Kyoto Tycoon is a lightweight network server on top of the Kyoto Cabinet key-value database, built for high-performance and concurrency. Some of its features include:
- master-slave and master-master replication
- in-memory and persistent databases (with optional binary logging)
- hash and tree-based database formats (with optional compression)
- server-side scripting in Lua (API)
It has its own fully-featured protocol based on HTTP and a (limited) binary protocol for even better performance. There are several client libraries implementing them for multiple languages (we're maintaining one for Python here).
It can also be configured with simultaneous support for the memcached protocol, with some limitations on available data update commands. This is useful if you wish to replace memcached in larger-than-memory/persistency scenarios.
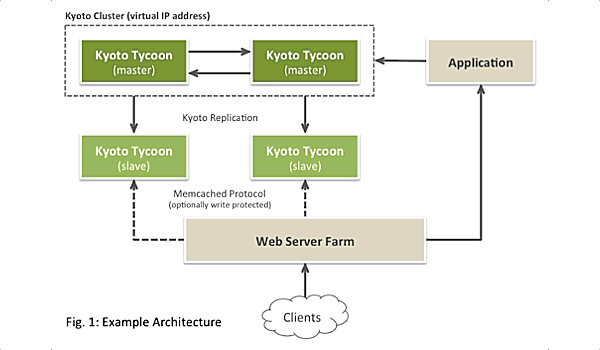
The development of Kyoto Tycoon and Kyoto Cabinet by their original authors at FAL Labs seems to have halted around 2012. The software works as advertised and is very reliable, which may explain the lack of activity, but the unmodified upstream sources fail to build in recent operating system releases (with recent compilers).
We at Altice Labs (previously at SAPO) intend this repository to be a place to keep readily usable (but conservative) versions for modern machines. Nevertheless, pull requests containing bug fixes or new features are welcome.
Here you can find improved versions of the latest available upstream releases, intended to be used together and tested in real-world production environments. The changes include bug fixes, minor new features and packaging for a few Linux distributions.
Check our stable release history to see what's new.
Our primary target platform for these packages is Linux (64-bit). Mostly Debian and CentOS, but we've also done some testing on non-Linux platforms such as FreeBSD and MacOS X.
The upstream sources claim to support additional platforms, but we haven't got around to test them for ourselves (yet). If you do, let us know.
Download our latest stable source release or clone the repository from GitHub. Then, to build and install the Kyoto Cabinet library and the Kyoto Tycoon server in one go, run:
$ make PREFIX=/usr/local
$ sudo make install
Notes:
- Make sure you have zlib, lzo and Lua 5.1.x already installed;
- The installation root directory (
PREFIX) is optional. By default it already installs into/usr/local; - If you're building on FreeBSD, use
gmakefrom the ports collection instead of standardmake.
Instead of installing directly from source, you can optionally build packages for one of the Linux distributions listed below. If you distribution of choice doesn't happen to be supported, patches are always welcome.
On Debian, build a binary .deb package (into the ./build directory) by running:
$ make deb
On Red Hat Linux (or a derivative such as CentOS), build both source and binary .rpm packages (into the $HOME/rpmbuild directory) by running:
$ make rpm
$ make rpm-selinux # (optional) builds an extra package containing a hardened SELinux policy
Besides being cleaner and more maintainable than installing directly from source, these packages also register init scripts to run the server with minimal privileges and install configuration files pre-filled with some examples.
If there's a place in need of improvement it's the documentation for the available server options in Kyoto Tycoon. Make sure to check the command-line reference to understand what each option means and how it affects performance vs. data protection. But you may want to try this as a quick start for realistic use:
$ /usr/local/bin/ktserver -ls -th 16 -port 1978 -pid /data/kyoto/kyoto.pid \
-log /data/kyoto/ktserver.log -oat -uasi 10 -asi 10 -ash \
-sid 1001 -ulog /data/kyoto/db -ulim 104857600 \
'/data/kyoto/db/db.kct#opts=c#pccap=256m#dfunit=8'
This will start a standalone server using a persistent B-tree database with compression (opts=c) and binary logging enabled. The pccap=256m option increases the default page cache memory to 256MB.
The data durability options (-oat, -uasi, -asi, -ash) have a significant performance impact and you may want to consider leaving them out if you're storing volatile data (which is the main use case for Kyoto Tycoon anyway).
If you have an idea of how many objects you'll be storing, you can use a persistent hash database instead:
$ /usr/local/bin/ktserver -ls -th 16 -port 1978 -pid /data/kyoto/kyoto.pid \
-log /data/kyoto/ktserver.log -oat -uasi 10 -asi 10 -ash \
-sid 1001 -ulog /data/kyoto/db -ulim 104857600 \
'/data/kyoto/db/db.kch#opts=l#bnum=1000000#msiz=256m#dfunit=8'
In this case bnum=1000000 configures 1 million hash buckets (should be set to about twice the number of expected keys) and msiz=256m sets the size of the memory mapped region (larger is better, provided you have enough RAM). Like the B-tree database above, performance considerations about data durability options also apply here.
Another example, this time for an in-memory cache hash database limited to 256MB of stored data (LRU-based):
$ /usr/local/bin/ktserver -log /var/log/ktserver.log -ls '*#bnum=100000#capsiz=256m'
To enable simultaneous support for the memcached protocol, use the -plsv and -plex parameters. The previous example would then become:
$ /usr/local/bin/ktserver -log /var/log/ktserver.log -ls \
-plsv /usr/local/libexec/ktplugservmemc.so \
-plex 'port=11211#opts=f' \
'*#bnum=100000#capsiz=256m'
The opts=f parameter enables flags support for the memcached protocol. These are stored by Kyoto Tycoon as the last 4 bytes of the value, which means some care must be taken when mixing protocols (our python library can handle this for you, for example).
Based on our experience, you should consider a few things when using Kyoto Tycoon in production:
-
Don't use the
capsizoption with on-disk databases as the server will temporarily stop responding to free up space when the maximum capacity is reached. In this case, try to keep the database size under control using auto-expiring keys instead. -
On-disk databases are sensitive to disk write performance (impacting record updates as well as reads). Enabling transactions and/or synchronization makes this worse, as does increasing the number of buckets for hash databases (larger structures to write). Having a disk controller with some kind of battery-backed write-cache makes these issues mute.
-
Choose your on-disk database tuning options carefully and don't tune unless you need to. Some options can be modified by a simple restart of the server (eg.
pccap,msiz) but others require creating the database from scratch (eg.bnum,opts=c). -
Make sure you have enough disk space to store your on-disk databases as they grow. The server uses
mmap()for file access and handles out-of-space conditions by terminating immediately. The database should still be consistent if this happens, so don't fret too much about it. -
The unique server ID (
-sid) is used to break replication loops (a server instance ignores keys with its own SID). Keep this in mind when restoring failed master-master instances. The documentation recommends always choosing a new SID but this doesn't seem a good idea in this case. If the existing master still has keys from the failed master with the old SID pending replication, the new master with a new SID will propagate them back.

{kind=link}