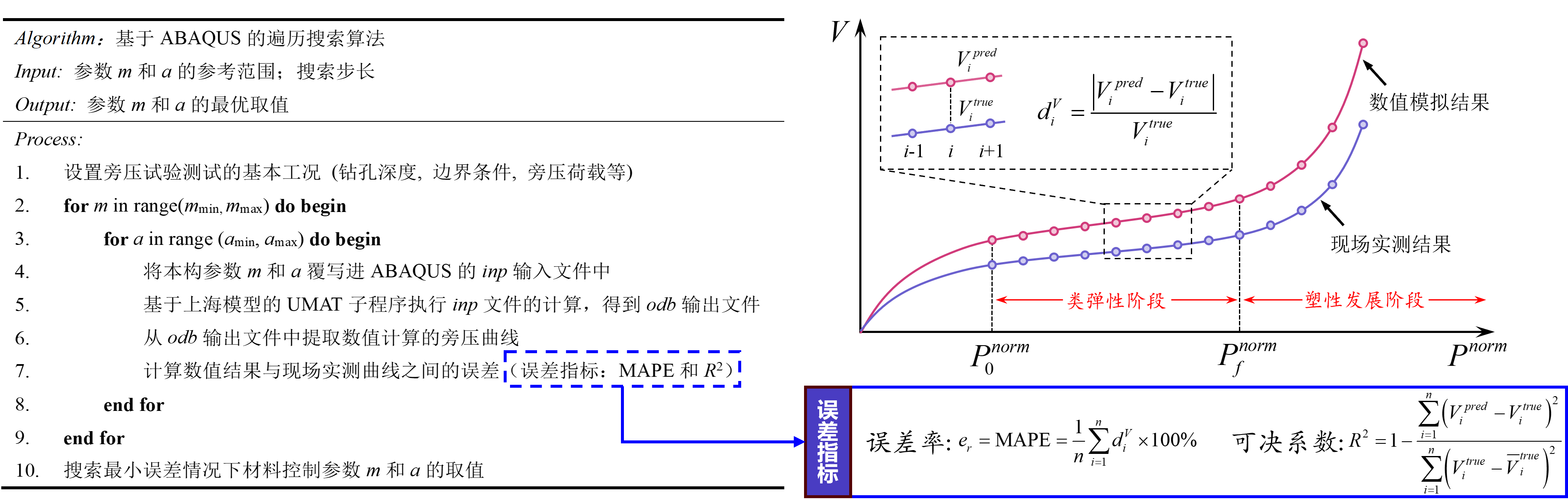
利用python进行在Abaqus中基于Umat子程序进行旁压试验(轴对称模型)的遍历计算,主要流程包括 覆写本构参数、自动提交运算,结果导出和后处理等,在执行求解过程中调用了gpu加速有限元计算。程序流程如下:
环境配置分为两个部分,第一个是python环境配置,第二个是abaqus环境配置。
下载项目后,在项目当前文件夹目录(...\PMT-Traversal-in-Abauqs-main)下,进入cmd控制台,然后执行下面的命令:
conda crate -n pyabaqus37 python=3.7 #创建名为pyabaqus37的python环境
conda activate pyabaqus37 # 在当前目录下激活pyabaqus37环境
pip install -r requirements.txt # 安装依赖包
上述过程如下所示:
完成安装后,python环境配置完成。
在本项目中,使用了gpu加速有限元计算,因此需要安装支持gpu运算的abaqus版本。由于在执行有限元计算时需要调用Umat子程序,所以也需要安装fortran编译的关联软件,可以考虑安装如下版本:
Abaqus 2021
Visual Stuido 2019
Intel Parallel Studio XE 2020
关于abaqus软件安装和关联子程序方面的内容,可以参考以下资料
在完成abaqus及关联程序的安装后,需要配置gpu加速的相关设置,与深度学习配置gpu加速相同,需要安装nvidia的cuda和cudnn,关于nvidia cuda和cudnn的安装,可以参考以下资料:
-
因为abaqus执行运算时不支持中文路径,需要在全英文路径下运行
-
默认abaqus是使用gpu进行计算的,若尚未部署gpu运算环境,需要在
main.py中进行修改,下面分别给出gpu和cpu运算的代码,请您根据自己的实际需求进行修改input_file.write(f'call abaqus job=Job-{i} int user=CYCLIC.for gpus=1 ask=off') # 调用gpu执行计算 input_file.write(f'call abaqus job=Job-{i} int user=CYCLIC.for cpus=6 ask=off') # 调用cpu执行计算这里作者给出一点参考,以本人笔记本的基本配置,在执行gpu运算时,单个模型的运算时间相较于cpu多核并行计算可以节省约40%左右。
CPU型号:12th Gen Intel(R)Core(TM)i7-12700H 14核20线程 GPU型号:Nvidia GeForce RTX 3060 Laptop 6GB显存 -
文件夹
test data用于存放现场实测的数据,每次运行后依据insitu_data.xlsx中的数据进行误差计算,并将结果输出到outputs文件夹中 -
每组参数的运算结果在文件夹
outputs中;所有结果的统计数据在文件夹results中
-
basic model.inp是一个abaqus基础模型,每次运算均是在基础模型上修改本构参数,进而利用bat批处理文件提交计算,然后执行run_extract.py进行后处理。 -
在子文件夹
models中,包含了一个fortran编写的Umat子程序(上海模型) -
abaqus文件夹中涉及到的文件解释如下:文件名称 文件类型 解释 basic model.inp基本模型 参数的改写均是基于该文件进行 models子文件夹 用于存放计算后的文件 input.bat批处理程序 用于提交inp文件执行计算 extract.py结果提取文件 用于从odb文件中提取结果 run_extract.py结果提取文件 用于执行 extract.py文件