":"value3-set1"},
{"name1":"value1-set2", "name2":"value2-set2", "name3":"value3-set2"}
]Test specific test data files need to have the same name as the test file and they need to be place either in the same directory as the test file or on the same path within the resource directory. The file format can be one of the above. With test specific data sets your are able to multiply the test execution. Every test method within the JUnit test will be executed once for each data set. Using this feature you can reach a higher test coverage by reusing the same code with different test data.
Test specific data overwrites the fields from package test data.
You can add test data on package levels in order to structure and manage you test data that should be shared between tests. Package test data only just take the first data set into account. All other data sets are ignored.
In order to use package test data you need to add a file with the name package_testdata and the file ending of one of the supported types.
In larger test projects you often find the need to work with more complex test objects e.g. containing lists of simple test objects. If you forward an arbitrary class to the following function DataUtils.get(Class<T> clazz) Neodymium will parse the available data structure and map the corresponding fields.
If you just need a specific part of the data Neodymium provides a second function: DataUtils.get(String jsonPath, Class<T> clazz) using a JsonPath to locate the requested element.
The easiest way to use those features is to format the test data using JSON. This is due to the fact that we require substructures to be formatted as JSON in order to parse and map them. Please see the following example.
[
{
"testId": "asObject",
"clubCardNumber": 1234567890,
"creditCard": {
"cardNumber": "4111111111111111",
"ccv": "123",
"month": "10",
"year": "2018"
},
"age": 23,
"names": [
"abc",
"def",
"ghi"
],
"persons": [
{
"firstName": "a",
"lastName": "b"
},
{
"firstName": "c",
"lastName": "d"
}
],
"keyValueMap": {
"key": "value"
},
level: "HIGH"
}
]TestCompoundClass:
public class TestCompoundClass
{
enum Level
{
LOW,
MEDIUM,
HIGH
}
private String clubCardNumber;
private String description;
private Object notSet;
private Double numberValue;
private Object nullValue = "notNullString";
private int age;
private TestCreditCard creditCard;
private List<String> names;
private List<TestPerson> persons;
private Map<String, String> keyValueMap;
private Level level;
public List<TestPerson> getPersons()
{
return persons;
}
public List<String> getNames()
{
return names;
}
public int getAge()
{
return age;
}
public String getClubCardNumber()
{
return clubCardNumber;
}
public TestCreditCard getCreditCard()
{
return creditCard;
}
public Map<String, String> getKeyValueMap()
{
return keyValueMap;
}
public Level getLevel()
{
return level;
}
public String getDescription()
{
return description;
}
public Double getNumberValue()
{
return numberValue;
}
public Object getNullValue()
{
return nullValue;
}
public Object getNotSet()
{
return notSet;
}
}TestCreditCard:
public class TestCreditCard
{
private String cardNumber;
private String ccv;
private int month;
private int year;
public String getCardNumber()
{
return cardNumber;
}
public String getCcv()
{
return ccv;
}
public int getMonth()
{
return month;
}
public int getYear()
{
return year;
}
}TestPerson:
public class TestPerson
{
private String firstName;
private String lastName;
public String getFirstName()
{
return firstName;
}
public String getLastName()
{
return lastName;
}
}@NeodymiumTest
@DataSet(id = "asObject")
public void testGetClass() throws Exception
{
TestCompoundClass testCompound = DataUtils.get(TestCompoundClass.class);
Assert.assertEquals("1234567890", testCompound.getClubCardNumber());
Assert.assertEquals(null, testCompound.getNotSet());
Assert.assertEquals(null, testCompound.getNullValue());
Assert.assertEquals(new Double(12.34), testCompound.getNumberValue());
Assert.assertEquals("containing strange things like spaces and ������", testCompound.getDescription());
Assert.assertEquals("4111111111111111", testCompound.getCreditCard().getCardNumber());
Assert.assertEquals("123", testCompound.getCreditCard().getCcv());
Assert.assertEquals(10, testCompound.getCreditCard().getMonth());
Assert.assertEquals(2018, testCompound.getCreditCard().getYear());
Assert.assertEquals(23, testCompound.getAge());
Assert.assertEquals(3, testCompound.getNames().size());
Assert.assertEquals("abc", testCompound.getNames().get(0));
Assert.assertEquals("def", testCompound.getNames().get(1));
Assert.assertEquals("ghi", testCompound.getNames().get(2));
Assert.assertEquals(2, testCompound.getPersons().size());
Assert.assertEquals("a", testCompound.getPersons().get(0).getFirstName());
Assert.assertEquals("b", testCompound.getPersons().get(0).getLastName());
Assert.assertEquals("c", testCompound.getPersons().get(1).getFirstName());
Assert.assertEquals("d", testCompound.getPersons().get(1).getLastName());
Assert.assertEquals("value", testCompound.getKeyValueMap().get("key"));
Assert.assertEquals(TestCompoundClass.Level.HIGH, testCompound.getLevel());
}
@NeodymiumTest
@DataSet(id = "asObject")
public void testGetByPath() throws Exception
{
Double numberValue = DataUtils.get("$.numberValue", Double.class);
Assert.assertEquals(new Double(12.34), numberValue);
String description = DataUtils.get("$.description", String.class);
Assert.assertEquals("containing strange things like spaces and ������", description);
TestCreditCard creditCard = DataUtils.get("$.creditCard", TestCreditCard.class);
Assert.assertEquals("4111111111111111", creditCard.getCardNumber());
Assert.assertEquals("123", creditCard.getCcv());
Assert.assertEquals(10, creditCard.getMonth());
Assert.assertEquals(2018, creditCard.getYear());
String name = DataUtils.get("$.names[2]", String.class);
Assert.assertEquals("ghi", name);
String lastName = DataUtils.get("$.persons[1].lastName", String.class);
Assert.assertEquals("d", lastName);
TestCompoundClass.Level level = DataUtils.get("$.level", TestCompoundClass.Level.class);
Assert.assertEquals(TestCompoundClass.Level.HIGH, level);
@SuppressWarnings("unchecked")
List<String> firstNames = DataUtils.get("$.persons[*].firstName", List.class);
Assert.assertEquals("a", firstNames.get(0));
Assert.assertEquals("c", firstNames.get(1));
Object nullValue = DataUtils.get("$.nullValue", Object.class);
Assert.assertEquals(null, nullValue);
Object notSet = DataUtils.get("$.notSet", Object.class);
Assert.assertEquals(null, notSet);
}The annotation @DataItem is used to instantiate objects with values originated from your test data.
By default, the objects with a name matching the one of the variable will be parsed to the variable.
In case there are no objects that match the name, the JSON objects or names that match the fields of the variable will be used to instantiate the corresponding fields.
Instead of
String description = DataUtils.get("$.description", String.class);use
@DataItem ("$.description")
public string description