[Lease.Azure] Unexpected cluster instability #1251
Comments
|
Can the issue be that I'm still using I'm now changing that to see if that changes the behavior. |
|
That could be the problem, yes. Please let us know if that fixes the problem. |
|
First impression is that the cluster is stable for now (but the issues back then only occurred after x hours) but there are still errors in the logs. It are errors with this blob file:
The errors are also pretty consistent, these are the failed dependency calls from the last 12 hrs: This is a stacktrace which is shown in our Application Insights: These errors started to happen after the upgrade. In Akka.Coordination.Azure |


|
We'll look into this, thanks! |
|
@wesselkranenborg updated #1256 to fix this, it appears that the Azure driver adds implicit preconditions implicitly even when we did not add any |
|
Good find! So basically it was only noise in the system which is gone in version 1.0.1? |
|
Its worse than a noise, I think. Since it is leaking exceptions, it might have unforseen consequences |
|
It was indeed worse then noise after investigation. It made our cluster completely unstable and now the exceptions are gone and processing of data is going good again. On our integration environment you can clearly see in the number of processed (outgoing) messages that it's stable again 😀 . Thanks for solving this. We'll test it a bit more and then we can move towards production with it. |

|
We still get (during deployments where a rebalance of the cluster happens) the following exceptions which we cannot explain:
During this period we also see Akka Deadletters in our logs on these shards. |
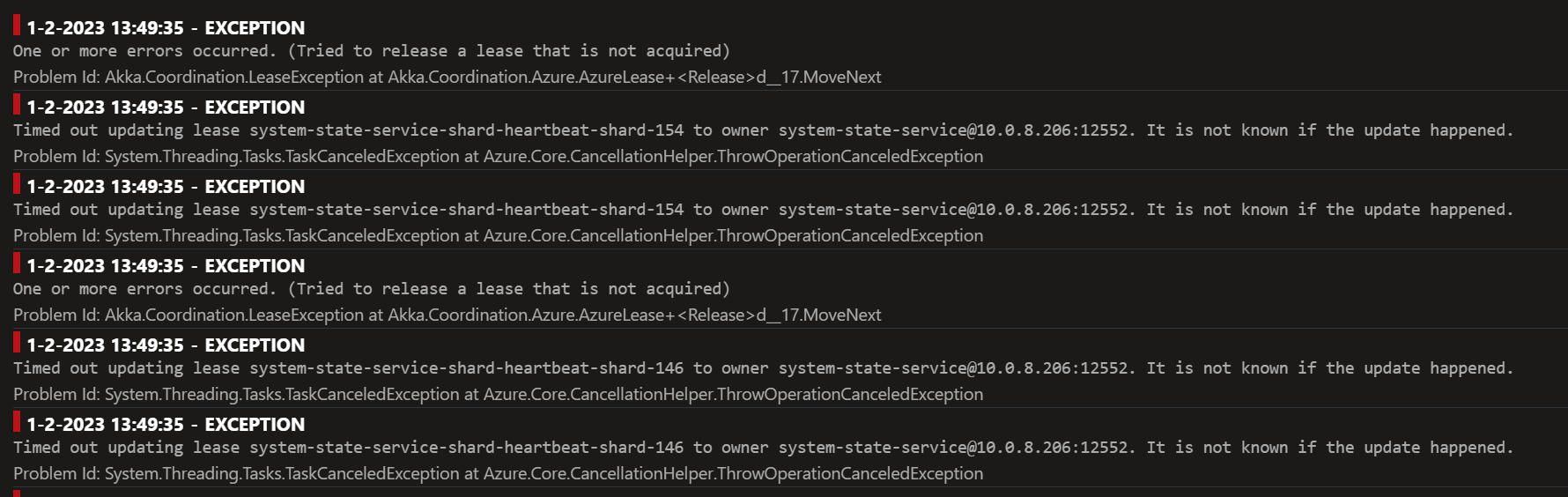
|
@wesselkranenborg Can I have a version list of all Akka related NuGet packages used in that build? |
|
Sure, here you go: <PackageReference Include="Akka" Version="1.4.49" />
<PackageReference Include="Akka.Cluster" Version="1.4.49" />
<PackageReference Include="Akka.Cluster.Hosting" Version="1.0.2" />
<PackageReference Include="Akka.Cluster.Sharding" Version="1.4.49" />
<PackageReference Include="Akka.Coordination.Azure" Version="1.0.1" />
<PackageReference Include="Akka.Discovery.Azure" Version="1.0.1" />
<PackageReference Include="Akka.HealthCheck.Cluster" Version="1.0.0" />
<PackageReference Include="Akka.HealthCheck.Hosting.Web" Version="1.0.0" />
<PackageReference Include="Akka.HealthCheck.Persistence" Version="1.0.0" />
<PackageReference Include="Akka.DependencyInjection" Version="1.4.49" />
<PackageReference Include="Akka.Management" Version="1.0.1" />
<PackageReference Include="Akka.Persistence.Azure" Version="0.9.2" />
<PackageReference Include="Akka.Persistence.Azure.Hosting" Version="0.9.2" />
