| ANALISIS Y DISENO | DE ALGORITMOS |
|---|---|
 |
 |
El análisis de algoritmos puede entenderse como la estimación del consumo de recursos que un algoritmo requiere, para lo cual se utilizan herramientasanalíticas, de tal manera que sea posible establecer el rendimiento del programa que lo utiliza, o va a utilizar, y comparar los costos relativos de dos o más algoritmos para resolver un mismo problema.
El análisis de algoritmos también proporciona una herramienta a los diseñadoresde algoritmos para estimar si una solución propuesta satisface las restricciones de recursos de un problema sin necesidad de implementarla. Este análisis se basa en las estructuras de sus instrucciones y en la cantidad de memoria requeridapara resolver el problema.
Por otro lado, dentro del análisis algorítmico es de suma importancia el análisis semántico, que estudia la función asociada al algoritmo, según el concepto que lo define como el cálculo de una función que toma una entrada (datos de entrada) y la transforma con el fin de producir una salida (datos de salida). Con lo cual aparece una nueva definición: un algoritmo es correcto para un problema cuando calcula la función asociada a ese problema. Esto es muy útil porque permite definir un mecanismo formal para probar si un algoritmo hace lo que dice que hace. En otras palabras, demostrar la correctitud del algoritmo es demostrar que da la respuesta correcta a toda posible entrada de datos
[2]. Apesar de lo complicado que esto pueda parecer, en realidad se trata de usar invariantes de ciclos. Las invariantes son propiedades que al cumplirse ayudan a entender por qué el algoritmo es correcto. Es necesario verificar que se cumplentres aspectos acerca de una invariante de un ciclo:
- Inicialización: la invariante es cierta antes de la primera iteración del ciclo.
- Mantenimiento: si se cumple antes de una iteración, igualmente se cumplirá
- antes de la siguiente iteración.
- Terminación: al finalizar el ciclo, la propiedad (invariante) se sigue
Otro importante uso del análisis de algoritmos es el que permite evaluar las estructuras de datos de un programa, de tal manera que se pueda establecer la eficiencia de un algoritmo utilizando diferentes estructuras.
Es importante tener en cuenta que para la solución práctica de un problema es necesario, por una parte, un algoritmo o método de solución y, por otra, su implementación en un lenguaje de programación ejecutable en un computador.
El algoritmo y su implementación son muy importantes, pero el primero es absolutamente esencial, ya que allí es donde se determina la forma en que se resuelve el problema, mientras que la codificación puede muchas veces ser un proceso netamente mecánico que refleja las bondades o las fallas del algoritmo.
Como se mencionó anteriormente, el análisis de algoritmos estima el consumo de recursos de estos y permite comparar los costos relativos de dos o más algoritmos para resolver el mismo problema, dándoles una herramienta a los diseñadores para estimar si una solución propuesta satisface o no las restricciones sobre los recursos disponibles.
Algunas de las principales inquietudes que se presentan al desarrollar algoritmos y escribir programas son las siguientes:
- ¿Qué tan bueno es el algoritmo?
- ¿Qué tan eficiente es?
- ¿Se puede hacer un algoritmo mejor?
- ¿Se puede mejorar o acelerar un algoritmo?
- ¿Genera la respuesta correcta?
Adicionalmente, desde que se desarrollaron los lenguajes de programación surgió el interrogante de cómo comparar dos programas que resuelven el mismo problema, el cual ha conducido a afirmaciones como las siguientes:
- El mejor programa es aquel que tiene menos líneas de código.
- El mejor programa es aquel que tiene más líneas de código.
- El mejor programa es el que toma menos tiempo para encontrar la solución.
- El mejor programa es el que posee la interfaz más simple para su manejo.
