全空间多任务模型(ESMM)
Entire Space Multi-task Model (ESMM)[1] 是阿里妈妈精准定向广告算法团队研发的新型多任务联合训练算法范式。
在诸如信息检索、推荐系统、在线广告投放系统等工业级的应用中准确预估转化率(post-click conversion rate,CVR)是至关重要的。例如,在电商平台的推荐系统中,最大化场景商品交易总额(GMV)是平台的重要目标之一,而GMV可以拆解为流量×点击率×转化率×客单价,可见转化率是优化目标的重要因子;从用户体验的角度来说准确预估的转换率被用来平衡用户的点击偏好与购买偏好。
传统的CVR预估任务通常采用类似于CTR预估的技术,比如最近很流行的深度学习模型。然而,有别于CTR预估任务,CVR预估任务面临一些特有的挑战:1) 样本选择偏差;2) 训练数据稀疏;3) 延迟反馈等。
ESMM模型利用用户行为序列数据在完整样本空间建模,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。另一方面,ESMM模型首次提出了利用学习CTR和CTCVR的辅助任务迂回学习CVR的思路。ESMM模型中的BASE子网络可以替换为任意的学习模型,因此ESMM的框架可以非常容易地和其他学习模型集成,从而吸收其他学习模型的优势,进一步提升学习效果,想象空间巨大。
本文旨在介绍ESMM以及如何使用ESMM开源项目进行实际业务生产所用,阅读完成后,你可以了解到:
- ESMM的基本系统组成
- ESMM开源代码的运行和使用
- 应用ESMM到具体实践的方法
受限于篇幅以及主旨,以下内容本文不涉及,或请参阅相关文档:
- XDL训练平台的系统组成和使用(REF URL:)
- 公开数据集的下载、使用和授权
- Ali-CCP:Alibaba Click and Conversion Prediction请参阅:https://tianchi.aliyun.com/datalab/dataSet.html?dataId=408
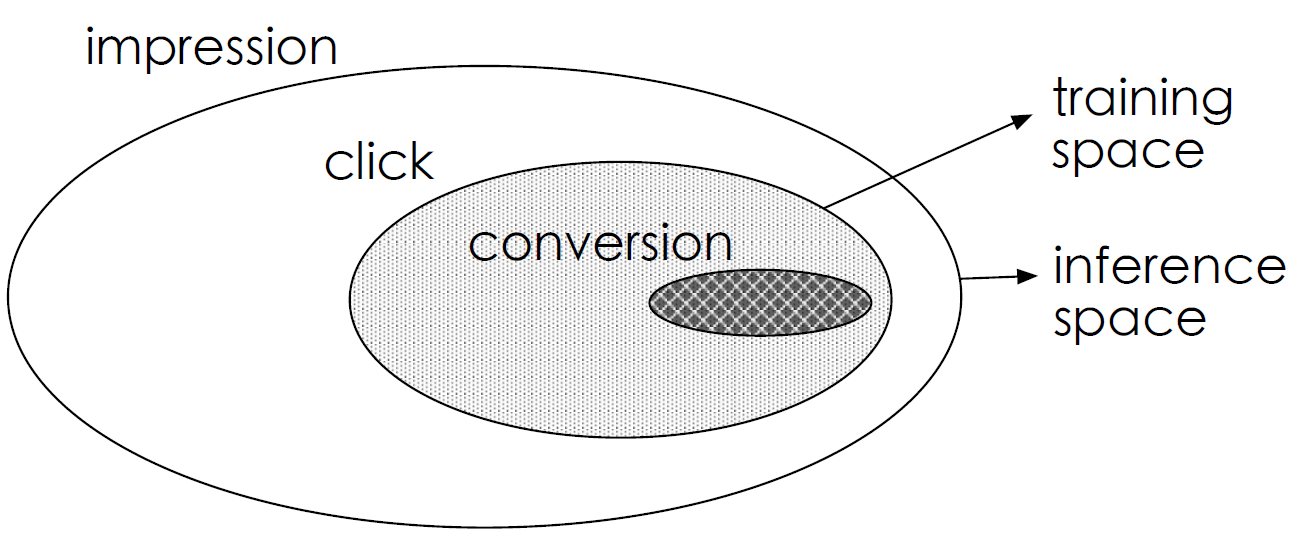
ESMM 充分利用用户行为的序列模式,在 CTR 和 CTCVR 两项辅助任务的帮助下,优雅地解决了在实践中遇到的 CVR 建模
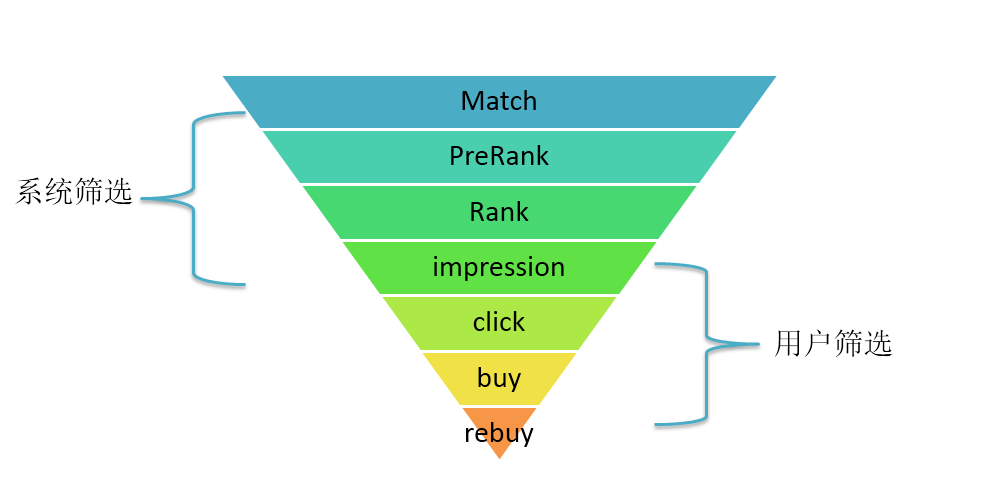
广告或推荐系统中,用户行为的系统链路可以表示为 $召回 \rightarrow 粗排 \rightarrow 精排 \rightarrow 展现 \rightarrow 点击 \rightarrow 转化 \rightarrow 复购 $ 的序列。通常我们在引擎请求的时候进行多阶段的综合排序并不断选取头部的子集传给下一级,最终在展现阶段返回给用户。每阶段任务的输入量级都会因为上一阶段任务经过系统筛选(比如 召回到粗排、粗排到精排、精排到展现)或者用户主动筛选(比如 展现到点击、点击到转化、转化到复购)而逐步减少。ESMM 适用于成熟的电商推荐或者广告全链路预估系统。我们也希望本文的读者或者使用者如果在ESMM应用的实践中有任何困难,可随时与我们联系:XDL_TECHNICAL_SUPPORT_EMAIL_ADDRESS
ESMM 引入两个预估展现点击率(CTR)和展现后点击转化率(CTCVR)作为辅助任务。ESMM 将 pCVR 作为一个中间变量,并将其乘以 pCTR 得到 pCTCVR,而不是直接基于有偏的点击样本子集进行 CVR 模型训练。pCTCVR 和 pCTR 是在全空间中以所有展现样本估计的,因此衍生的 pCVR 也适用于全空间并且缓解了