<PackageReference Include="Akka.Serialization.Hyperion" Version="1.4.49" />
<PackageReference Include="Petabridge.Cmd.Cluster" Version="1.2.2" />
<PackageReference Include="Petabridge.Cmd.Cluster.Sharding" Version="1.2.2" />
<PackageReference Include="Petabridge.Cmd.Remote" Version="1.2.2" /> |
|
@wesselkranenborg do you use the Azure lease specifically for sharding, or do you also use it for the split brain resolver? |
|
For both, just like described here https://github.com/akkadotnet/Akka.Management/tree/dev/src/coordination/azure/Akka.Coordination.Azure#enable-in-sbr-using-akkaclusterhosting |
|
@Arkatufus : we use this configuration to be precise: |
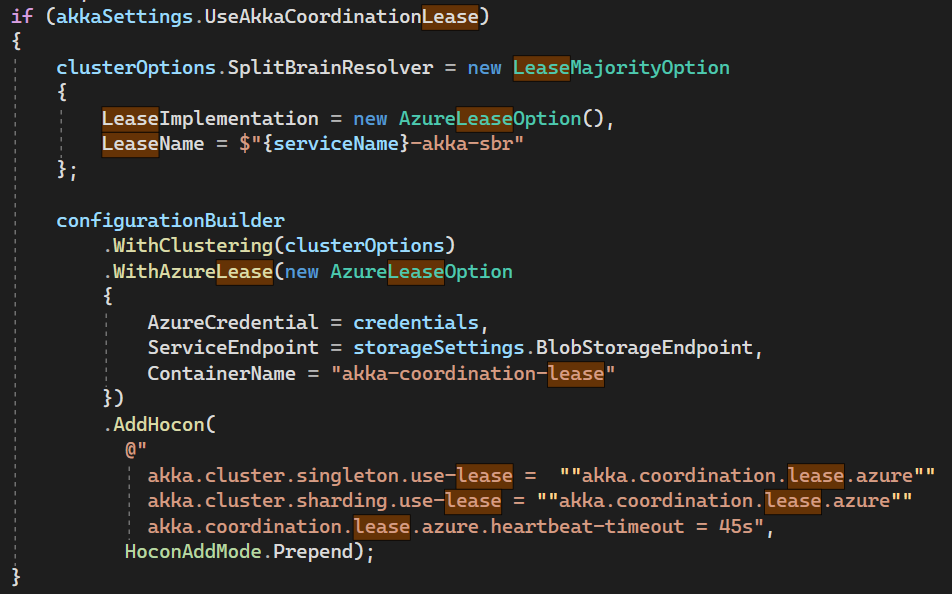
|
@wesselkranenborg can you give this code a try? if(akkaSettings.UseakkaCoordinationLease)
{
// Option instance
var leaseOptions = new AzureLeaseOptions
{
AzureCredential = credentials,
ServiceEndpoint = storageSettings.BlobStorageEndpoint,
ContainerName = "akka-coordination-lease",
HeartbeatTimeout = TimeSpan.FromSeconds(45)
}
clusterOptions.SplitBrainResolver = new LeaseMajorityOption
{
LeaseImplementation = leaseOptions,
LeaseName = $"{serviceName}-akka-sbr"
}
configurationBuilder
.WithClustering(clusterOptions)
.WithAzureLease(leaseOptions)
.WithSingleton<SingletonActorKey>(
singletonName: "mySingleton",
actorProps: mySingletonActorProps
options: new ClusterSingletonOptions(
LeaseImplementation = leaseOptions
)
);
}The main point is that all of the |
|
That's actually a good point, see now that these two have complete different options: Deployment to our integration environment is active now. I'll report tomorrow on the results of the test suite and stability over night. |

|
After updating this I still see this in the logging this morning. At this moment a rebalance was not even happening (we though it was related to that)
I also see these warning traces:
So it looks like the new lease is granted but there might be a hickup during these periodes, or am I wrong on that? |
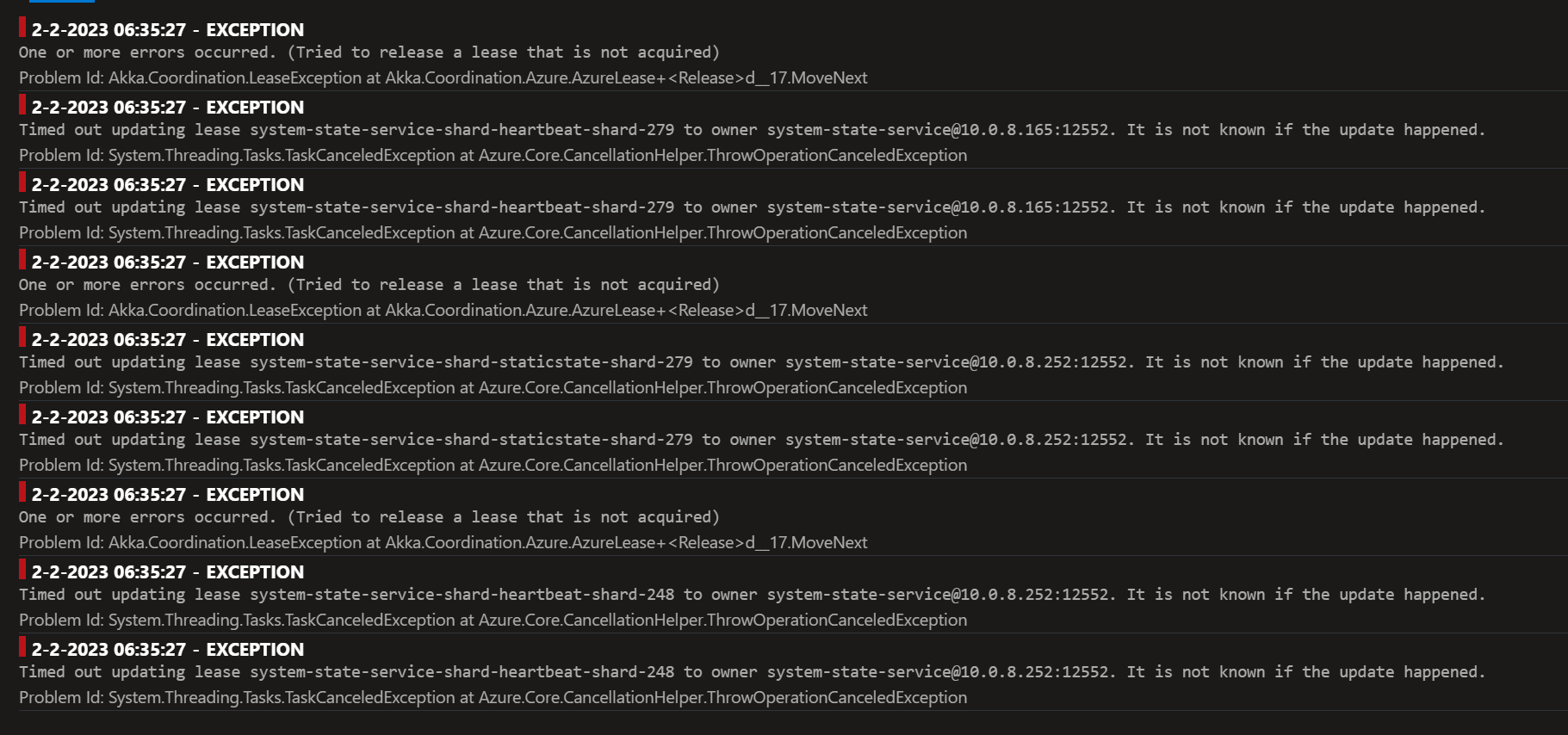

|
During the night it happened on more shards. We have 2 * 300 shards. Can it be that the Azure Storage cannot update the leases fast enough resulting in the timeout? Should we set the timeout higher? |

|
That is something I have no experience about as everything was tested using Azurite. One possible cause is that Windows limits the number of open ports that are available to a single process. The other possible cause is slow Azure connectivity and/or saturated Azure connection, this is something that needs to be tested using a benchmark because it is a total unknown. |
|
There are not unreachable nodes during these 'outages', maybe it is already fixed by the PR which just got merged back. I'm happy to try that out to see if that fixes some issues in our cluster. |