Estas afirmaciones y muchas otras hacen que mediante el análisis de algoritmos se busque una solución y se establezcan criterios claros y objetivos para determinar cuándo un programa es bueno o malo en un sentido estrictamente formal. Las características de interés son generalmente los recursos tiempo y espacio; es decir, se quiere saber cuánto tiempo tomará la ejecución de una implementación en particular de un algoritmo y, además, el espacio que se requerirá. A lo largo del texto se trata de mantener el análisis independiente de cualquier consideración de implementación, pues lo que se busca es estudiar el comportamiento del algoritmo a partir de la cantidad de pasos que requiere, lo que depende, en principio, de las características del algoritmo mismo y no de la máquina, el lenguaje, el programador, etc. que intervienen en su implementación. En la práctica, lograr la independencia entre esta y el algoritmo es difícil, pues, como ya se mencionó, son muchos los aspectos que podrían considerarse (máquinas, compiladores, ambientes de programación, etc.) y que podrían ejercer efectos dramáticos en el rendimiento, con lo cual también se puede concluir que el análisis algorítmico, dado el caso, podría ayudar a aprovechar de mejor forma tales aspectos.
Un principio importante en el diseño de algoritmos es a menudo conocido como principio del balanceo de espacio/tiempo. Este principio plantea que se puede lograr una reducción en tiempo, si se sacrifica en espacio y viceversa.
Casi siempre se escucha en las empresas o en los departamentos de informática sobre la necesidad de un computador más rápido, ya que el que se tiene es muy lento. ¿Es eso cierto?
Los computadores no se vuelven más lentos (a menos que tengan algún tipo de virus o falla). El problema radica en que las necesidades de información de los usuarios aumentan, así como el tamaño y complejidad de los programas que se utilizan. Debido a esto, el tiempo de respuesta del computador puede aumentar,dando la sensación de que es más lento.
Esta problemática se presenta frecuentemente cuando los usuarios comunes de sistemas computacionales tipo PC van actualizando sus versiones de sistema operativo o software de ofimática. Por ejemplo, supongamos que un usuario adquiere un computador personal con ciertas especificaciones técnicas de procesamiento, cantidad de memoria, sistema operacional y software de ofimática y realiza en este todas sus operaciones cotidianas, con un desempeño y un tiempo de respuesta adecuados.
Si se actualiza el software con versiones más modernas de sistema operativo y software de ofimática, ¿qué pasa con el rendimiento del computador? Con toda seguridad, la velocidad de respuesta disminuirá considerablemente, lo cual no indica que el computador sea más lento, sino que los nuevos programas requieren más instrucciones y operaciones para funcionar (más ayudas, mejor presentación, mejor interfaz, etc.).
Si no se quiere cambiar los equipos de hardware, y se espera obtener una mejor respuesta en los sistemas de cómputo, es imperativo conseguir programas más eficientes basados en algoritmos mejor diseñados que se desempeñen más rápidamente, consumiendo menos recursos computacionales.
Son muchos los elementos que pueden influir en la evaluación y el funcionamiento de un algoritmo, entre los cuales es importante analizar: tiempo de ejecución, número de líneas de código, estructura del algoritmo, implementación.
Muchas veces se piensa que el mejor programa es el que menos tiempo de ejecución requiere, lo cual puede ser cierto, pero se deben tener en cuenta otros parámetros importantes.
Si se mide con un cronómetro, por más exacto que este sea, hay muchos factores que influyen en este resultado. Por ejemplo, la mayoría de los sistemas operativos que se utilizan hoy día son multiusuario o multitarea, razón por la cual no habrá un único programa ejecutándose en un momento determinado.
Dadas las características del computador, su procesador o procesadores estarán operando en modo compartido, lo que implicará que el tiempo medido no sea solo de un programa, sino de varios programas y procesos que se están ejecutando en ese momento.
La cantidad de tiempo que un programa utilizó de la CPU (medido, por ejemplo, con el comando time en Unix), puede ser un dato más útil siempre y cuando las mediciones se hagan sobre la misma máquina y en las mismas condiciones de carga, ya que las características del computador en cuanto a su procesador (tamaño de la palabra, arquitectura, velocidad de reloj, cantidad de memoria, memoria caché, velocidad de acceso a los discos) hacen que un programa presente resultados en cuanto a tiempo muy diferentes entre una máquina y otra.