pCTR 和 pCTCVR 是 ESMM 在全空间实际预估的变量。这种乘法形式使得三个关联和共同训练的分类器能够在训练期间利用数据的序列模式并相互传递信息。 ESMM的损失函数如下,它由 CTR 和 CTCVR 任务中的两个损失项组成,这些任务通过所有展现次数的样本进行计算。 \begin{equation} \begin{split} L(\theta*{cvr}, \theta*{ctr}) = \sum*{i=1}^N l(y_i, f(\textbf{x}i;\theta{ctr})) + \sum*{i=1}^N l(y_i&z_i, f(\textbf{x}i;\theta{ctr}) \times f(\textbf{x}i;\theta{cvr})) \end{split} \end{equation}
其中
正如 BASE 模型部分介绍的那样,Embedding Layer 将大规模稀疏输入映射到低维稠密向量中,它占据深度网络的大部分参数,需要大量的样本来进行训练。在 ESMM 中,CVR 网络的 Embedding 参数与 CTR 任务共享。它遵循特征表示转化学习范式。CTR 任务所有展现次数的样本规模比 CVR 任务要丰富多个量级。该参数共享机制使 ESMM 中的 CVR 网络可以从未点击的展现中学习,缓解了数据稀疏性问题。
它主要由两个子网组成:CVR 网络在图的左边部分和右边部分的 CTR 网络。 CVR 和 CTR 网络都采用与 BASE 模型相同的结构。 CTCVR 将 CVR 和 CTR 网络的输出结果相乘作为输出。其中每个子网络结果可以被替代为任意的分类预估网络。
CTR网络搭建、CVR网络搭建
损失函数定义。
- 数据准备:按照前序流程,完成“数据处理”
- 环境准备:按照XDL的部署手册,完成XDL基本运行环境部署,推荐使用docker方式运行XDL提供的ubuntu镜像: registry.cn-hangzhou.aliyuncs.com/xdl/xdl:ubuntu-gpu-mxnet1.3)
-
在宿主机上安装docker
-
进入docker镜像,并将对应算法目录挂载进docker内:
sudo docker run --net=host -v path_to_esmm:/home/xxx/ESMM -it registry.cn-hangzhou.aliyuncs.com/xdl/xdl:ubuntu-gpu-mxnet1.3 /bin/bash
-
config.json配置说明
- files: 指定训练样本或测试样本集
- is_training: 训练设为true,test设为false
- checkpoint: test时使用ckpt指定训练保存的模型路径
-
训练&测试命令
cd /home/xxx/ESMM/script python esmm.py --run_mode=local --ckpt_dir=./ckpt --config=config.json
-
参数说明
--run_mode, required, 运行模式,local表示本地运行。 --ckpt_dir, required, 模型保存路径。 --config, required, 配置文件
[1] Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate. SIGIR (2018).