|
Are you running your cluster inside Kubernetes? If you are, a Kubernetes lease would make more sense because it will be running in local network. |
|
No, in Azure Container Apps |
|
Ok, we'll do another release so you can test the new changes. |
|
@Arkatufus I need to fix the cluster by deleting the journal/snapshots of the shardingCoordinator. Might have nothing to do with the Lease (might be more Akka.Persistence.Azure?) issue bug is popping up now again after upgrading this package :-) |
|
I'll delete those journal tables on our integration setup and see how the cluster forms then. |
|
Hmm, a redeploy was still busy while I was writing it up and that resolved the issue of this conflict. I'll let it run for a night and see how it behaves. |
|
@Arkatufus : most of the exceptions are gone during this night. It only seems that the SBR is not working correct with Akka.Coordination.Lease. During the night I saw that I had 3 clusters who were trying to create a cluster with each one node (resulting in a lot of warnings that a lease could not be aquired because it was already taken, but no exception anymore). The cluster creation there failed because I had configured that the number-of-contacts needed to be 3. In my storage container I also don't see the -sbr lease. I configure my sbr in the following way. Actual configuration of the SBR (in our build pipeline we run a production build): var clusterOptions = new ClusterOptions
{
Roles = new[] { "core" },
LogInfo = false
};
// lease option instance, please reuse in all shards, singletons, sbr, etc. configuration.
var leaseOptions = new AzureLeaseOption
{
AzureCredential = credentials,
ServiceEndpoint = storageSettings.BlobStorageEndpoint,
ContainerName = "akka-coordination-lease",
ApiServiceRequestTimeout = 10.Seconds(),
LeaseOperationTimeout = 25.Seconds()
};
if (builder.Environment.IsDevelopment())
{
configurationBuilder
.WithClustering(clusterOptions);
}
else
{
clusterOptions.SplitBrainResolver = new LeaseMajorityOption
{
LeaseImplementation = leaseOptions,
LeaseName = $"{serviceName}-akka-sbr",
Role = "core"
};
configurationBuilder
.WithClustering(clusterOptions)
.WithAzureLease(leaseOptions);
}Dump of the hocon on startup of the app When searching in the log for
But in the storage account I only see leases for the shard-regions, no |
This error is more and more happening right now, also in our production cluster. The result of it is that not all discovery points are available in the table storage and then the cluster starts to form separate clusters (split brain kind of scenarios). This then results in these kind of exceptions in the log and shards being unavailable. A restart of the nodes might solve the issue (temporary).
