Preparing Data
In this section, we introduce graph data model and graph data format that Euler recognizes.
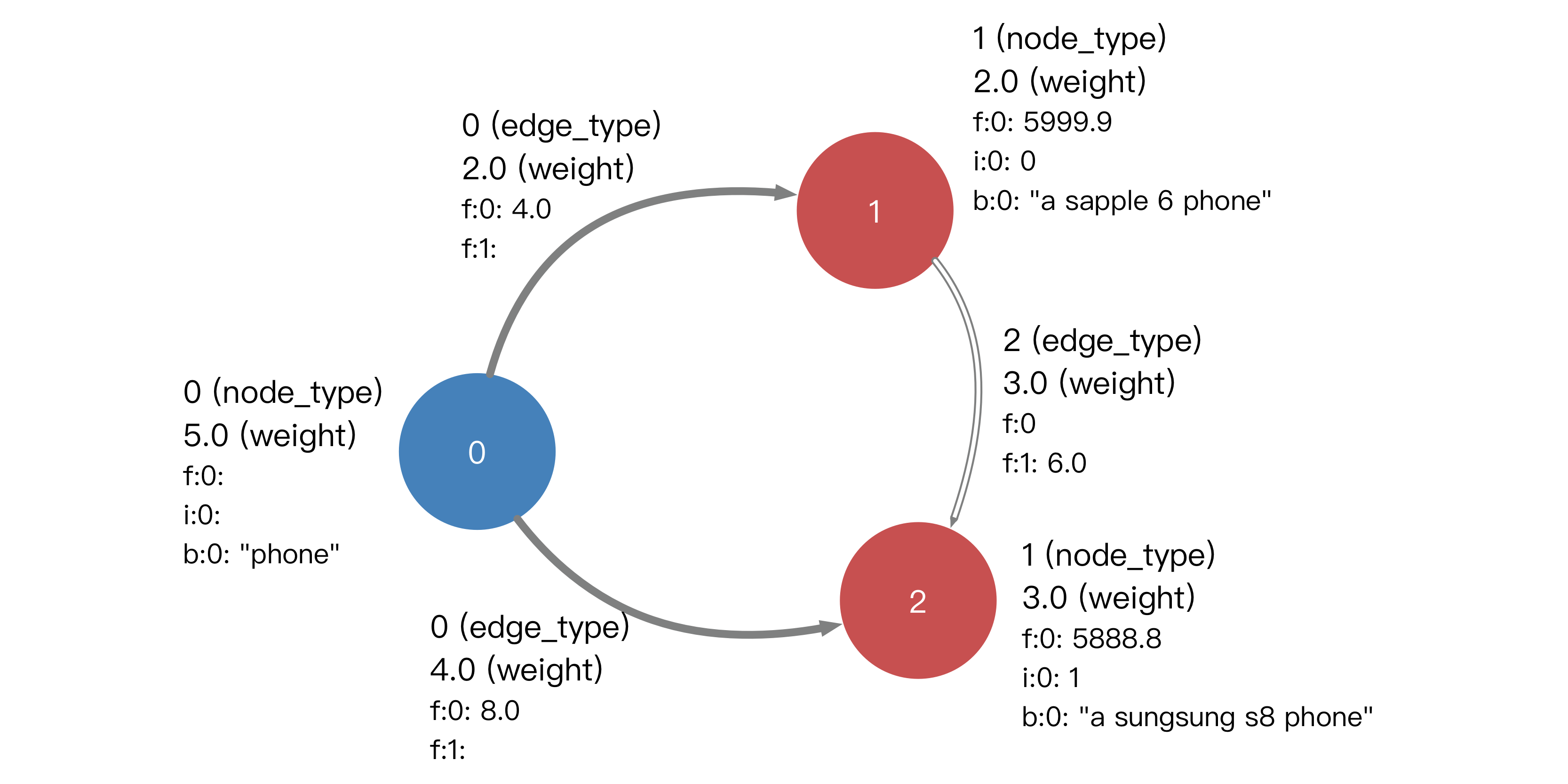
Euler supports weighted heterogeneous attributed graphs. In Euler, node and edge are the basic elements of a graph. Both nodes and edges can have types and weights. An edge is always considered to be directional and is marked by a triple tuple: <src node, dst node, edge type>, i.e., there can be multiple different types of edges between the same two nodes.
In addition, both nodes and edges can have attributes (or features). In Euler, the attributes are categorized into three classes: dense feature (float), sparse feature (uint64), binary feature (binary). Here's a simple example:

In Euler, the nodes are identified by uint64. The node types, edge types, and attribute types are all numbered independently as consecutive non-negative integers starting from 0. For the above example, we need to number the nodes and edges and their types and attributes to get a graph that Euler can recognize:
There are two formats of graph data in Euler: plain text format and binary format. The data in plain text format is based on JSON and contains both the graph data and the meta information, and is generally used for pre-processing preparation and debugging reading. The data in binary format is compression-optimized for quickly loading graph data when the graph engine is launched. Before using the graph engine, the graph data in plain text format needs to be converted to binary format first.