Ejemplo: si se tiene un programa que es interactivo, al tiempo de ejecución se le sumará lo que el usuario tarde en introducir los datos o comandos, lo que reflejará un monto de tiempo errado, mucho mayor de lo real.
Algunas veces se cree que el número de líneas que tiene un programa influye en su eficiencia o velocidad de ejecución, pero este factor no puede tenerse en cuenta, ya que —debido a la presencia de instrucciones repetitivas, ciclos o llamados recursivos—, unas pocas líneas de código se pueden ejecutar muchas veces, mientras que un programa con muchas líneas de código y sin instrucciones repetitivas se puede ejecutar en mucho menos tiempo.
definir y dar ejemplos de
Estructuras de Control
Estructuras iterativas
Funciones y procedimientos
- Tenga un único punto de inicio.
- Tenga un número finito de posibles puntos de término.
- Halla un número finito de caminos, entre el punto de inicio y los posibles puntos de término.
Los pseudocódigos presentan los siguientes beneficios:
- Ocupan mucho menos espacio en el desarrollo del problema.
- Permite representar de forma fácil operaciones repetitivas complejas.
- Es más sencilla la tarea de pasar de pseudocódigo a un lenguaje de programación formal.
- Si se siguen las reglas de sangría se puede observar claramente los niveles en la estructura del programa.
- En los procesos de aprendizaje de los alumnos de programación, éstos están más cerca del paso siguiente (codificación en un lenguaje determinado, que los que se inician en esto con la modalidad Diagramas de Flujo).
- Mejora la claridad de la solución de un problema.
Pseudocódigo estilo Fortran:
programa bizzbuzz
hacer i = 1 hasta 100
establecer print_number a verdadero
si i es divisible por 3
escribir "Bizz"
establecer print_number a falso
si i es divisible por 5
escribir "Buzz"
establecer print_number a falso
si print_number, escribir i
escribir una nueva línea
fin del hacerprocedimiento bizzbuzz
para i := 1 hasta 100 hacer
establecer print_number a verdadero;
Si i es divisible por 3 entonces
escribir "Bizz";
establecer print_number a falso;
Si i es divisible por 5 entonces
escribir "Buzz";
establecer print_number a falso;
Si print_number, escribir i;
escribir una nueva línea;
finsubproceso funcion bizzbuzz
para (i <- 1; i<=100; i++) {
establecer print_number a verdadero;
Si i es divisible por 3
escribir "Bizz";
establecer print_number a falso;
Si i es divisible por 5
escribir "Buzz";
establecer print_number a falso;
Si print_number, escribir i;
escribir una nueva línea;La definición de datos se da por supuesta, sobre todo en las variables sencillas, si se emplea formaciones: pilas, colas, vectores o registros, se pueden definir en la cabecera del algoritmo, y naturalmente cuando empleemos el pseudocódigo para definir estructuras de datos, esta parte la desarrollaremos adecuadamente.
En la redacción de pseudocódigo se utiliza tres tipos de estructuras de control: las secuenciales, las selectivas y las iterativas.
Las instrucciones se siguen en una secuencia fija que normalmente viene dada por el número de renglón. Es decir que las instrucciones se ejecutan de arriba hacia abajo.
Las instrucciones selectivas representan instrucciones que pueden o no ejecutarse, según el cumplimiento de una condición.
Si Condicion Entonces
instrucciones
Fin Si

La instrucción alternativa realiza una instrucción de dos posibles, según el cumplimiento de una condición.
Si Condicion Entonces
instrucciones
Si no Entonces
instrucciones
Fin Si

La condición es una variable booleana o una función reducible a booleana (lógica, Verdadero/Falso). Si esta condición es cierta se ejecuta Instrucciones1, si no es así, entonces se ejecuta
Una construcción similar a la anterior (equivalente en algunos casos) es la que se muestra a continuación.
Segun Variable Hacer
Caso valor1:
instrucciones1;
Caso valor2:
instrucciones2;
Caso valor3:
instrucciones3;
Caso valor4:
instrucciones4;
...