|
|
@Arkatufus might this not be related to this one also? akkadotnet/Akka.Hosting#211 As I've now disable coordination.lease completely and we still see this behavior |
|
@wesselkranenborg I'll dedicate my time tomorrow to look into this |
|
That would be great. I'm more and more convinced that it might be something in the discovery as well. This is our current Azure Table While we have 3 running nodes forming a cluster While this is our discovery setup And after a restart of the nodes the table is populated again with the nodes which are restarted. But then they don't join the already existing cluster because those records are gone from the table. And then multiple clusters are forming with multiple shard-region singleton coordinators and then I can indeed imagine that journal's already exist or that you get exceptions while reading them, thus leading to a shard-region which doesn't start. I've also tried the workaround for akkadotnet/Akka.Hosting#211 but that's not helping here |
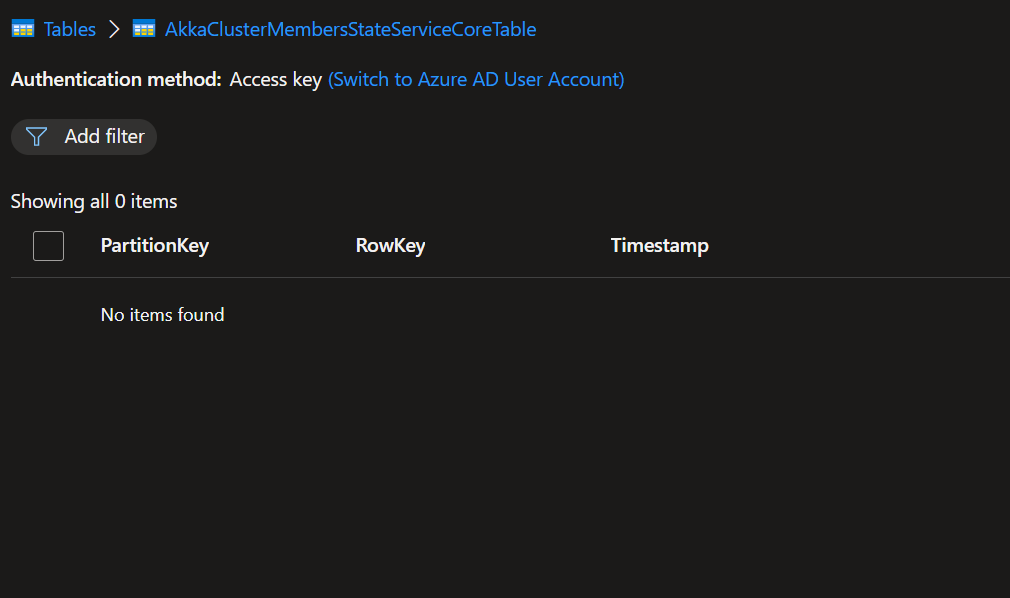

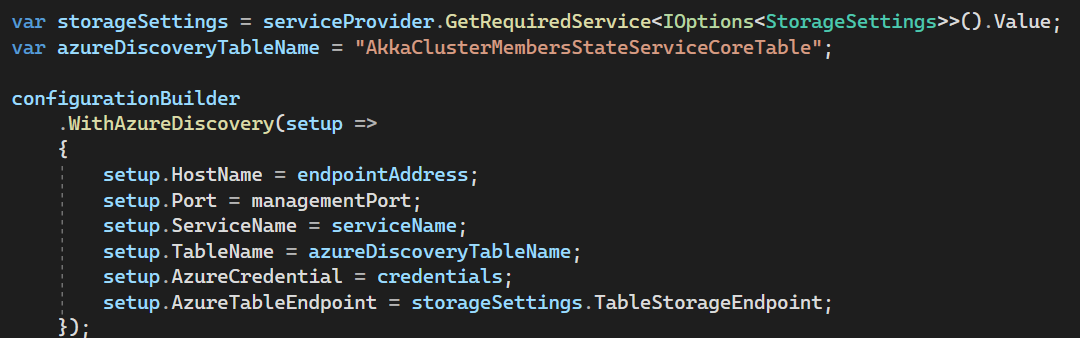
|
Just did a restart of our cluster on INT, this is the result:
The cluster now also runs without exceptions in the log and all shards are up and running. |

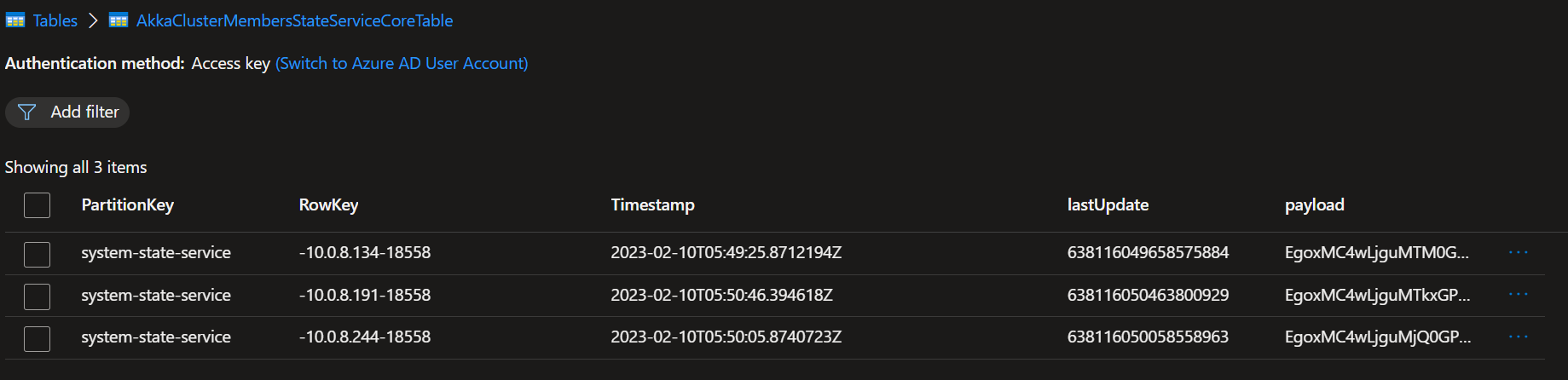
|
Without any exceptions happening this is now the result: |

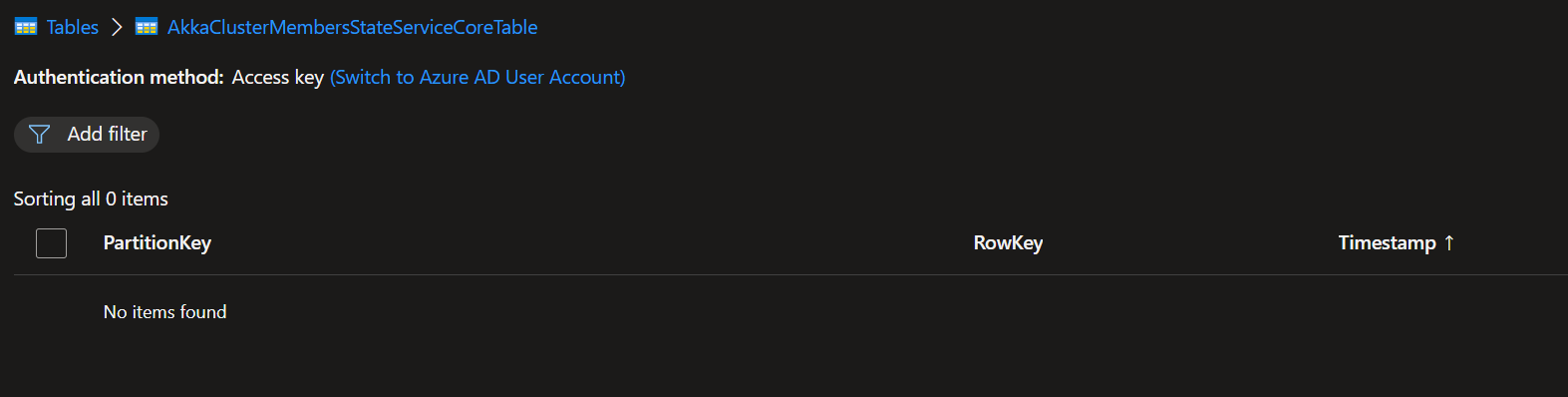
|
