- (Same as demo) Download the pre-trained models. Place the
modelsfolder as a top-level directory.
wget http://angjookanazawa.com/cachedir/hmmr/hmmr_models.tar.gz && tar -xf hmmr_models.tar.gz
Download these datasets:
- Penn Action Dataset
- Human3.6M
- Mosh Data on CMU and JointLimits in HMR Please note that the usage of this data is for non-comercial scientific research only.
If you use any of the data above, please cite the corresponding datasets and follow their licenses:
article{Loper:SIGASIA:2014,
title = {{MoSh}: Motion and Shape Capture from Sparse Markers},
author = {Loper, Matthew M. and Mahmood, Naureen and Black, Michael J.},
journal = {ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)},
volume = {33},
number = {6},
pages = {220:1--220:13},
publisher = {ACM},
address = {New York, NY, USA},
month = nov,
year = {2014},
url = {http://doi.acm.org/10.1145/2661229.2661273},
month_numeric = {11}
}
- Insta-Variety
- Vlog-people For evaluation, download the 3DPW dataset:
- 3DPW
All the data has to be converted into TFRecords and saved to a DATA_DIR of
your choice.
- Make
DATA_DIRwhere you will save the tf_records. For ex:
mkdir ~/hmmr/tf_datasets/
-
Edit
prepare_datasets.sh, with paths to where you downloaded the datasets, and setDATA_DIRto the path to the directory you just made. Please read the comments inprepare_datasets.shfor each dataset. Some require running a pre-processing script, which is spelled out inprepare_datasets.sh -
Follow the direction in
prepare_datasets.sh, for each dataset, uncomment each command and from the root HMMR directly (where README is), runprepare_datasets.sh:
sh prepare_datasets.sh
This takes a while! Start with UPenn and Human3.6M. Insta_variety and Vlog people are optional.
- In
do_train.shand/orsrc/config.py, setDATA_DIRto the path where you saved the tf_records.
Now we can start training.
A sample training script (with parameters used in the paper) is in
do_train.sh.
Update the path to in the beginning of this script and run:
sh do_train.sh
The training write to a log directory that you can specify.
Setup tensorboard to this directory to monitor the training progress like so:
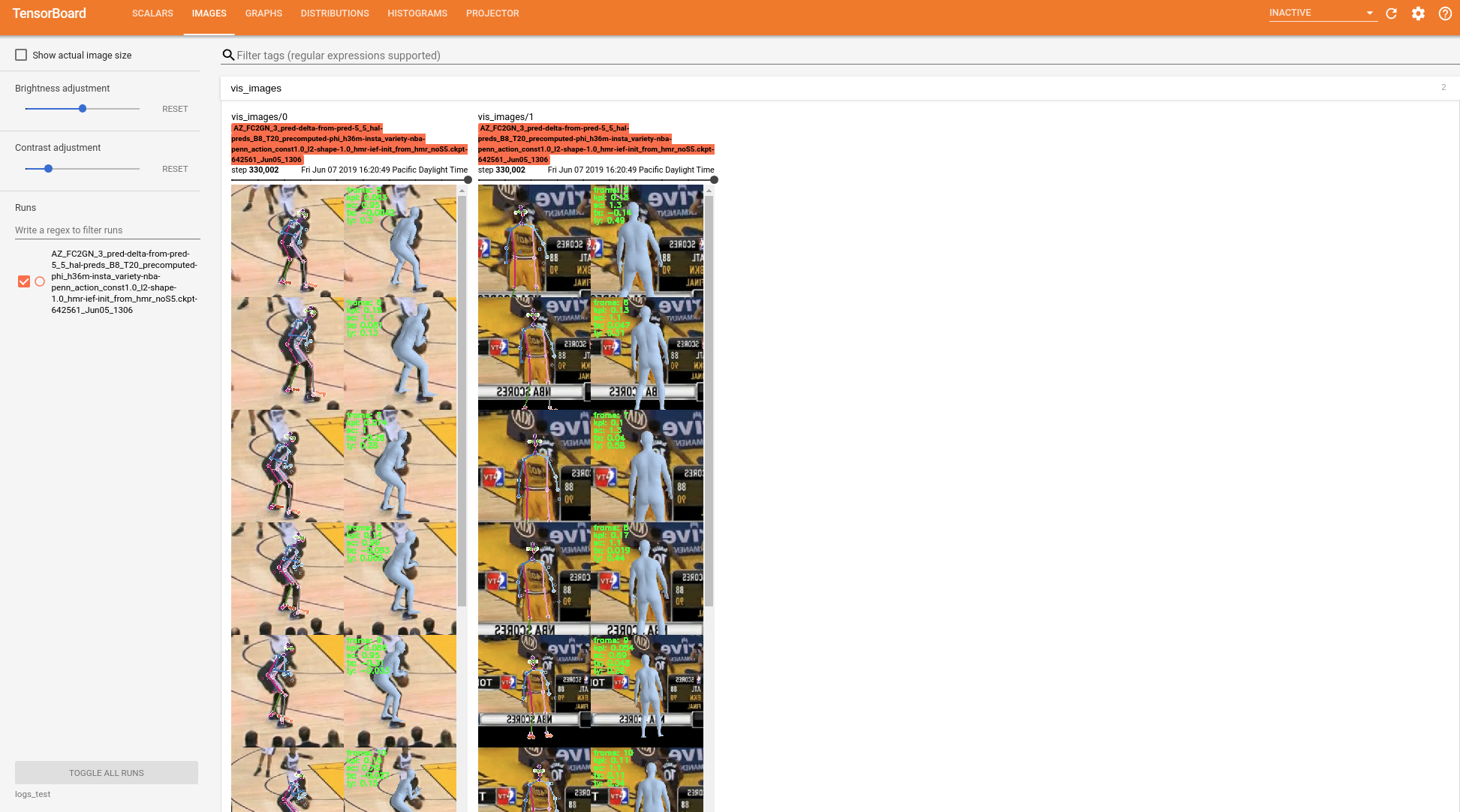
It's important to visually monitor the training! Make sure that the images loaded look right.
do_train.sh will use the default weights/setting. But see
src/config.py for more options.
Unfortunately, due to the licensing, the Human3.6M Mosh data is no longer available. This means you will not be able to reproduce exactly the public model since the supervision will not have the mosh values. Human3.6M data produced above will still have the 3D joint annotation, but not the SMPL values. We have re-trained our model on this setting where Human3.6M mosh data is not available, see doc/eval.md