Caso valorn:
instrucciones1;
Fin Segun
En este caso hay un Indicador es una variable o una función cuyo valor es comparado en cada caso con los valores "Valori", si en algún caso coinciden ambos valores, entonces se ejecutarán las Instruccionesi correspondientes. La sección en otro caso es análoga a la sección si no del ejemplo anterior.
El bucle se repite mientras la condición sea cierta, si al llegar por primera vez al bucle mientras la condición es falsa, el cuerpo del bucle no se ejecuta alguna vez.
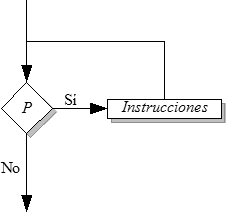
Mientras condicion Hacer
instrucciones;
Fin Mientras
Existen otras variantes que se derivan a partir de la anterior. La estructura de control repetir se utiliza cuando es necesario que el cuerpo del bucle se ejecuten al menos una vez y hasta que se cumpla la condición:
Repetir
instrucciones;
Hacer Que Condicion
instrucciones;
Mientras (condicion) Hacer
instrucciones;
Fin Mientras
Una estructura de control muy común es el ciclo FOR, la cual se usa cuando se desea iterar un número conocido de veces, empleando como índice una variable que se incrementa (o decrementa):
para <-- x Hasta n Con Paso z Hacer
Instrucciones;
Fin Para
Por último, también es común usar la estructura de control para cada. Esta sentencia se usa cuando se tiene una lista o un conjunto L y se quiere iterar por cada uno de sus elementos:
Para Cada x en l Hacer
instrucciones;
Fin Para Cada
Muchas personas prefieren distinguir entre funciones y procedimientos. Una función, al igual que una función matemática, recibe uno o varios valores de entrada y regresa una salida mientras que un procedimiento recibe una entrada y no genera alguna salida aunque en algún caso podría devolver resultados a través de sus parámetros de entrada si estos se han declarado por referencia (ver formas de pasar argumentos a una función o procedimiento).
En ambos casos es necesario dejar en claro cuáles son las entradas para el algoritmo, esto se hace comúnmente colocando estos valores entre paréntesis al principio o bien declarándolo explícitamente con un enunciado. En el caso de las funciones, es necesario colocar una palabra como regresar o devolver para indicar cuál es la salida generada por el algoritmo. Por ejemplo, el pseudocódigo de una función que permite calcular a Elevado a la n a elevado a potencia n.
Existen diversas clasificaciones de algoritmos, en función de diferentes criterios. Según su sistema de signos (cómo describen los pasos a seguir), se distingue entre algoritmos cuantitativos y cualitativos, si lo hacen a través de cálculos matemáticos o secuencias lógicas. Asimismo, si requieren o no el empleo de un ordenador para su resolución, se clasifican en computacionales y no computacionales.
Pero, si nos fijamos en su función (qué hace) y su estrategia para llegar a la solución (cómo lo hace), encontramos muchos más tipos de algoritmos. Destacamos los siguientes cinco tipos de algoritmos informáticos:

Los algoritmos de búsqueda localizan uno o varios elementos que presenten una serie de propiedades dentro de una estructura de datos.
Búsqueda secuencial. En la que se compara el elemento a localizar con cada elemento del conjunto hasta encontrarlo o hasta que hayamos comparado todos.
Búsqueda binaria. En un conjunto de elementos ordenados, hace una comparación con el elemento ubicado en el medio y, si no son iguales, continúa la búsqueda en la mitad donde puede estar. Y así sucesivamente en intervalos cada vez más pequeños de elementos.
Reorganizan los elementos de un listado según una relación de orden. Las más habituales son el orden numérico y el orden lexicográfico. Un orden eficiente optimiza el uso de algoritmos como los de búsqueda y facilitan la consecución de resultados legibles por personas y no solo máquinas.
Ordenamiento de burbuja. Compara cada elemento de la lista a ordenar con el siguiente e intercambia su posición si no están en el orden adecuado. Se revisa varias veces toda la lista hasta que no se necesiten más intercambios.