This is the current state (without exceptions)
But the current replica count is 10, so 3 nodes are not in the cluster and not in the table, they are on-their-own |


|
It seems as if all the entries were pruned somehow... let me check the code |
|
@wesselkranenborg can I see your |
|
Sure, this is what I can find in the logs (but I see this logmessage is being trimmed because of the length of the configuration): This is our hosting code: |
|
Also, do you have debug enabled in your test application? If so, can you see if something like this in the log? |
|
@Arkatufus No, we don't have that enable yet but can try to reproduce it with debug enabled. Which flag do I need to enable? |
|
Its the |
|
@Arkatufus: Yesterday I enabled debug logging and I indeed now see this verbose message:
This is the currenct state of the cluster:
|

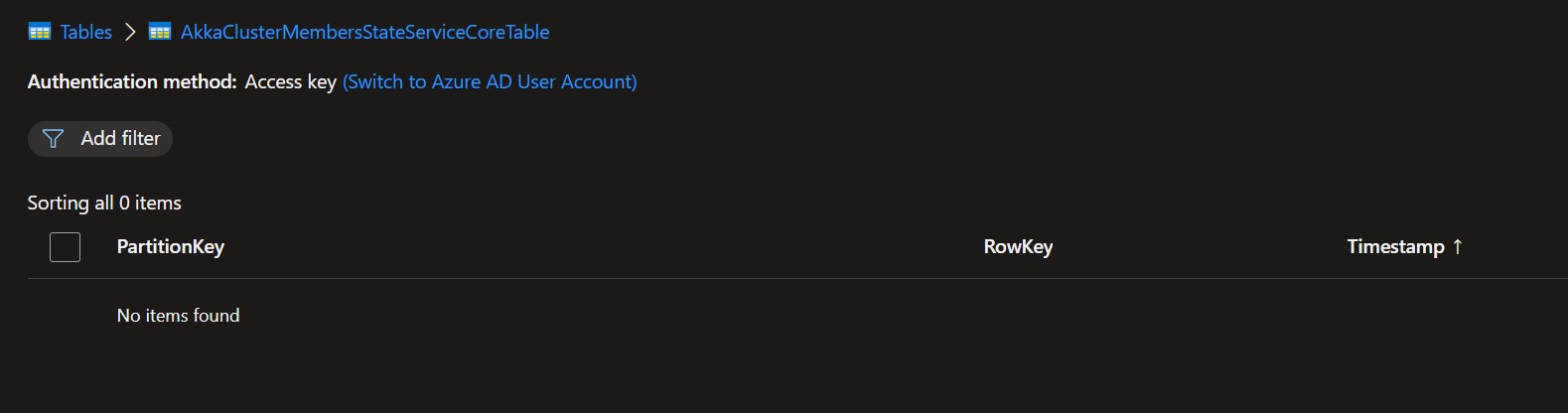
|
I'm pretty sure that the entries were pruned because each system failed to update their entries, this is related to time out exceptions in the original post. |
|
That's weird because I don't see any timeout errors in the log. Besides that I see that it suddenly stops logging behavior from the AzureDiscoveryGuardian and an hour after that the row entries are pruned. See this screenshot. Saterday night around 20.00 the deployment started and logging started to appear but without error it stops suddenly.
