A solution for using Machine Learning towards synthetic data generation by carrying out exploratory data analysis of existing production database and deriving statistical characteristics from the prod DB and then generating synthetic data that encapsulates similar statistical properties and maintains same referential integrity and correlation co-coefficients.
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes.
Requires Python >= 3.6.2, all dependent python frameworks requirements are stated in requirements.txt
- Clone or download to your desired location
git clone https://github.com/aayush-jain18/synthetic-data-generation.git
- cd to the installation directory synthetic-data-master and create a virtualenv to isolate project requirements
virtualenv testenv
- Activate the virtualenv
testenv\Scripts\activate
- Install all the frameworks requirements in your virtualenv
pip install -r requirements.txt
- Change the input and output path for results as required in config.yaml
- Run the framework from parent directory using below command
python synthetic_data_generation -c config.yaml
- Deactivate the virtualenv once test is completed.
deactivate
All the Input and output parameters for the tools can be configured via config.yaml, config.yaml can be passed to the process from main.py
python synthetic_data_generation -c tests\config.yaml**Please use config.yaml as template for creating new configs
All the results are stored to reports, locations that is relative to
input_path provided via config.yaml. Following files are
generated as output.
- log.out (process details and events log)
- db_metadata.xlsx (if input source is database, generated database metadata)
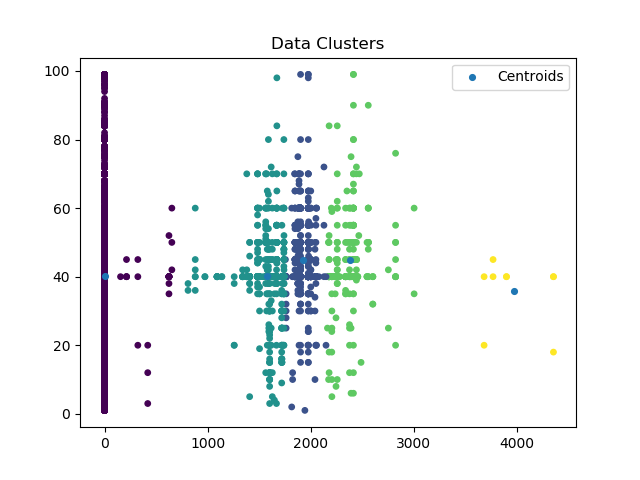
- Input data source stats and clusters representation
- cluster.png
- heatmap.png
- pair_plot.png
- summary.xlsx
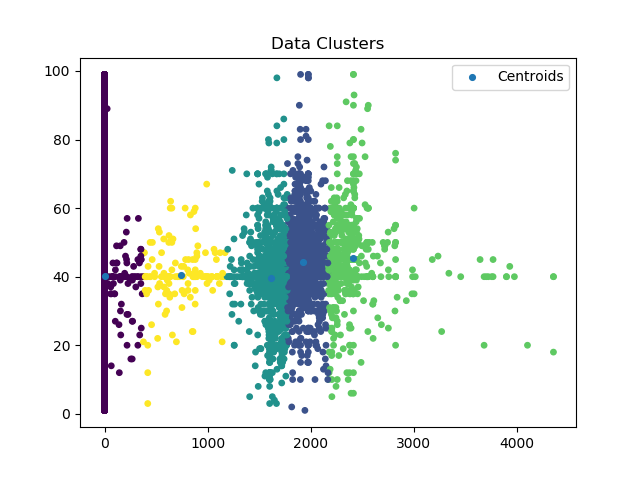
- Synthetic output results, stats and clusters representation
- synth_cluster.png
- synth_heatmap.png
- synth_pair_plot.png
- synth_summary.xlsx
- synth_results.xlsx
Input data cluster representation
Synthetic Data Generated output cluster representation
- Pandas - Data structures and Data analysis tools for the Python
- NumPy - Data structures and Data analysis tools for the Python
- scikit-learn - Data mining and data analysis
- imbalanced-learn - re-sampling tools for datasets showing strong between-class imbalance.
- matplotlib - 2D plotting tools
- seaborn - statistical data visualization
- Aayush Jain - Author -
This project is licensed under the _______ License - see the LICENSE.md file for details