Ordenamiento por selección. Vamos colocando el elemento más pequeño disponible en cada una de las posiciones de la lista de forma consecutiva.
Ordenamiento rápido. Elegimos un elemento del conjunto (pivote) y reubicamos el resto a cada uno de sus lados, en función de si son mayores o menores que el elemento que estamos tomando como referencia. Repetimos el procedimiento en cada subconjunto.

Los algoritmos voraces consisten en una estrategia de búsqueda que sigue una heurística en la que se elige la mejor opción óptima en cada paso local con el objetivo de llegar a una solución general óptima. Es decir, en cada paso del proceso escogen el mejor elemento (elemento prometedor) y comprueban que pueda formar parte de una solución global factible. Normalmente se utilizan para resolver problemas de optimización.
En ocasiones, estos algoritmos no encuentran la solución global óptima, ya que al tomar una decisión solo tienen en cuenta la información de las decisiones que han tomado hasta el momento y no las futuras que puede adoptar. Algunos casos en los que los algoritmos voraces alcanzan soluciones óptimas son:
- Problema de la mochila fraccional (KP). Disponemos de una colección de objetos (cada uno de ellos con un valor y un peso asociados) y debemos determinar cuáles colocar en la mochila para lograr transportar el valor máximo sin superar el peso que puede soportar.
- Algoritmo de Dijkstra. Utilizado para determinar el camino más corto desde un vértice origen hasta los demás vértices de un grafo, que tiene pesos en cada arista.
- Codificación Huffman. Método de compresión de datos sin perder información, que analiza la frecuencia de aparición de caracteres de un mensaje y les asigna un código de longitud variable. Cuanto mayor sea la frecuencia le corresponderá un código más corto.
La programación dinámica es un método de resolución de problemas en el que dividimos un problema complejo en subproblemas y calculamos y almacenamos sus soluciones, para que no haga falta volver a calcularlas más adelante para llegar a la solución del problema. La programación dinámica reduce el tiempo de ejecución de un algoritmo al optimizar la recursión.
Eso sí, para poder aplicarse a un problema, éste debe tener subestructuras óptimas y subproblemas superpuestos. Es decir, que en él se puedan usar soluciones óptimas de subproblemas para encontrar la solución óptima del problema en su conjunto y que el problema se pueda dividir en subproblemas que se reutilizan para ofrecer el resultado global.
- La serie de Fibonacci. Sucesión de números que comienza con “0” y “1” y, a partir de ellos, cada número es resultado de la suma de los dos que le preceden. La relación de recurrencia la define.
- Problema de la mochila.
Es una técnica que usa una fuente de aleatoriedad como parte de su lógica. Mediante un muestreo aleatorio de la entrada llega a una solución que puede no ser totalmente óptima, pero que es adecuada para el problema planteado.
Se utiliza en situaciones con limitaciones de tiempo o memoria y cuando se puede aceptar una buena solución de media, ya que a partir de los mismos datos se pueden obtener soluciones diferentes y algunas erróneas. Para que sea más probable ofrecer una solución correcta, se repite el algoritmo varias veces con diferentes submuestras aleatorias y se comparan los resultados.
- Algoritmo de Montecarlo. Dependiendo de la entrada, hay una pequeña probabilidad de que no acierte o no llegue a una solución. Se puede reducir la probabilidad de error aumentando el tiempo de cálculo.
- Algoritmo de Las Vegas. Se ejecuta en un periodo de tiempo concreto. Si encuentra una solución en ese tiempo ésta será correcta, pero es posible que el tiempo se agote y no encuentre ninguna solución.