Sunday around 9.30 I see that one node got restarted by the cluster and the same behavior started. Logging appeared and suddenly it stops trace logging and one hour later the rows are pruned (again without exceptions or errors in the logs). I'll try to now first cleanup the cluster (as the journal/snapshot are corrupted now because of multiple clusters writing to the same storage) and try rerun with higher timeouts. I doubt if that will help as the 3 records are pruned a little more then one hour after the deployment, we see exact the same behavior on our dev cluster happening (the logs before are from our integration cluster which has real devices connected and thus a bit more traffic then dev). |


|
I doubt if the lastupdate column is properly updated. At what interval does that get an update? I'll post some data about that here (my cluster is manually recovered again and now works perfectly after pruning the journal/snapshots of the sharding and a restart of the nodes). This is my current discovery table. I'll post another one here in 15 minutes: |
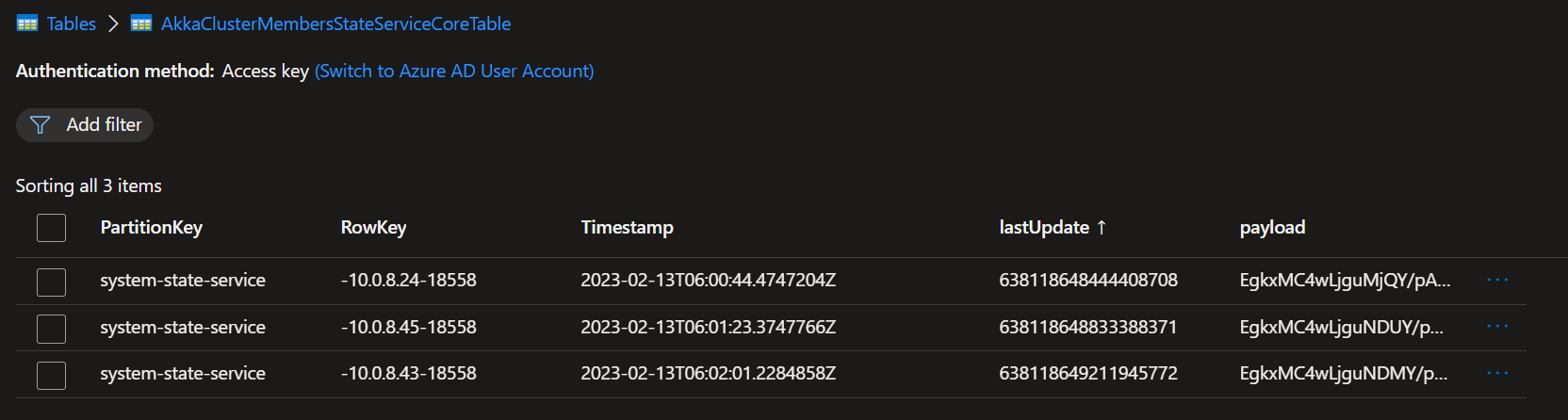
|
The lastupdate column is after almost 15 minutes still not updated (this is the column where according to the code the pruning is based on):
|
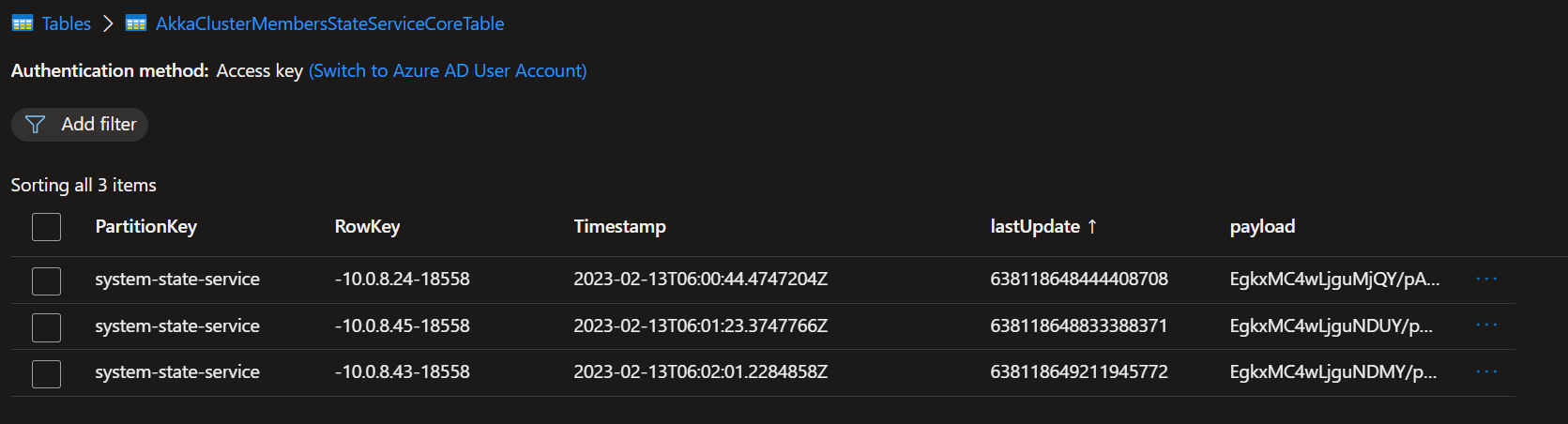
|
In the logging I also only see these logmessages (which correspond to the timestamp in above tables).