To efficiently load and search the edges associated with each node, Euler stores a graph in the adjacency table for both graph data and graph engine. That is, a node is stored with its outgoing edges, called a block. In plain text format, a block is a legal JSON with a fixed structure. The syntax is as follows:
{
"node_id": "node id, int",
"node_type": "node type, int",
"node_weight": "node weight, float",
"neighbor": {"edge type": {"neighbor id": "weight", "...": "..."}, "...": "..."},
"uint64_feature": {"feature id": ["int", "..."], "...": "..."},
"float_feature": {"feature id": ["float", "..."], "...": "..."},
"binary_feature": {"feature id": "string", "...": "..."},
"edge":[{
"src_id": "source node id, int",
"dst_id": "destination node id, int",
"edge_type": "edge type, int",
"weight": "edge weight, float",
"uint64_feature": {"feature id": ["int", "..."], "...": ["int", "..."]},
"float_feature": {"feature id": ["float", "..."], "...": ["float", "..."]},
"binary_feature": {"feature id": "string", "...": "..."}
}, "..."]
}In plain text format, each line of the graph data JSON file is parsed into a block. The graph in the above example can be written in the following plain text format:
{"node_id":0,"node_type":0,"node_weight":5.0,"neighbor":{"0":{"1":2.0,"2":4.0},"1":{}},"uint64_feature":{"0":[]},"float_feature":{"0":[]},"binary_feature":{"0":"phone"},"edge":[{"src_id":0,"dst_id":1,"edge_type":0,"weight":2.0,"uint64_feature":{},"float_feature":{"0":[4.0],"1":[]},"binary_feature":{}},{"src_id":0,"dst_id":2,"edge_type":0,"weight":4.0,"uint64_feature":{},"float_feature":{"0":[8.0],"1":[]},"binary_feature":{}}]}
{"node_id":1,"node_type":1,"node_weight":2.0,"neighbor":{"0":{},"1":{"2":3.0}},"uint64_feature":{"0":[0]},"float_feature":{"0":[5999.9]},"binary_feature":{"0":"a sapple 6 phone"},"edge":[{"src_id":1,"dst_id":2,"edge_type":1,"weight":3.0,"uint64_feature":{},"float_feature":{"0":[],"1":[6.0]},"binary_feature":{}}]}
{"node_id":2,"node_type":1,"node_weight":3.0,"neighbor":{"0":{},"1":{}},"uint64_feature":{"0":[1]},"float_feature":{"0":[5888.8]},"binary_feature":{"0":"a sungsung s8 phone"},"edge":[]}The meta information file describes the number of node/edge types and the number of three attributes of the nodes/edges in the graph. The meta information of the graph in the above example can be described as:
{
"node_type_num": 2,
"edge_type_num": 2,
"node_uint64_feature_num": 1,
"node_float_feature_num": 1,
"node_binary_feature_num": 1,
"edge_uint64_feature_num": 0,
"edge_float_feature_num": 2,
"edge_binary_feature_num": 0
}Euler provides a tool to convert a plain text data file into a binary data file.
If the data file is relatively small, users can directly convert the plain text data into binary data using the conversion tool included in euler.
python -m euler.tools -c simple_meta.json -i simple_graph.json -o simple_graph.datwhere simple_meta.json is the meta information file, simple_graph.json is the graph data file in plain text format, and the output binary file is simple_graph.dat. When starting the graph engine, users need to specify a graph data directory, and all files in this directory with the .dat suffix will be loaded as the graph data files.
If the data file is very large, the conversion can be done by using map-reduce. We also provide corresponding Java class to help users do it. The source code of the Java class is in tools/graph_data_parser. Users can use the BLockParser.java to convert a plain text block to byte[]. The main steps are as follows:
- Convert a meta JSON string to a meta object using the FastJson library.
Meta meta = JSON.parseObject(metaJSONString, Meta.class);- Convert the block JSON string to the block object with FastJson library.
Block block = JSON.parseObject(blockJSONString, Block.class);- Convert the block object to byte[] array.
byte[] bytes = new BlockParser(meta).BlockJsonToBytes(block)When deploying distributed training, users need to partition the graph data into multiple files, and each graph engine instance will only load a part of the files. Users need to implicitly specify a num_partitions, which should be greater than or equal to the number of graph engine instances, and is generally set to a value of 100 or higher.
Specifically, the files in the graph data directory need to be named in the form of xxx_<par_idx>.dat, where <par_idx> is the partition index, and the largest <par_idx> + 1 in the directory is the num_partitions of the graph data. The same partition index can correspond to multiple graph data files, that is, all the files with the same _<par_idx>.dat suffix form a partition. Each partition only contains nodes with identity that node_id % num_partitions = par_idx.
For example, if we divide the above graph into two partitions, the graph data files are as follows:
# simple_graph_0.dat
{"node_id":0,"...":"..."}
{"node_id":2,"...":"..."}
# simple_graph_1.dat
{"node_id":1,"...":"..."}