| Demanda (Und) | P(x) |
|---|---|
| 10 | 0.08 |
| 25 | 0.1 |
| 40 | 0.15 |
| 55 | 0.24 |
| 70 | 0.21 |
| 85 | 0.15 |
| 100 | 0.07 |
| Demanda (Und) | LI | LS |
|---|---|---|
| 10 | 0 | 0.08 |
| 25 | 0.08 | 0.18 |
| 40 | 0.18 | 0.33 |
| 55 | 0.33 | 0.57 |
| 70 | 0.57 | 0.78 |
| 85 | 0.78 | 0.93 |
| 100 | 0.93 | 1 |
| Día | Aleatorio | Demanda | Q_compra | Cant.Periódicos_vendidos | Cant.Periódicos_n_vendidos | Costo_total_compra | Ingresos_por_ventas_regulares | Ingresos_por_salvamento | Utilidad_del_día |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.104514191 | 25 | 60 | 25 | 35 | $42,000 | $35,000 | $1,750 | $(5,250) |
| 2 | 0.69544312 | 70 | 60 | 60 | 0 | $42,000 | $84,000 | $- | $42,000 |
| 3 | 0.394948744 | 55 | 60 | 55 | 5 | $42,000 | $77,000 | $250 | $35,250 |
| 4 | 0.032563681 | 10 | 60 | 10 | 50 | $42,000 | $14,000 | $2,500 | $(25,500) |
| 5 | 0.200196337 | 40 | 60 | 40 | 20 | $42,000 | $56,000 | $1,000 | $15,000 |
| 6 | 0.070710608 | 10 | 60 | 10 | 50 | $42,000 | $14,000 | $2,500 | $(25,500) |
| 7 | 0.696331836 | 70 | 60 | 60 | 0 | $42,000 | $84,000 | $- | $42,000 |
| 8 | 0.926077618 | 85 | 60 | 60 | 0 | $42,000 | $84,000 | $- | $42,000 |
| 9 | 0.160636557 | 25 | 60 | 25 | 35 | $42,000 | $35,000 | $1,750 | $(5,250) |
| 10 | 0.694257057 | 70 | 60 | 60 | 0 | $42,000 | $84,000 | $- | $42,000 |
¿En qué consiste el Método Montecarlo?
Algoritmos Probabilísticos - Integración MonteCarlo
Método de Montecarlo y solver para resolver el problema del vendedor de periódicos. La Cartilla
Algoritmos Probabilísticos - Algoritmos Las Vegas (N Reinas)
Clase 8-3 Simulación computacional. Algoritmos probabilisticos: Las vegas tipo 1
import random
import matplotlib.pyplot as plt
mensaje_inicio = """
SIMULACION DE MONTECARLO - VENDEDOR DE PERIODICOS
Un distribuidor local de periodicos compra mañana una cantidad
fija de periodicos Q a 700$/unidad, para su posterior venta a
1400$/unidad.
Los periodicos que no son vendidos el mismo dia, se venden para
su reciclaje a un valor de salvamento de 50$/unidad.
De acuerdo con las anotaciones historicas del vendedor de
periodicos, la demanda diaria de periodicos esta dada
por la siguiente tabla de probabilidades:
Demanda P(x)
10 0.08
25 0.1
40 0.15
55 0.24
70 0.21
85 0.15
100 0.07
"""
COMPRA_UNIDAD = 700
VENTA_UNIDAD = 1400
SALVAMENTO_UNIDAD = 50
"Distribucion de la demanda"
distribucion_demanda = {
10: 0.08,
25: 0.1,
40: 0.15,
55: 0.24,
70: 0.21,
85: 0.15,
100: 0.07
}
demanda_unidad = list(distribucion_demanda.keys())
probabilidad_demanda = list(distribucion_demanda.values())
"Distribucion de la probabilidad"
distribucion_probabilidad = dict()
limite_inferior, limite_superior = float(), float()
for i in range(len(demanda_unidad)):
distribucion_probabilidad[demanda_unidad[i]] = {"LI": 0, "LS": 0}
limite_superior, limite_inferior = 0.0, 0.0
if i > 0:
limite_inferior = distribucion_probabilidad[demanda_unidad[i-1]]["LS"]
limite_inferior = round(limite_inferior, 3)
limite_superior = limite_inferior + distribucion_demanda[demanda_unidad[i]]
limite_superior = round(limite_superior, 3)
distribucion_probabilidad[demanda_unidad[i]]["LI"] = limite_inferior
distribucion_probabilidad[demanda_unidad[i]]["LS"] = limite_superior
"Calcular Utilidad promedio en un año"