Same with these logging messages |
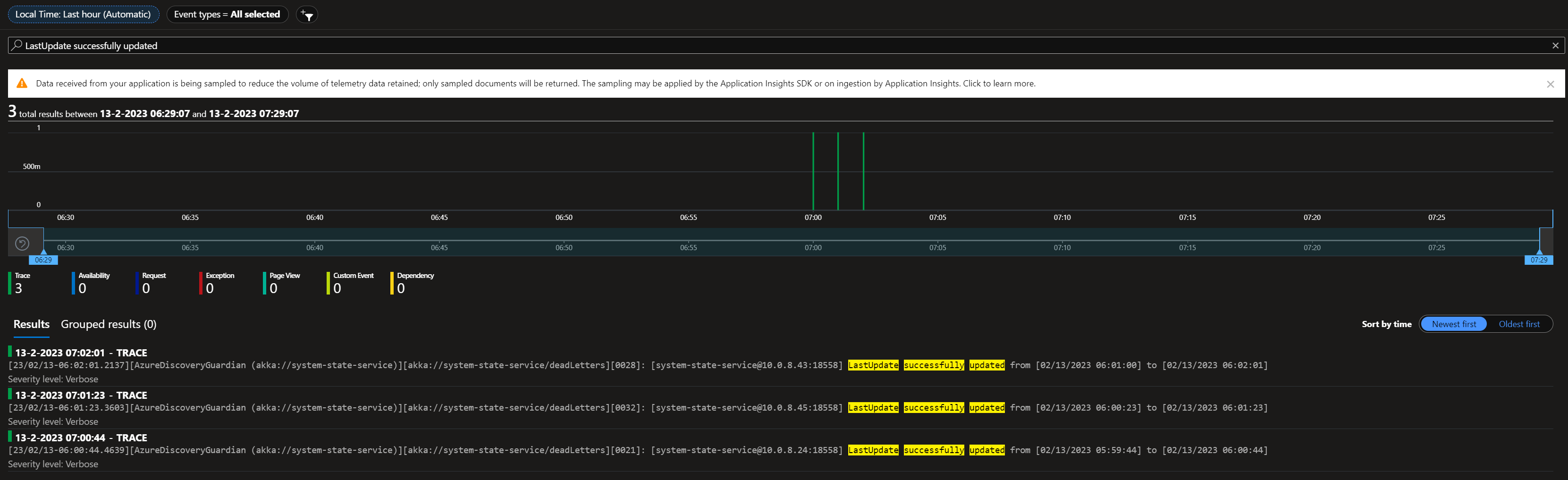

|
@Arkatufus Maybe it's good to also add that during this timeframe I got these messages in the logs (tells something about actors being created succesfully): And I didn't got any 'Failed to' messages in the logs (error logging from HeartbeatActor): And exactly one hour after the records are added to the table they got pruned indeed:
|
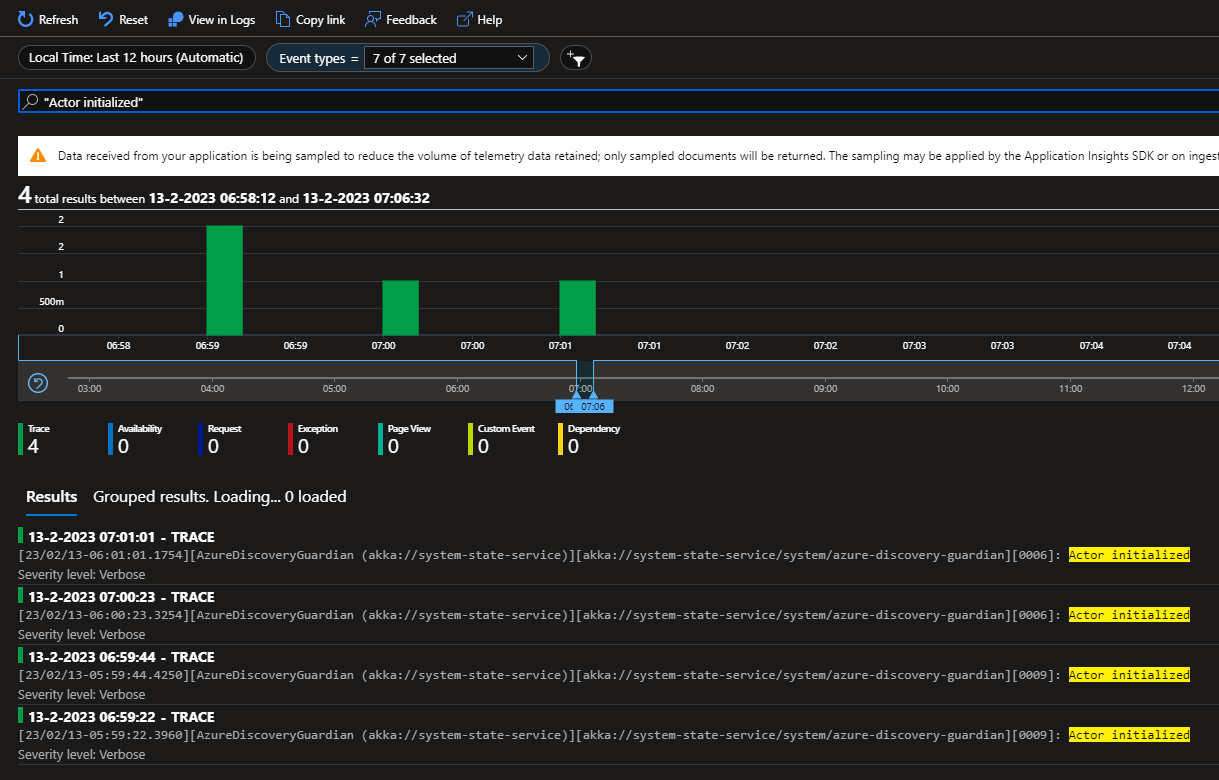
|
Thank you for a very detailed report, I think I can narrow down the bug now. |
|
I've a gut feeling that the boolean |
|
Updates/heartbeats are supposed to happen at 1 minute intervals, while node pruning checks are done every 1 hours. Nodes are pruned if they have not been updated (no heartbeat detected) over the past 5 minutes. |
