The finished product can be viewed here
.png)
-
SPAM SMS Detector is an end-to-end Machine Learning NLP project built using Flask and deployed to Heroku Cloud Platform. This app will help you predict whether the SMS that you recieved is legit (HAM) or SPAM. The dataset used for this project is taken from Kaggle has 5,574 records, 749 SPAM and 4,825 HAM, more info about the data in "About the Data" section.
-
Out of all the ML models used Naive Bayes seems to have preformed decent with accuracy of 99.01% and precision of 98.56%. Built various pipelines with MultinomialNB classifier and Bag of Words as well as TFIDF approach, taking different classification metrices (Accuracy, Precision, f1-score, roc-auc-score) into account, also tuned the hyperparameters. The final output looks something like this -
 .
.
More on that in this section.
- The final pipeline chosen has the following performance report -
score accuracy 99.01 f1-score 96.14 precision 98.56 recall 93.83 roc auc score 96.81
- As a part of #66daysoddata community created by Ken Jee from youtube, I did this project to be consistent in my DS, ML and DL learning journey and building a habit of doing Data Science daily.
- And also because my curiosity in NLP has spiked to an extent where I have feed myself with the text data and perform some analysis on it on a daily basis. I also want to explore, what more I can do with NLP
- Our dataset originally has 5,574 records, 749 SPAM and 4,825 HAM, which you can see from the distribution below.
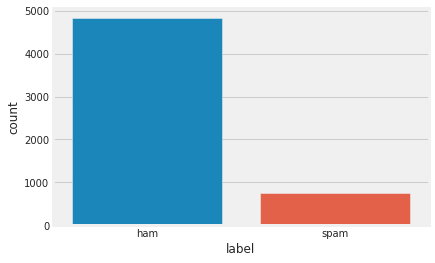
- Our dataset is clearly imbalanced, but trust me, with Naive Bayes as our model used, the imbalanced dataset seems to have no affect on the performance, as our accuracy and precision, both are decent.
-
SPAM SMSs tends to be bigger than legit SMSs, which is evident from the graph below.
.png)
- Mean length of SPAM SMSs is close to 140, which is almost double the length of Legitmate SMS which is close to 71.
-
The most common words used in SPAM messages can be seen from the WordCloud below.
.png)
-
For more detailed analysis, you can have a look at my Ipython Notebook for SPAM SMS EDA and Preprocessing
.png)
-
I used Naive Bayes because it
- works well with large no. of features, and after performing Word Vectorization, no. of features has become more than 6000.
- converges faster while training the model.
- works well with categorical data.
- is preferrable while working with the text data.
- outperformed other models like SVM, Logistic Regression etc.
-

-
I performed GridSearchCV 4 times, each time I aim at different metrics to optimize and hence constructed 4 different pipelines.
- Pipeline 1 - Aimed for better Accuracy
- Pipeline 2 - Aimed for better F1-Score
- Pipeline 3 - Aimed for better Precision
- Pipeline 4 - Aimed for better ROC-AUC
-
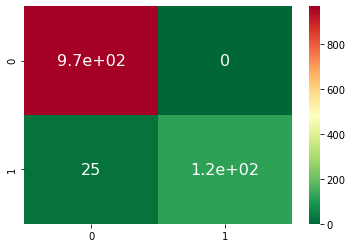
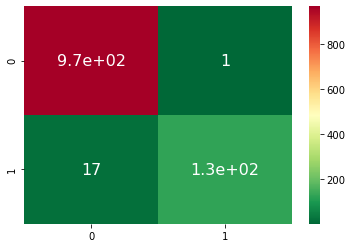
Confusion Matrix for all the pipelines can be seen below -
-
Pipeline 1: Accuracy
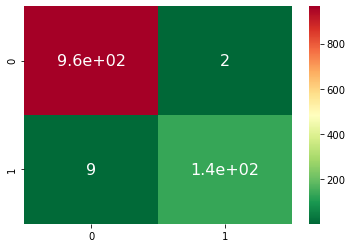
-
Pipeline 2: F1-Score
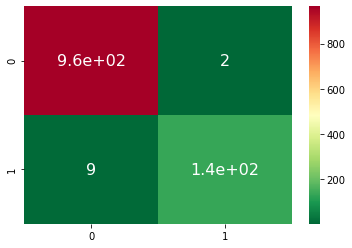
-
Pipeline 3: Precision
-
Pipeline 4: ROC-AUC-Score
-
-
Performance Report of all the Pipelines -
pipeline1 pipeline2 pipeline3 pipeline4 accuracy 0.990117 0.990117 0.977538 0.983827 f1-score 0.961404 0.961404 0.906367 0.934783 precision 0.985612 0.985612 1.000000 0.992308 recall 0.938356 0.938356 0.828767 0.883562 roc auc score 0.968144 0.968144 0.914384 0.941264 -
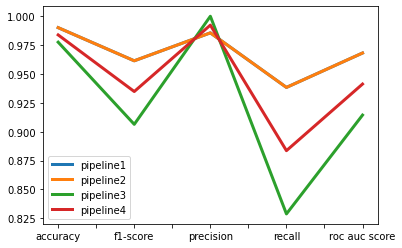
When we aim for better accuracy and f1-score, we get exactly same report. Therefore, Pipeline1 and Pipeline2 will work similarly, which is evident from their Confusion Metrices.
-
When we aimed for better precision, we get Zero False Positives, but it has impacted other metrices like Accuracy, Recall, f1-score and ROC-AUC-Score
-
Pipeline4 worked fine.
-
Their performance can be seen from the graph below -
. -
- Why I am stressing on Precision?
- Because our goal is to reduce the False Postives, which means SMSs which are falsely predicted as SPAM, otherwise the user might miss on some important SMSs and maximizing precision will help us in minimizing false positive, which is evident from the formula of precision, for which you can refer this section
- Pipeline 1 gives best accuracy and decent precision
- Pipeline 3 gives best precision with zero false positives but screws up other scores.
- Why I am stressing on Precision?
-
Keeping all these things in mind, I have chosen pipeline1 which uses Naive Bayes Classifier and TF-IDF Word Vectorizer
-
The Final Classification Report for this pipleine is shown below -
- Google Colaboratory for providing the computational power to build and train the models.
- Heroku Cloud Platform for making the deployment of this project possible.
- #66daysofdata community created by KenJee that is keeping me accountable and consistent in my Data Science Journey.
| score | |
|---|---|
| accuracy | 99.01 |
| f1-score | 96.14 |
| precision | 98.56 |
| recall | 93.83 |
| roc auc score | 96.81 |
I humbly acknowledge that my NB model can be fooled easily, if we stuff our SMS with lots and lots of "hammy words" (meaning the words that generally doesn't appear in SPAM messages Wordcloud). Therefore, the Choice of words can easily fool our model
For more details you can have a look at my Ipython notebook for NLP Pipeline building.