def utilidad_promedio(cantidad_compra: int) -> float:
utilidades = list()
for _ in range(364):
random_number = random.random()
px_index = 0
for i in range(len(demanda_unidad)):
limite_inferior = distribucion_probabilidad[demanda_unidad[i]]["LI"]
limite_superior = distribucion_probabilidad[demanda_unidad[i]]["LS"]
if limite_inferior <= random_number <= limite_superior:
px_index = i
demanda = demanda_unidad[px_index]
periodicos_vendidos = min(demanda, cantidad_compra)
periodicos_no_vendidos = cantidad_compra - periodicos_vendidos
costo_total = cantidad_compra * COMPRA_UNIDAD
ingreso_ventas_regulares = periodicos_vendidos * VENTA_UNIDAD
ingreso_salvamento = periodicos_no_vendidos * SALVAMENTO_UNIDAD
utilidad = ingreso_salvamento + ingreso_ventas_regulares - costo_total
utilidades.append(utilidad)
promedio = round(sum(utilidades)/len(utilidades), 3)
return promedio
if __name__ == "__main__":
print(mensaje_inicio)
qs = [15,25,35,45,55,105]
promedios = list()
for i in qs:
r1 = utilidad_promedio(i)
r2 = utilidad_promedio(i)
r3 = utilidad_promedio(i)
r4 = utilidad_promedio(i)
promedio = round((r1+r2+r3+r4)/4, 3)
print("Q Cantidad =", str(i))
print(f"R1 -> {r1}\nR2 -> {r2}\nR3 -> {r3}\nR4 -> {r4}\nPromedio -> {promedio}\n")
promedios.append(promedio)
plt.plot(qs, promedios)
plt.title("Utilidad promedio")
plt.xlabel("Cantidad de compra")
plt.ylabel("Promedio")
plt.show()Un algoritmo tipo Las Vegas es un algoritmo de computación de carácter aleatorio (random) que no es aproximado: es decir, da el resultado correcto o informa que ha fallado
Un algoritmo de este tipo no especula con el resultado sino que especula con los recursos a utilizar en su computación.
De la misma manera que el método de Montecarlo, la probabilidad de encontrar una solución correcta aumenta con el tiempo empleado en obtenerla y el número de muestreos utilizado. Un algoritmo tipo Las Vegas se utiliza sobre todo en problemas NP-completos, que serían intratables con métodos determinísticos.
Existe un riesgo de no encontrar solución debido a que se hacen elecciones de rutas aleatorias que pueden no llevar a ningún sitio. El objetivo es minimizar la probabilidad de no encontrar la solución, tomando decisiones aleatorias con inteligencia, pero minimizando también el tiempo de ejecución al aplicarse sobre el espacio de información aleatoria.
La clase de complejidad de los problemas de decisión de estos algoritmos con ejecución polinómica es ZPP.
ZPP=RP*no-RP
Su esquema de implementación se parece al de los algoritmos de Montecarlo, pero se diferencian de ellos en que incluyen una variable booleana para saber si se ha encontrado la solución correcta.
Los algoritmos de Las Vegas fueron introducidos por László Babai en 1979, en el contexto del problema del isomorfismo de grafos , como un dual a los algoritmos de Monte Carlo . [4] Babai [5] introdujo el término "algoritmo de Las Vegas" junto con un ejemplo que involucra lanzamientos de monedas: el algoritmo depende de una serie de lanzamientos de monedas independientes, y existe una pequeña posibilidad de falla (sin resultado). Sin embargo, a diferencia de los algoritmos de Monte Carlo, el algoritmo de Las Vegas puede garantizar la exactitud de cualquier resultado informado.
// Algoritmo de Las Vegasrepetir: k = RandInt ( n ) si A [ k ] == 1 , return k ;
Como se mencionó anteriormente, los algoritmos de Las Vegas siempre devuelven resultados correctos. El código anterior ilustra esta propiedad. Una variable k se genera aleatoriamente; después de k se genera, k se usa para indexar la matriz A . Si este índice contiene el valor 1, se devuelve k ; de lo contrario, el algoritmo repite este proceso hasta que encuentra 1. Aunque se garantiza que este algoritmo de Las Vegas encontrará la respuesta correcta, no tiene un tiempo de ejecución fijo; debido a la aleatorización (en la línea 3 del código anterior), es posible que transcurra arbitrariamente mucho tiempo antes de que finalice el algoritmo.
- siempre que para una instancia de problema dada x∈X devuelve una solución s, se garantiza que s es una solución válida de x
- en cada instancia dada x, el tiempo de ejecución de A es una variable aleatoria RT A, x
- Se puede garantizar que los algoritmos completos de Las Vegas resuelvan cada problema solucionable dentro del tiempo de ejecución t max, donde t max es una constante dependiente de la instancia.
Los algoritmos de Las Vegas tienen diferentes criterios para la evaluación según el entorno del problema. Estos criterios se dividen en tres categorías con diferentes límites de tiempo, ya que los algoritmos de Las Vegas no tienen una complejidad de tiempo establecida. A continuación, se muestran algunos posibles escenarios de aplicación:
Tipo 1: no hay límites de tiempo, lo que significa que el algoritmo se ejecuta hasta que encuentra la solución.
Tipo 3: la utilidad de una solución está determinada por el tiempo necesario para encontrar la solución.
Para el Tipo 1, donde no hay límite de tiempo, el tiempo de ejecución promedio puede representar el comportamiento del tiempo de ejecución. Este no es el mismo caso para el tipo 2.
Para que un algoritmo de Las Vegas sea óptimo, se debe minimizar el tiempo de ejecución esperado. Esto se puede hacer mediante:
- El algoritmo de Las Vegas A ( x ) se ejecuta repetidamente durante algunos pasos del número t 1 . Si A ( x ) se detiene durante el tiempo de ejecución, entonces A ( x ) está terminado; de lo contrario, repita el proceso desde el principio durante otros t 2 pasos, y así sucesivamente.
- Diseñar una estrategia que sea óptima entre todas las estrategias para A ( x ), dada la información completa sobre la distribución de T A ( x ).
La existencia de la estrategia óptima podría ser una observación teórica fascinante. Sin embargo, no es práctico en la vida real porque no es fácil encontrar la información de distribución de T A ( x ). Además, no tiene sentido ejecutar el experimento repetidamente para obtener la información sobre la distribución, ya que la mayoría de las veces, la respuesta solo se necesita una vez para cualquier x . [10]
Los algoritmos de Las Vegas se pueden contrastar con los algoritmos de Monte Carlo , en los que los recursos utilizados están limitados pero la respuesta puede ser incorrecta con una cierta probabilidad (normalmente pequeña) . Mediante una aplicación de la desigualdad de Markov , un algoritmo de Las Vegas se puede convertir en un algoritmo de Monte Carlo ejecutándolo durante un tiempo establecido y generando una respuesta aleatoria cuando no termina. Mediante una aplicación de la desigualdad de Markov , podemos establecer el límite de la probabilidad de que el algoritmo de Las Vegas supere el límite fijo.
| Tiempo de ejecución | Exactitud | |
|---|---|---|
| Algoritmo de Las Vegas | probabilístico | cierto |
| Algoritmo de Monte Carlo | cierto | probabilístico |
Si está disponible una forma determinista de probar la corrección, entonces es posible convertir un algoritmo de Monte Carlo en un algoritmo de Las Vegas. Sin embargo, es difícil convertir un algoritmo de Monte Carlo en un algoritmo de Las Vegas sin una forma de probar el algoritmo. Por otro lado, cambiar un algoritmo de Las Vegas a un algoritmo de Monte Carlo es fácil. Esto se puede hacer ejecutando un algoritmo de Las Vegas durante un período de tiempo específico dado por el parámetro de confianza. Si el algoritmo encuentra la solución dentro del tiempo, entonces es un éxito y si no, la salida simplemente puede ser "lo siento".
Algoritmos Probabilísticos - Algoritmos Las Vegas (N Reinas)