|
So this is definetly a heartbeat problem, the heartbeat actor failed to do its job properly or the guardian actor failing to restart the heartbeat actor when it failed |
|
@wesselkranenborg I think I pinned down the bug, it was caused by assuming that |
Version Information
Version of Akka.NET? 1.4.48
Which Akka.NET Modules? Akka.Coordination.Azure 1.0.0-beta2
Describe the bug
After upgrading to these module versions:

Sharded cluster were unstable because the lease state were corrupted:
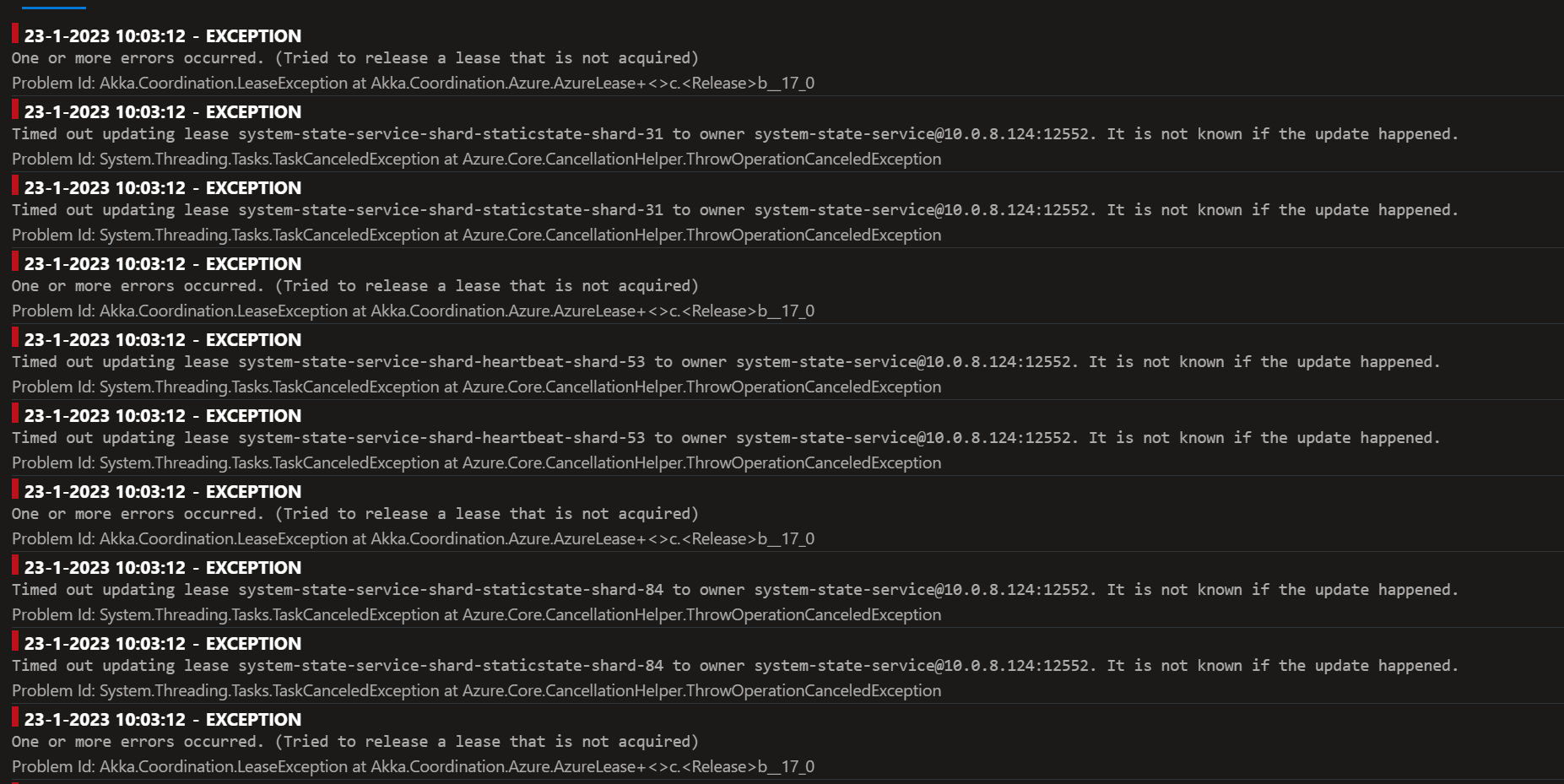
Expected behavior
Sharded cluster should be stable, lease should work as intended.
Actual behavior
Sharded cluster were unstable
The text was updated successfully, but these errors were encountered: